point transformer pytorch
0.1.5
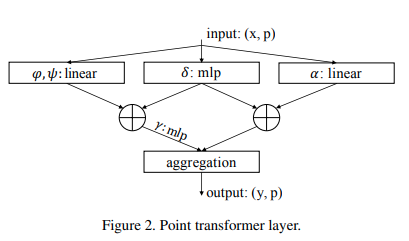
Implémentation de la couche d'auto-attention Point Transformer, dans Pytorch. Le circuit simple ci-dessus semble avoir permis à leur groupe de surpasser toutes les méthodes précédentes en matière de classification et de segmentation des nuages de points.
$ pip install point-transformer-pytorch import torch
from point_transformer_pytorch import PointTransformerLayer
attn = PointTransformerLayer (
dim = 128 ,
pos_mlp_hidden_dim = 64 ,
attn_mlp_hidden_mult = 4
)
feats = torch . randn ( 1 , 16 , 128 )
pos = torch . randn ( 1 , 16 , 3 )
mask = torch . ones ( 1 , 16 ). bool ()
attn ( feats , pos , mask = mask ) # (1, 16, 128)Ce type de vecteur d’attention est beaucoup plus coûteux que le traditionnel. Dans l’article, ils ont utilisé les k voisins les plus proches des points pour exclure l’attention sur les points éloignés. Vous pouvez faire la même chose avec un seul paramètre supplémentaire.
import torch
from point_transformer_pytorch import PointTransformerLayer
attn = PointTransformerLayer (
dim = 128 ,
pos_mlp_hidden_dim = 64 ,
attn_mlp_hidden_mult = 4 ,
num_neighbors = 16 # only the 16 nearest neighbors would be attended to for each point
)
feats = torch . randn ( 1 , 2048 , 128 )
pos = torch . randn ( 1 , 2048 , 3 )
mask = torch . ones ( 1 , 2048 ). bool ()
attn ( feats , pos , mask = mask ) # (1, 16, 128) @misc { zhao2020point ,
title = { Point Transformer } ,
author = { Hengshuang Zhao and Li Jiang and Jiaya Jia and Philip Torr and Vladlen Koltun } ,
year = { 2020 } ,
eprint = { 2012.09164 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

