routing transformer
1.6.1
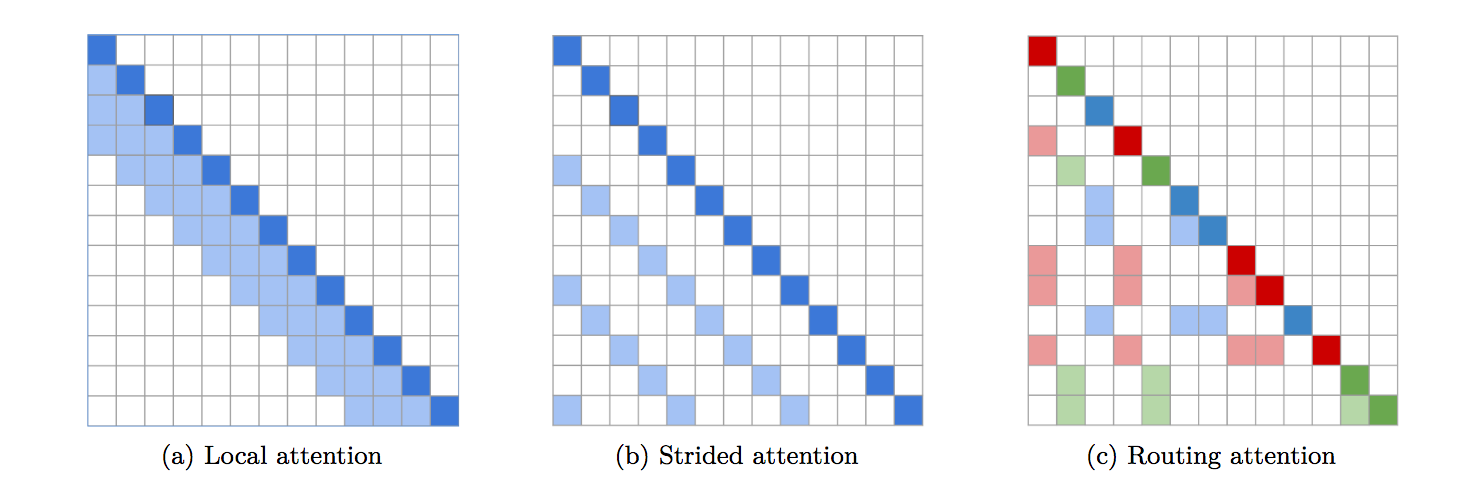
Une implémentation complète de Routing Transformer. L'article propose d'utiliser des k-means pour acheminer des requêtes/clés similaires vers le même cluster pour attirer l'attention.
131 000 jetons
$ pip install routing_transformerUn modèle de langage simple
import torch
from routing_transformer import RoutingTransformerLM
model = RoutingTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
causal = True , # auto-regressive or not
emb_dim = 128 , # embedding factorization, from Albert
weight_tie = False , # weight tie layers, from Albert
tie_embedding = False , # multiply final embeddings with token weights for logits
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
attn_dropout = 0.1 , # dropout after attention
attn_layer_dropout = 0. , # dropout after self attention layer
ff_dropout = 0.1 , # feedforward dropout
layer_dropout = 0. , # layer dropout
window_size = 128 , # target window size of each cluster
n_local_attn_heads = 4 , # number of local attention heads
reversible = True , # reversible networks for memory savings, from Reformer paper
ff_chunks = 10 , # feed forward chunking, from Reformer paper
ff_glu = True , # use GLU variant in feedforward
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
moe_layers = ( 3 , 6 ), # specify which layers to use mixture of experts
moe_num_experts = 4 , # number of experts in the mixture of experts layer, defaults to 4. increase for adding more parameters to model
moe_loss_coef = 1e-2 , # the weight for the auxiliary loss in mixture of experts to keep expert usage balanced
num_mem_kv = 8 , # number of memory key/values to append to each cluster of each head, from the 'All-Attention' paper. defaults to 1 in the causal case for unshared QK to work
use_scale_norm = False , # use scale norm, simplified normalization from 'Transformers without Tears' paper
use_rezero = False , # use Rezero with no normalization
shift_tokens = True # shift tokens by one along sequence dimension, for a slight improvement in convergence
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , 8192 )). long (). cuda ()
input_mask = torch . ones_like ( x ). bool (). cuda ()
y , aux_loss = model ( x , input_mask = input_mask ) # (1, 8192, 20000)
aux_loss . backward () # add auxiliary loss to main loss before backpropUn simple transformateur
import torch
from routing_transformer import RoutingTransformer
model = RoutingTransformer (
dim = 512 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
window_size = 128 ,
n_local_attn_heads = 4
). cuda ()
x = torch . randn ( 1 , 8192 , 512 ). cuda ()
input_mask = torch . ones ( 1 , 8192 ). bool (). cuda ()
y , aux_loss = model ( x , input_mask = input_mask ) # (1, 8192, 512)
aux_loss . backward () # add auxiliary loss to main loss before backprop Pour utiliser un encodeur ou un décodeur complet, importez simplement la classe RoutingTransformerEncDec . À l'exception du mot-clé dim , tous les autres mots-clés seront précédés de enc_ ou dec_ pour la classe RoutingTransformerLM de l'encodeur et du décodeur respectivement.
import torch
from routing_transformer import RoutingTransformerEncDec
model = RoutingTransformerEncDec (
dim = 512 ,
enc_num_tokens = 20000 ,
enc_depth = 4 ,
enc_heads = 8 ,
enc_max_seq_len = 4096 ,
enc_window_size = 128 ,
dec_num_tokens = 20000 ,
dec_depth = 4 ,
dec_heads = 8 ,
dec_max_seq_len = 4096 ,
dec_window_size = 128 ,
dec_reversible = True
). cuda ()
src = torch . randint ( 0 , 20000 , ( 1 , 4096 )). cuda ()
tgt = torch . randint ( 0 , 20000 , ( 1 , 4096 )). cuda ()
src_mask = torch . ones_like ( src ). bool (). cuda ()
tgt_mask = torch . ones_like ( tgt ). bool (). cuda ()
loss , aux_loss = model ( src , tgt , enc_input_mask = src_mask , dec_input_mask = tgt_mask , return_loss = True , randomly_truncate_sequence = True )
loss . backward ()
aux_loss . backward ()
# do your training, then to sample up to 2048 tokens based on the source sequence
src = torch . randint ( 0 , 20000 , ( 1 , 4096 )). cuda ()
start_tokens = torch . ones ( 1 , 1 ). long (). cuda () # assume starting token is 1
sample = model . generate ( src , start_tokens , seq_len = 2048 , eos_token = 2 ) # (1, <= 2048, 20000) Pour voir les avantages de l'utilisation de PKM, le taux d'apprentissage des valeurs doit être défini à un niveau supérieur au reste des paramètres. (Recommandé pour être 1e-2 )
Vous pouvez suivre les instructions ici pour le configurer correctement https://github.com/lucidrains/product-key-memory#learning-rates
kmeans_ema_decay = {defaults to 0.999}Il s’agit de la décroissance exponentielle de la moyenne mobile pour mettre à jour les k-moyennes. Plus celui-ci est faible, plus les moyens s’ajusteront rapidement, mais au détriment de la stabilité.
commitment_factor = {defaults to 1e-4}Le poids de la perte auxiliaire qui encourage les jetons à se rapprocher (s'engager) des centroïdes k-moyens qui ont été choisis pour eux.
Les instructions suivantes vous permettront de mettre à jour les kmeans manuellement. Par défaut, les kmeans sont mis à jour automatiquement à chaque passage en arrière.
import torch
from routing_transformer import RoutingTransformerLM , AutoregressiveWrapper
model = RoutingTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 6 ,
window_size = 256 ,
max_seq_len = 8192 ,
causal = True ,
_register_kmeans_update = False # set to False to disable auto-updating
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True )
loss . backward ()
# update kmeans with this call
model . update_kmeans ()Cette architecture a du mal à se généraliser à des longueurs de séquence plus courtes lors du décodage des jetons de 1 -> longueur de séquence maximale. La solution la plus simple et la plus sûre consiste à tronquer aléatoirement la séquence lors de l’entraînement. Cela aide le réseau et les moyens à se généraliser à un nombre variable de jetons, au prix d'une formation prolongée.
Si vous amorcez le réseau avec la longueur complète de la séquence au démarrage, vous ne rencontrerez pas ce problème et vous pourrez ignorer cette procédure de formation.
import torch
from routing_transformer import RoutingTransformerLM , AutoregressiveWrapper
model = RoutingTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
window_size = 256 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000) Un merci spécial à Aran Komatsuzaki pour avoir démarré l'implémentation initiale dans Pytorch qui a évolué vers cette bibliothèque.
@misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://arxiv.org/pdf/2003.05997.pdf }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @article { DBLP:journals/corr/abs-1907-01470 ,
author = { Sainbayar Sukhbaatar and
Edouard Grave and
Guillaume Lample and
Herv{'{e}} J{'{e}}gou and
Armand Joulin } ,
title = { Augmenting Self-attention with Persistent Memory } ,
journal = { CoRR } ,
volume = { abs/1907.01470 } ,
year = { 2019 } ,
url = { http://arxiv.org/abs/1907.01470 }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
} @article { 1910.05895 ,
author = { Toan Q. Nguyen and Julian Salazar } ,
title = { Transformers without Tears: Improving the Normalization of Self-Attention } ,
year = { 2019 } ,
eprint = { arXiv:1910.05895 } ,
doi = { 10.5281/zenodo.3525484 } ,
} @misc { bachlechner2020rezero ,
title = { ReZero is All You Need: Fast Convergence at Large Depth } ,
author = { Thomas Bachlechner and Bodhisattwa Prasad Majumder and Huanru Henry Mao and Garrison W. Cottrell and Julian McAuley } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2003.04887 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
}

