CoLT5 attention
0.11.1
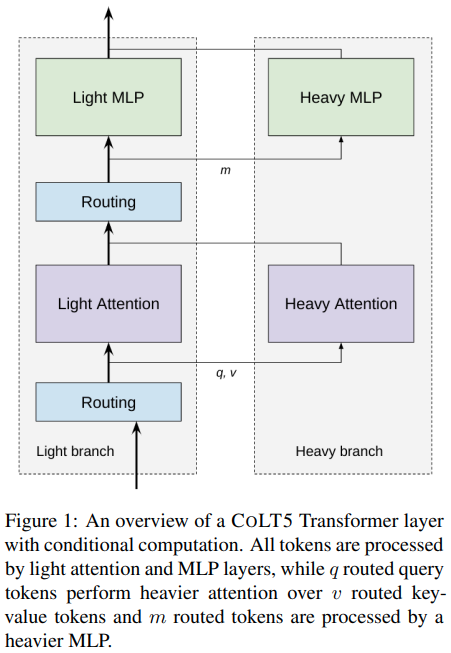
Implémentation de l'attention efficace acheminée sous condition dans l'architecture CoLT5 proposée, dans Pytorch.
Ils ont utilisé la descente de coordonnées de cet article (algorithme principal originaire de Wright et al) pour acheminer un sous-ensemble de jetons pour les branches « plus lourdes » des blocs de rétroaction et d'attention.
Mise à jour : je ne suis pas sûr de la façon dont les scores normalisés de routage pour les valeurs-clés sont utilisés. J'ai improvisé là-bas, en mettant à l'échelle les valeurs projetées, mais si vous pensez connaître la réponse, veuillez ouvrir un problème
Mise à jour 2 : semble bien fonctionner avec l'improvisation ci-dessus
Stability.ai pour son généreux parrainage visant à mener des recherches de pointe sur l'intelligence artificielle
einops pour m'avoir rendu la vie facile
Triton pour m'avoir permis d'accélérer la descente des coordonnées avec une implémentation fusionnée en seulement 2 jours, m'épargnant ainsi d'avoir à écrire mille lignes de code CUDA
$ pip install colt5-attention import torch
from colt5_attention import (
ConditionalRoutedFeedForward ,
ConditionalRoutedAttention ,
ConditionalRoutedTransformerBlock
)
# mock input, say it is 32768 length
tokens = torch . randn ( 2 , 32768 , 512 )
mask = torch . ones ( 2 , 32768 ). bool () # can handle variable lengthed sequences
# feedforward
ff = ConditionalRoutedFeedForward (
dim = 512 ,
light_ff_mult = 0.5 , # hidden dimension ratio of light branch
heavy_ff_mult = 4 , # hidden dimension ratio of heavy branch
num_heavy_tokens = 1024 # heavy branch receives only 1024 routed tokens of 32768
)
ff_out = ff ( tokens , mask = mask ) # (2, 32768, 512) - light and heavy branch summed
# attention
attn = ConditionalRoutedAttention (
dim = 512 ,
light_dim_head = 64 , # attention head dimension of light branch
light_heads = 8 , # number of attention heads for light branch
light_window_size = 128 , # local attention receptive field for light
heavy_dim_head = 64 , # attention head dimension of heavy branch
heavy_heads = 8 , # number of attention heads for heavy branch
num_heavy_tokens_q = 1024 , # heavy branch receives only 1024 routed tokens of 32768
num_heavy_tokens_kv = 1024 # heavy branch receives only 1024 routed tokens of 32768
)
attn_out = attn ( tokens , mask = mask ) # (2, 32768, 512) - light and heavy branch summed
# both attention and feedforward with residual
# the complete transformer block
# a stack of these would constitute the encoder of CoLT5
block = ConditionalRoutedTransformerBlock (
dim = 512 ,
light_dim_head = 64 ,
light_heads = 8 ,
light_window_size = 128 ,
heavy_dim_head = 64 ,
heavy_heads = 8 ,
light_ff_mult = 0.5 ,
heavy_ff_mult = 4 ,
num_heavy_ff_tokens = 1024 ,
num_heavy_attn_tokens_q = 1024 ,
num_heavy_attn_tokens_kv = 1024
)
block_out = block ( tokens , mask = mask ) # (2, 32768, 512)Inclus également une variante de l'attention acheminée conditionnellement pour l'attention croisée, à essayer avec de longues mémoires de contexte dans un transformateur-xl
import torch
from colt5_attention import ConditionalRoutedCrossAttention
# mock input, let us say it is a transformer of 1024 length attending to 1 million context past memories
tokens = torch . randn ( 1 , 1024 , 512 ). cuda ()
tokens_mask = torch . ones ( 1 , 1024 ). bool (). cuda ()
memories = torch . randn ( 1 , 1_048_576 , 512 ). cuda ()
memories_mask = torch . ones ( 1 , 1_048_576 ). bool (). cuda ()
# conditionally routed cross attention
cross_attn = ConditionalRoutedCrossAttention (
dim = 512 ,
dim_head = 64 ,
heads = 8 ,
num_tokens_q = 512 , # only 512 routed from 1024
num_tokens_kv = 1024 , # only 1024 routed from 1 million
kv_routing_tokens = 2 , # say you want 2 routing tokens to route different sets of key / values to the queries. 4 attention heads will be allocated to each routed set in this example (8 / 2)
use_triton = True , # use cuda kernel
route_block_size = 131072 # route in blocks of 131072
). cuda ()
cross_attn_out = cross_attn (
tokens ,
context = memories ,
mask = tokens_mask ,
context_mask = memories_mask
)
cross_attn_out . shape # (1, 1024, 512) - same as tokensCe référentiel dispose également d'une version improvisée pour une attention autorégressive. Pour y parvenir, la séquence a été visualisée dans Windows. Chaque fenêtre ne peut s'occuper que des fenêtres de clés/valeurs dans le passé. L’attention locale de la branche lumineuse couvre l’attention intra-fenêtre.
La descente de coordonnées est rendue viable grâce à un noyau CUDA écrit en Triton. Enfin, pour que la génération autorégressive fonctionne bien, j'ai dû m'assurer que les jetons non routés (pour les requêtes) génèrent une intégration de sortie apprise plutôt que de simples zéros.
Actuellement, je constate des différences occasionnelles entre les gradients (jusqu'à 1e-1 pour une très petite fraction d'éléments) une fois que le nombre d'itérations dépasse 20. Cependant, enwik8 semble bien s'entraîner et je peux voir les effets du routage. La formation est également étonnamment stable
ex.
import torch
from colt5_attention import ConditionalRoutedAutoregressiveAttention
# mock input, say it is 8192 length
tokens = torch . randn ( 2 , 8192 , 512 ). cuda ()
# attention
attn = ConditionalRoutedAutoregressiveAttention (
dim = 512 ,
light_dim_head = 64 , # attention head dimension of light branch
light_heads = 8 , # number of attention heads for light branch
light_window_size = 128 , # local attention receptive field for light
heavy_window_size = 128 , # the windowing for the routed heavy attention, by default, will be equal to the light window size. be aware if this is any greater than the light window size, there may be tokens that would be missed by attention
heavy_dim_head = 64 , # attention head dimension of heavy branch
heavy_heads = 8 , # number of attention heads for heavy branch
num_heavy_tokens_q = 32 , # heavy branch receives only 32 out of 128 of the windowed queries (1024 query tokens total)
num_heavy_tokens_kv = 1024 , # heavy branch receives only 1024 routed tokens for key-values
num_routed_kv = 2 , # one can split the attention heads so that groups of heads attend to different sets of key - values (2 routing tokens in this case)
use_triton = True , # will need to use Triton for this to be viable, otherwise it is too slow and memory efficient with the number of iterations
use_flash_attn = True # use flash attention in heavy branch
). cuda ()
attn_out = attn ( tokens ) + tokens # (2, 8192, 512) - output of attention with residual (prenorm is included)Enfin, ce référentiel contient une version pour les cartes de caractéristiques d'image. En règle générale, de nombreux documents de recherche ne peuvent pas prêter attention aux cartes de caractéristiques d'image dont les dimensions sont supérieures à 32 x 32. Cette attention redirigée utilisera un patch de fenêtre local pour la branche légère et une attention redirigée pour la branche lourde.
ex.
import torch
from colt5_attention import ConditionalRoutedImageAttention
attn = ConditionalRoutedImageAttention (
dim = 32 ,
light_dim_head = 64 , # attention head dimension of light branch
light_heads = 8 , # number of attention heads for light branch
light_window_size = 32 , # height and width of local window attention on the image feature map
channel_first = True , # whether to accept images with channel first than last
heavy_dim_head = 64 , # attention head dimension of heavy branch
heavy_heads = 8 , # number of attention heads for heavy branch
num_heavy_tokens_q = 1024 , # heavy branch receives only 1024 routed tokens of 65536
num_heavy_tokens_kv = 1024 # heavy branch receives only 1024 routed tokens of 65536
). cuda ()
fmap = torch . randn ( 1 , 32 , 256 , 256 ). cuda () # image feature map is too large for attention, given 256 ^ 2 == 65536 tokens
out = attn ( fmap )ViT simple utilisant la descente de coordonnées, l'attention acheminée et la rétroaction
import torch
from colt5_attention . vit import ConditionalRoutedViT
vit = ConditionalRoutedViT (
image_size = 256 , # image size
patch_size = 32 , # patch size
num_classes = 1000 , # number of output classes
dim = 1024 , # feature dimension
depth = 6 , # depth
attn_num_heavy_tokens_q = 16 , # number of routed queries for heavy attention
attn_num_heavy_tokens_kv = 16 , # number of routed key/values for heavy attention
attn_heavy_dim_head = 64 , # dimension per attention head for heavy
attn_heavy_heads = 8 , # number of attention heads for heavy
attn_light_window_size = 4 , # the local windowed attention for light branch
attn_light_dim_head = 32 , # dimension per head for local light attention
attn_light_heads = 4 , # number of attention heads for local windowed attention
ff_num_heavy_tokens = 16 , # number of tokens routed for heavy feedforward
ff_heavy_mult = 4 , # the expansion factor of the heavy feedforward branch
ff_light_mult = 2 # expansion factor of the light feedforward branch
)
images = torch . randn ( 1 , 3 , 256 , 256 )
logits = vit ( images ) # (1, 1000) Utilisez un petit emballage autour de la descente coordonnée pour topk différentiable
import torch
from colt5_attention import topk
x = torch . randn ( 1024 , 512 )
values , indices , coor_descent_values , gates = topk ( x , k = 10 , fused = True )
# you can either use the topk indices + gates, or use the values directly (values have already been multiplied with the gates within the function) @inproceedings { Ainslie2023CoLT5FL ,
title = { CoLT5: Faster Long-Range Transformers with Conditional Computation } ,
author = { Joshua Ainslie and Tao Lei and Michiel de Jong and Santiago Ontan'on and Siddhartha Brahma and Yury Zemlyanskiy and David Uthus and Mandy Guo and James Lee-Thorp and Yi Tay and Yun-Hsuan Sung and Sumit Sanghai } ,
year = { 2023 }
} @article { Tillet2019TritonAI ,
title = { Triton: an intermediate language and compiler for tiled neural network computations } ,
author = { Philippe Tillet and H. Kung and D. Cox } ,
journal = { Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages } ,
year = { 2019 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Lei2023ConditionalAP ,
title = { Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference } ,
author = { Tao Lei and Junwen Bai and Siddhartha Brahma and Joshua Ainslie and Kenton Lee and Yanqi Zhou and Nan Du and Vincent Zhao and Yuexin Wu and Bo Li and Yu Zhang and Ming-Wei Chang } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2304.04947 }
} @article { Beyer2022BetterPV ,
title = { Better plain ViT baselines for ImageNet-1k } ,
author = { Lucas Beyer and Xiaohua Zhai and Alexander Kolesnikov } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2205.01580 }
}

