audiolm pytorch
2.2.3
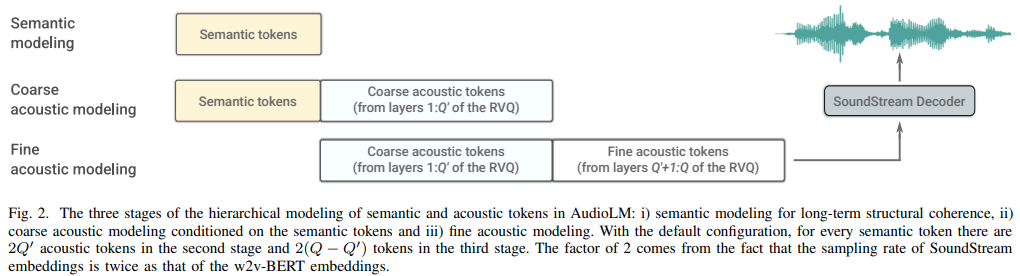
Implémentation d'AudioLM, une approche de modélisation linguistique pour la génération audio à partir de la recherche Google, dans Pytorch
Il étend également les travaux de conditionnement avec un guidage sans classificateur avec T5. Cela permet d'effectuer du texte vers audio ou du TTS, ce qui n'est pas proposé dans le journal. Oui, cela signifie que VALL-E peut être formé à partir de ce référentiel. C'est essentiellement la même chose.
Veuillez nous rejoindre si vous souhaitez reproduire ce travail à l'air libre
Ce référentiel contient désormais également une version sous licence MIT de SoundStream. Il est également compatible avec EnCodec, qui est également sous licence MIT au moment de la rédaction.
Mise à jour : AudioLM était essentiellement utilisé pour « résoudre » la génération de musique dans le nouveau MusicLM
Dans le futur, ce clip n’aurait plus aucun sens. Vous feriez simplement appel à une IA à la place.
Stability.ai pour son généreux parrainage en faveur du travail et de la recherche de pointe en intelligence artificielle open source
? Huggingface pour leurs incroyables bibliothèques d'accélérations et de transformateurs
MetaAI pour Fairseq et la licence libérale
@eonglints et Joseph pour avoir offert leurs conseils professionnels et leur expertise ainsi que leurs pull request !
@djqualia, @yigityu, @inspirit et @BlackFox1197 pour leur aide au débogage du flux sonore
Allen et LWprogramming pour avoir révisé le code et soumis des corrections de bugs !
Ilya pour avoir trouvé un problème avec le sous-échantillonnage du discriminateur multi-échelle et pour les améliorations apportées à l'entraîneur de flux sonore
Andrey pour avoir identifié une perte manquante dans le flux sonore et m'avoir guidé à travers les hyperparamètres appropriés du spectrogramme mel
Alejandro et Ilya pour avoir partagé leurs résultats avec le flux sonore de formation et pour avoir résolu quelques problèmes avec les intégrations de position d'attention locale
Programmation LW pour ajouter la compatibilité Encodec !
LWprogramming pour trouver un problème avec la gestion du jeton EOS lors de l'échantillonnage à partir du FineTransformer !
@YoungloLee pour avoir identifié un gros bug dans la convolution causale 1D du flux sonore lié au rembourrage ne tenant pas compte des foulées !
Hayden pour avoir souligné certaines divergences dans le discriminateur multi-échelle pour Soundstream
$ pip install audiolm-pytorchIl existe deux options pour le codec neuronal. Si vous souhaitez utiliser l'Encodec 24 kHz pré-entraîné, créez simplement un objet Encodec comme suit :
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. Sinon, pour rester plus fidèle au papier original, vous pouvez utiliser SoundStream . Premièrement, SoundStream doit être formé sur un vaste corpus de données audio.
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel Votre SoundStream formé peut ensuite être utilisé comme tokenizer générique pour l'audio.
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) Vous pouvez également utiliser des flux sonores spécifiques à AudioLM et MusicLM en important respectivement AudioLMSoundStream et MusicLMSoundStream
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above Depuis la version 0.17.0 , vous pouvez désormais appeler la méthode de classe sur SoundStream pour charger à partir de fichiers de point de contrôle, sans avoir à mémoriser vos configurations.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) Pour utiliser le suivi des poids et des biais, définissez d'abord use_wandb_tracking = True sur le SoundStreamTrainer , puis procédez comme suit
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () Ensuite, trois transformateurs distincts ( SemanticTransformer , CoarseTransformer , FineTransformer ) doivent être formés
ex. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () ex. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () ex. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()Tous ensemble maintenant
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])Mise à jour : on dirait que cela fonctionnera, étant donné « VALL-E »
ex. Transformateur sémantique
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] Parce que toutes les classes de formateurs utilisent ? Accélérateur, vous pouvez facilement effectuer une formation multi-GPU en utilisant la commande accelerate ainsi
A la racine du projet
$ accelerate configPuis, dans le même répertoire
$ accelerate launch train . py transformateur grossier complet
utilisez fairseq vq-wav2vec pour les intégrations
ajouter du conditionnement
ajouter des conseils gratuits pour le classificateur
ajouter un consécutif unique pour
incorporer la possibilité d'utiliser les fonctionnalités intermédiaires d'Hubert comme jetons sémantiques, recommandé par eonglints
accueillir un son de longueur variable, apporter un jeton eos
assurez-vous que des travaux consécutifs uniques avec un transformateur grossier
jolie impression de toutes les pertes du discriminateur pour enregistrer
gérer lors de la génération de jetons sémantiques, que les derniers logits ne sont pas nécessairement les derniers de la séquence étant donné un traitement consécutif unique
code d'échantillonnage complet pour les transformateurs grossiers et fins, ce qui sera délicat
assurez-vous que l'inférence complète avec ou sans invite fonctionne sur la classe AudioLM
compléter le code de formation complet pour le flux sonore, en prenant soin de la formation des discriminateurs
ajouter une pénalité de gradient efficace pour les discriminateurs pour le flux sonore
câblez l'échantillon Hz à partir de l'ensemble de données sonores -> transformateurs, et effectuez un rééchantillonnage approprié pendant la formation - réfléchissez à l'opportunité d'autoriser l'ensemble de données à avoir des fichiers sonores variables ou d'appliquer le même échantillon Hz
code complet de formation des transformateurs pour les trois transformateurs
refactoriser pour que le transformateur sémantique ait un wrapper qui gère les consécutives uniques ainsi que wav vers hubert ou vq-wav2vec
ne s'occupe tout simplement pas du jeton eos du côté de l'invite (sémantique pour le transformateur grossier, grossier pour le transformateur fin)
ajouter un abandon structuré dû au masquage causal oublieux, bien meilleur que les abandons traditionnels
comprendre comment supprimer la connexion dans fairseq
affirmer que les trois transformateurs passés dans audiolm sont compatibles
permettre des intégrations de position relative spécialisées dans un transformateur fin basées sur des positions de correspondance absolue des quantificateurs entre grossier et fin
autoriser le vq résiduel groupé dans le flux sonore (utilisez GroupedResidualVQ de la bibliothèque vector-quantize-pytorch), à partir du codec hifi
ajouter une attention flash avec NoPE
accepter l'onde principale dans AudioLM comme chemin d'accès à un fichier audio et rééchantillonner automatiquement pour la sémantique par rapport à l'acoustique
ajouter une mise en cache clé/valeur à tous les transformateurs, accélérant l'inférence
concevoir un transformateur hiérarchique grossier et fin
enquêter sur le décodage des spécifications, tester d'abord dans les transformateurs X, puis transférer le cas échéant
refaire les plongements positionnels en présence de groupes dans vq résiduel
test avec synthèse vocale pour débutants
outil cli, quelque chose comme audiolm generate <wav.file | text> et enregistrez le fichier wav généré dans le répertoire local
renvoie une liste d'ondes dans le cas d'un son de longueur variable
prenez simplement soin du cas limite dans la formation conditionnée par le texte du transformateur grossier, où l'onde brute est rééchantillonnée à différentes fréquences. déterminer automatiquement comment tracer un itinéraire en fonction de la longueur
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

