rotary embedding torch
0.8.6
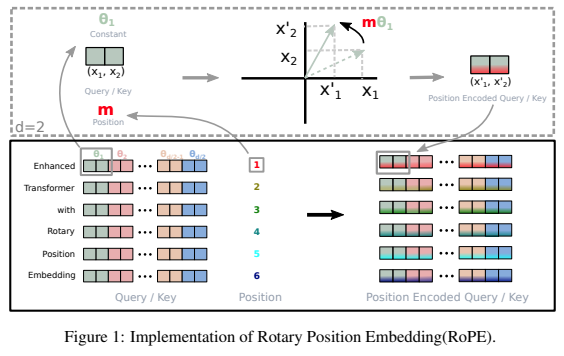
Une bibliothèque autonome pour ajouter des intégrations rotatives aux transformateurs dans Pytorch, suite à son succès en tant que codage positionnel relatif. Plus précisément, cela rendra la rotation des informations dans n'importe quel axe d'un tenseur facile et efficace, qu'elles soient de position fixe ou apprises. Cette bibliothèque vous fournira des résultats de pointe en matière d'intégration positionnelle, à moindre coût.
Mon instinct me dit également qu'il y a quelque chose de plus dans les rotations qui peuvent être exploitées dans les réseaux de neurones artificiels.
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usualSi vous suivez correctement toutes les étapes ci-dessus, vous devriez constater une amélioration spectaculaire pendant l’entraînement.
Lorsqu'il s'agit de caches clé/valeur lors de l'inférence, la position de la requête doit être décalée avec key_value_seq_length - query_seq_length
Pour faciliter cela, utilisez la méthode rotate_queries_with_cached_keys
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )Vous pouvez également le faire manuellement comme ceci
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])Pour une utilisation facile de l'intégration de position relative axiale à n dimensions, c'est-à-dire. transformateurs vidéo
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) Dans cet article, ils ont réussi à résoudre le problème d’extrapolation de longueur avec les intégrations rotatives en lui donnant une désintégration similaire à ALiBi. Ils ont nommé cette technique XPos, et vous pouvez l'utiliser en définissant use_xpos = True lors de l'initialisation.
Ceci ne peut être utilisé que pour les transformateurs autorégressifs
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )Cet article MetaAI propose simplement d'affiner les interpolations des positions de séquence pour s'étendre à une longueur de contexte plus longue pour les modèles pré-entraînés. Ils montrent que cela fonctionne bien mieux qu'un simple réglage fin sur les mêmes positions de séquence mais étendu davantage.
Vous pouvez l'utiliser en définissant interpolate_factor lors de l'initialisation sur une valeur supérieure à 1. (par exemple, si le modèle pré-entraîné a été formé sur 2048, définir interpolate_factor = 2. permettrait un réglage fin à 2048 x 2. = 4096 )
Mise à jour : quelqu'un dans la communauté a signalé que cela ne fonctionnait pas bien. veuillez m'envoyer un e-mail si vous voyez un résultat positif ou négatif
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

