soundstorm pytorch
0.5.0
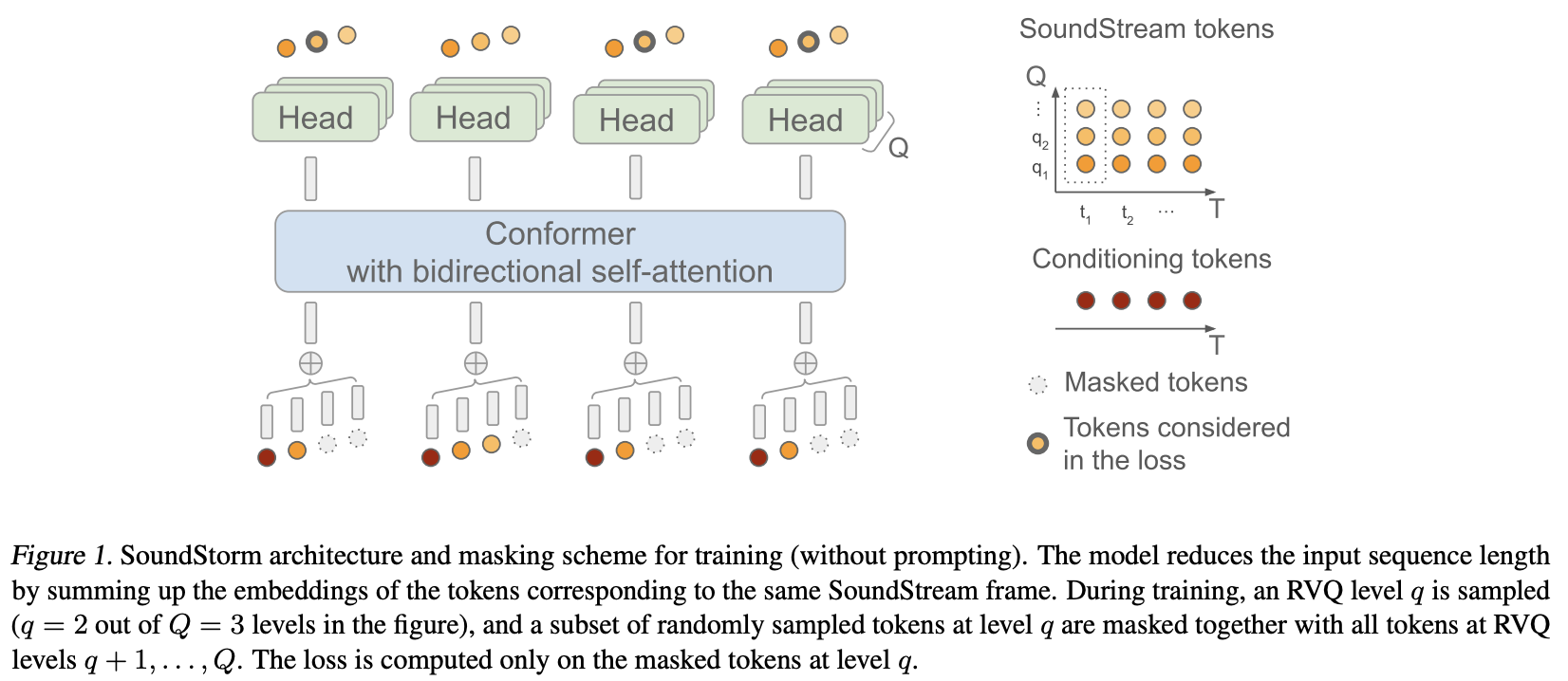
Implémentation de SoundStorm, Efficient Parallel Audio Generation de Google Deepmind, dans Pytorch.
Ils ont essentiellement appliqué MaskGiT aux codes quantifiés vectoriels résiduels de Soundstream. L'architecture de transformateur qu'ils ont choisi d'utiliser est celle qui correspond bien au domaine audio, nommée Conformer
Page du projet
Stabilité et ? Huggingface pour leurs généreux parrainages pour travailler sur des recherches de pointe en matière d'intelligence artificielle open source
Lucas Newman pour ses nombreuses contributions, notamment le code de formation initiale, la logique d'incitation acoustique et le décodage du quantificateur par niveau !
? Accelerate pour fournir une solution simple et puissante pour la formation
Einops pour l'abstraction indispensable qui rend la création de réseaux de neurones amusante, facile et inspirante
Steven Hillis pour avoir soumis la bonne stratégie de masquage et pour avoir vérifié que le référentiel fonctionne !
Lucas Newman pour avoir essentiellement formé un petit Soundstorm fonctionnel avec des modèles répartis dans plusieurs référentiels, montrant que tout fonctionne de bout en bout. Les modèles incluent SoundStream, Text-to-Semantic T5 et enfin le transformateur SoundStorm ici.
@Jiang-Stan pour avoir identifié un bug critique dans le démasquage itératif !
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024) Pour vous entraîner directement sur l'audio brut, vous devez transmettre votre SoundStream pré-entraîné dans SoundStorm . Vous pouvez entraîner votre propre SoundStream sur audiolm-pytorch.
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above) La synthèse vocale complète s'appuiera sur un transformateur d'encodeur/décodeur TextToSemantic formé. Vous chargerez ensuite les poids et les transmettrez dans SoundStorm sous le nom spear_tts_text_to_semantic
Il s'agit d'un travail en cours, car spear-tts-pytorch n'a que l'architecture du modèle complète, et non la logique de pré-entraînement + pseudo-étiquetage + rétro-traduction.
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream intégrer le flux sonore
lors de la génération, et la durée peut être définie en secondes (prend en compte la fréquence d'échantillonnage, etc.)
assurez-vous que les rvq groupés sont pris en charge. concaténer les intégrations plutôt que de les additionner dans la dimension du groupe
copiez simplement le conformateur et refaites l'intégration positionnelle relative de Shaw avec l'intégration rotative. plus personne n'utilise shaw.
attention flash par défaut sur vrai
supprimez batchnorm et utilisez simplement layernorm, mais après le swish (comme dans le papier normformer)
entraîneur avec accélération - merci à @lucasnewman
permettre un entraînement et une génération de séquences de longueur variable, en passant dans mask en forward et generate
option pour renvoyer la liste des fichiers audio lors de la génération
transformez-le en un outil de ligne de commande
ajouter une attention croisée et un conditionnement adaptatif des normes de couche
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

