datmo
1.0.0

| Système d'exploitation | Test CI sur master |
|---|---|
Datmo est un outil open source de gestion de modèles de production destiné aux data scientists. Utilisez datmo init pour transformer n'importe quel référentiel en un enregistrement d'expérience traçable. Synchronisez en utilisant votre propre cloud.
Remarque : La version actuelle de Datmo est une version alpha. Cela signifie que les commandes sont susceptibles de changer et que davantage de fonctionnalités seront ajoutées. Si vous trouvez des bugs, n'hésitez pas à contribuer en ajoutant des problèmes afin que les contributeurs puissent les résoudre.
Configuration d'un environnement de commande (langages, frameworks, packages, etc.)
Suivi et journalisation de la configuration et des résultats du modèle
Gestion des versions du projet (suivi de l'état du modèle)
Reproductibilité des expériences (tâches réexécutées)
Visualiser + exporter l'historique des expériences
(à venir) Tableaux de bord pour visualiser les expériences
| Fonctionnalité | Commandes |
|---|---|
| Initialisation d'un projet | $ datmo init |
| Configurer un nouvel environnement | $ datmo environment setup |
| Exécuter une expérience | $ datmo run "python filename.py" |
| Reproduire une expérience précédente | $ datmo ls (Trouver l'ID souhaité)$ datmo rerun EXPERIMENT_ID |
| Ouvrir un espace de travail | $ datmo notebook (Jupyter Notebook)$ datmo jupyterlab (JupyterLab)$ datmo rstudio (RStudio)$ datmo terminal (Terminal) |
| Enregistrez l'état de votre projet (Fichiers, code, environnement, configuration, statistiques) | $ datmo snapshot create -m "My first snapshot!" |
| Passer à un état de projet précédent | $ datmo snapshot ls (Trouver l'ID souhaité)$ datmo snapshot checkout SNAPSHOT_ID |
| Visualiser les entités du projet | $ datmo ls (Expériences)$ datmo snapshot ls (Instantanés)$ datmo environment ls (Environnements) |
Exigences
Installation
Bonjour le monde
Exemples
Documentation
Transformer un projet en cours
Partage
Contribuer à Datmo
docker (installé et exécuté avant de démarrer) : Instructions pour Ubuntu, MacOS, Windows
$ pip install datmo
Notre guide Hello World comprend l'affichage de la configuration et des modifications de l'environnement, ainsi que la reproductibilité des expériences. Il est disponible dans nos documents ici.
Dans le dossier /examples , nous avons quelques scripts que vous pouvez exécuter pour avoir une idée de Datmo. Vous pouvez accéder à Exemples pour en savoir plus sur la façon dont vous pouvez exécuter les exemples et démarrer vos propres projets.
Pour des didacticiels plus avancés, consultez notre référentiel de didacticiels dédié ici.
La configuration d’un environnement est extrêmement simple dans Datmo. Répondez simplement par y lorsque vous êtes interrogé sur la configuration de l'environnement lors de l'initialisation, ou utilisez datmo environment setup à tout moment. Suivez ensuite les invites qui en résultent.
Un exemple est présenté ci-dessous, pour configurer un TensorFlow Python 2.7 avec des exigences/pilotes CPU. 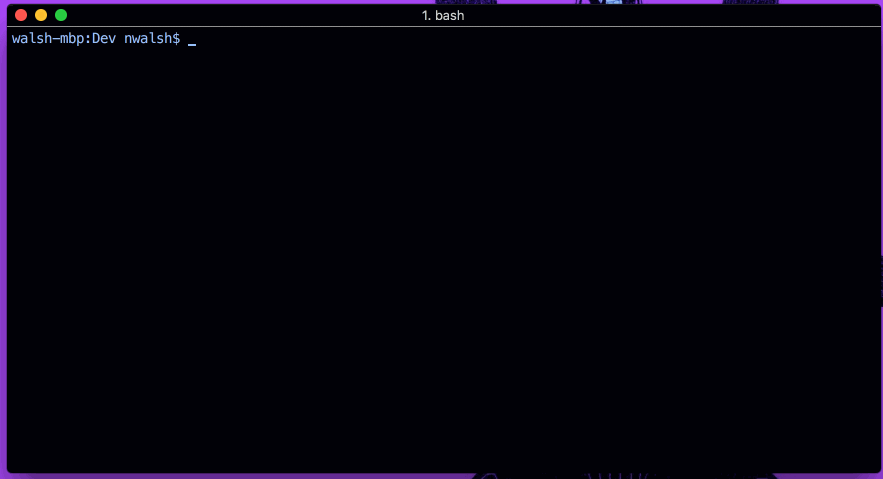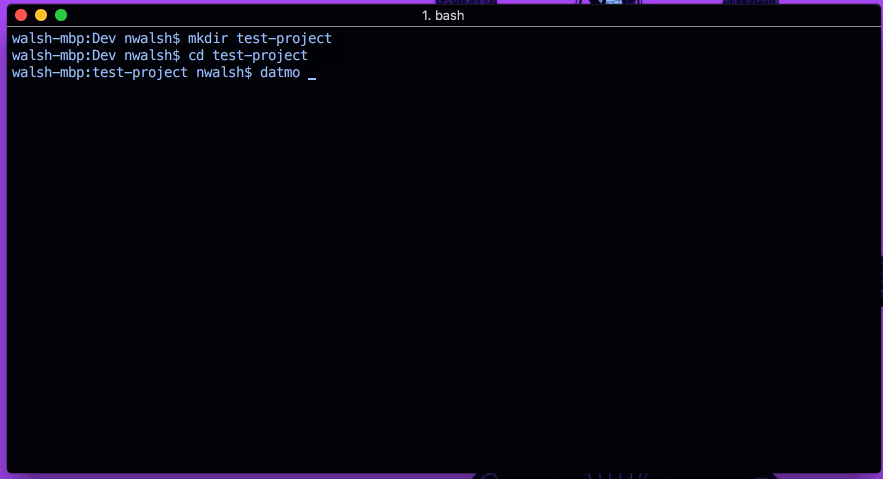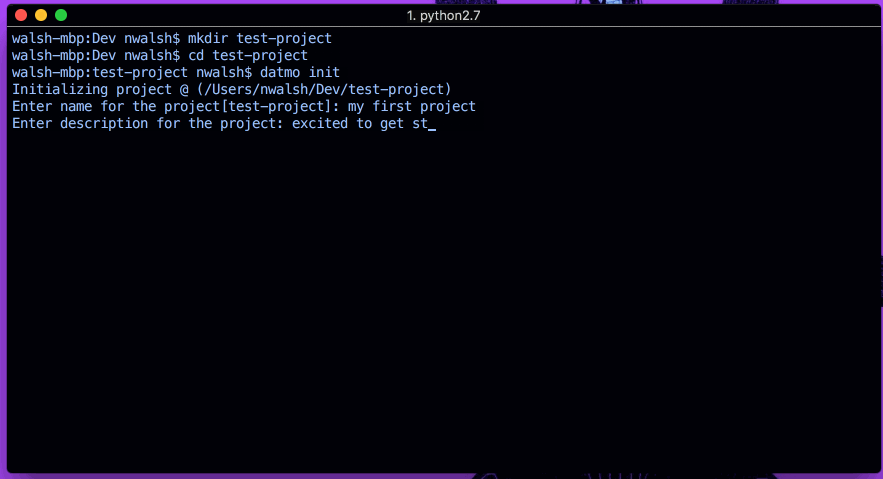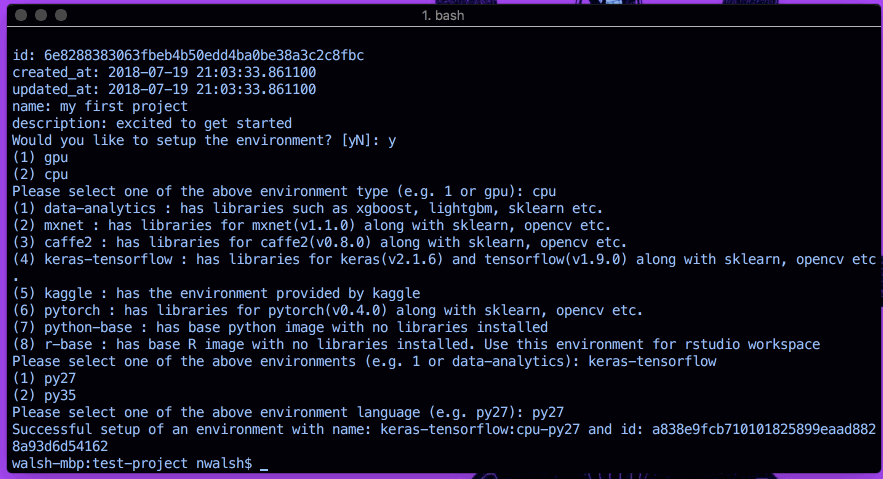
Pour le guide complet sur la configuration de votre environnement avec datmo, consultez cette page dans notre documentation ici.
Après avoir configuré votre environnement, la plupart des data scientists souhaitent ouvrir ce que nous appelons un espace de travail (environnement de programmation IDE ou Notebook).
Un exemple est présenté ci-dessous, pour ouvrir rapidement un bloc-notes Jupyter et montrer l'importation de TensorFlow fonctionnant comme prévu. 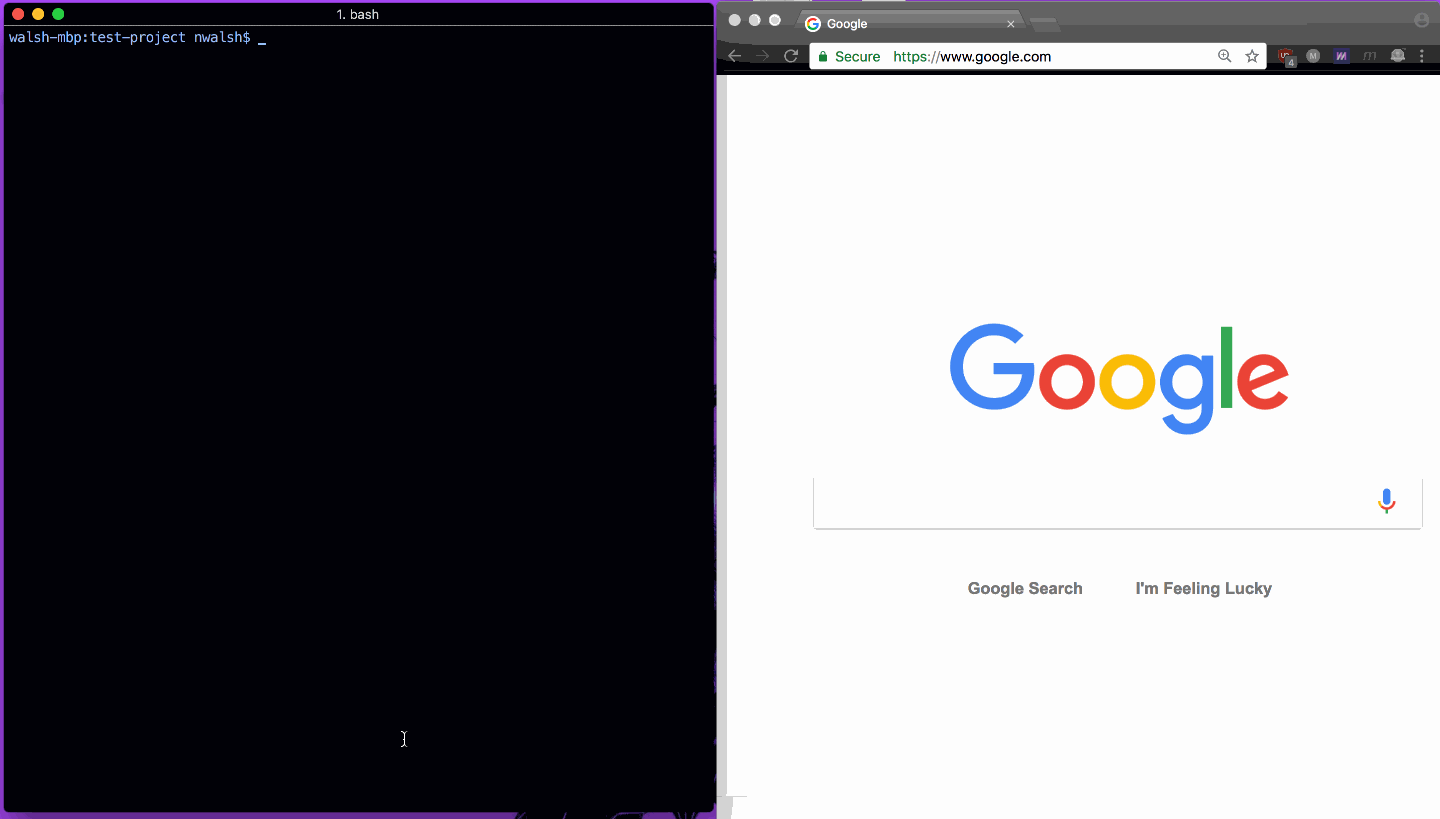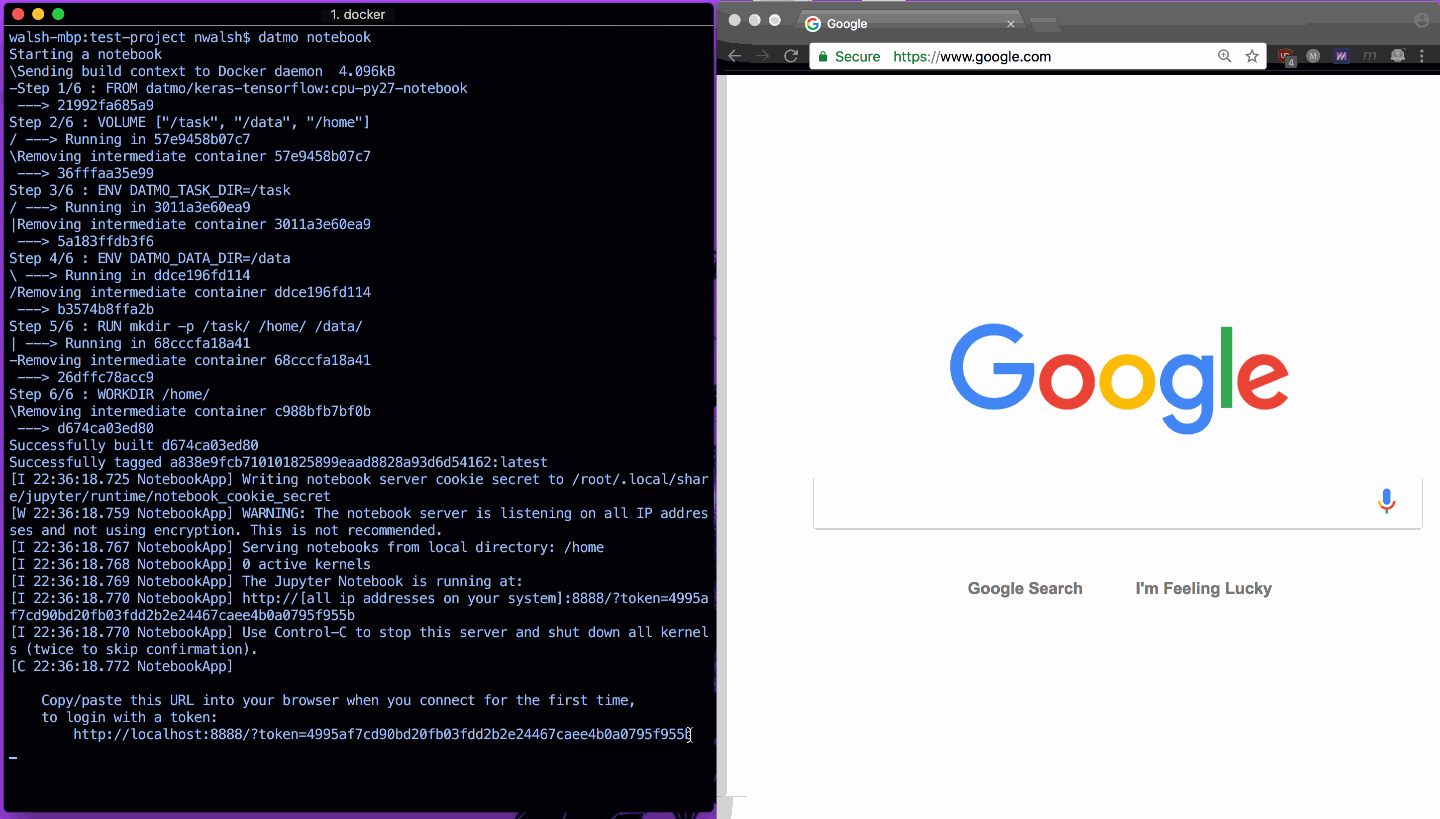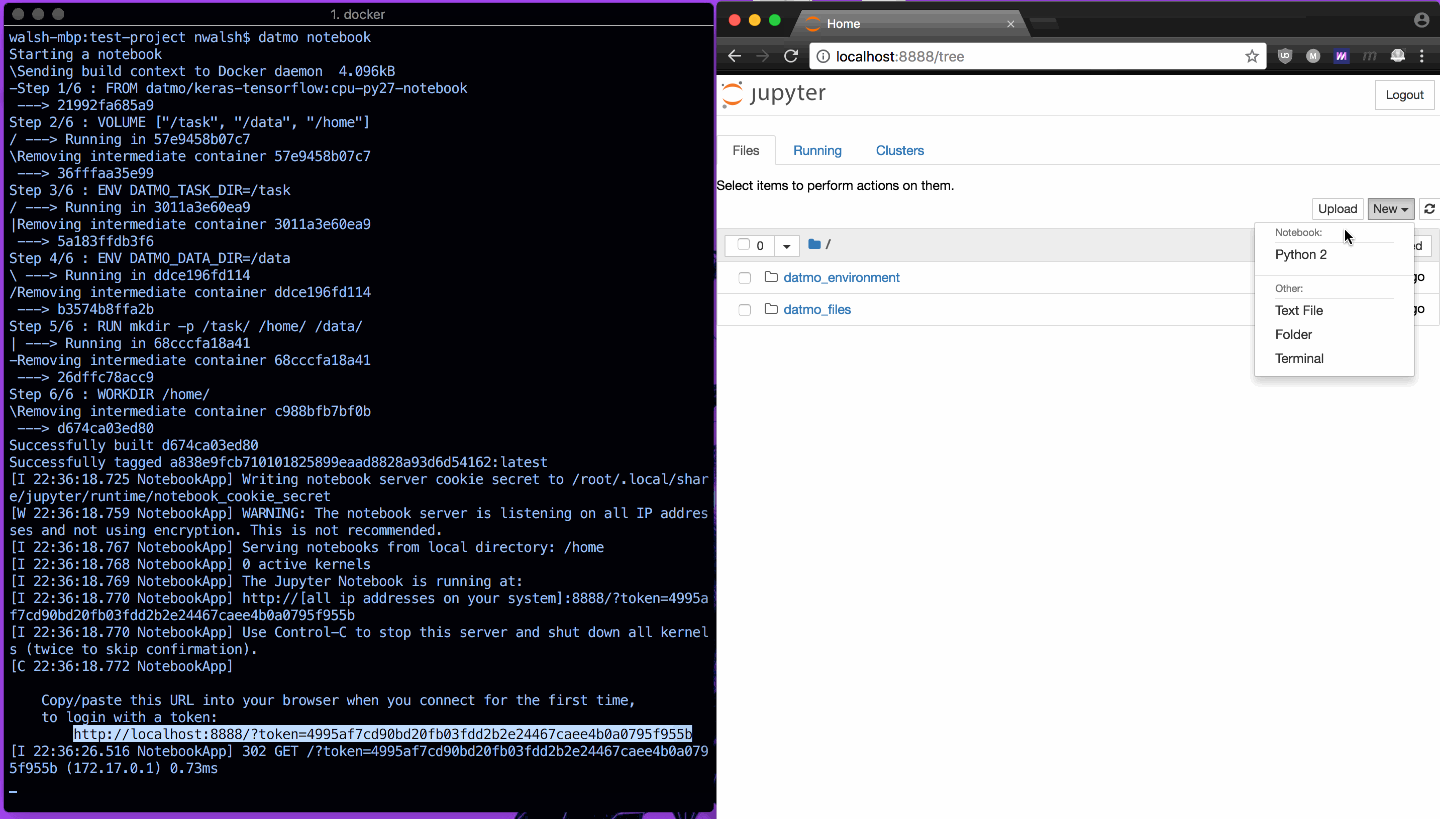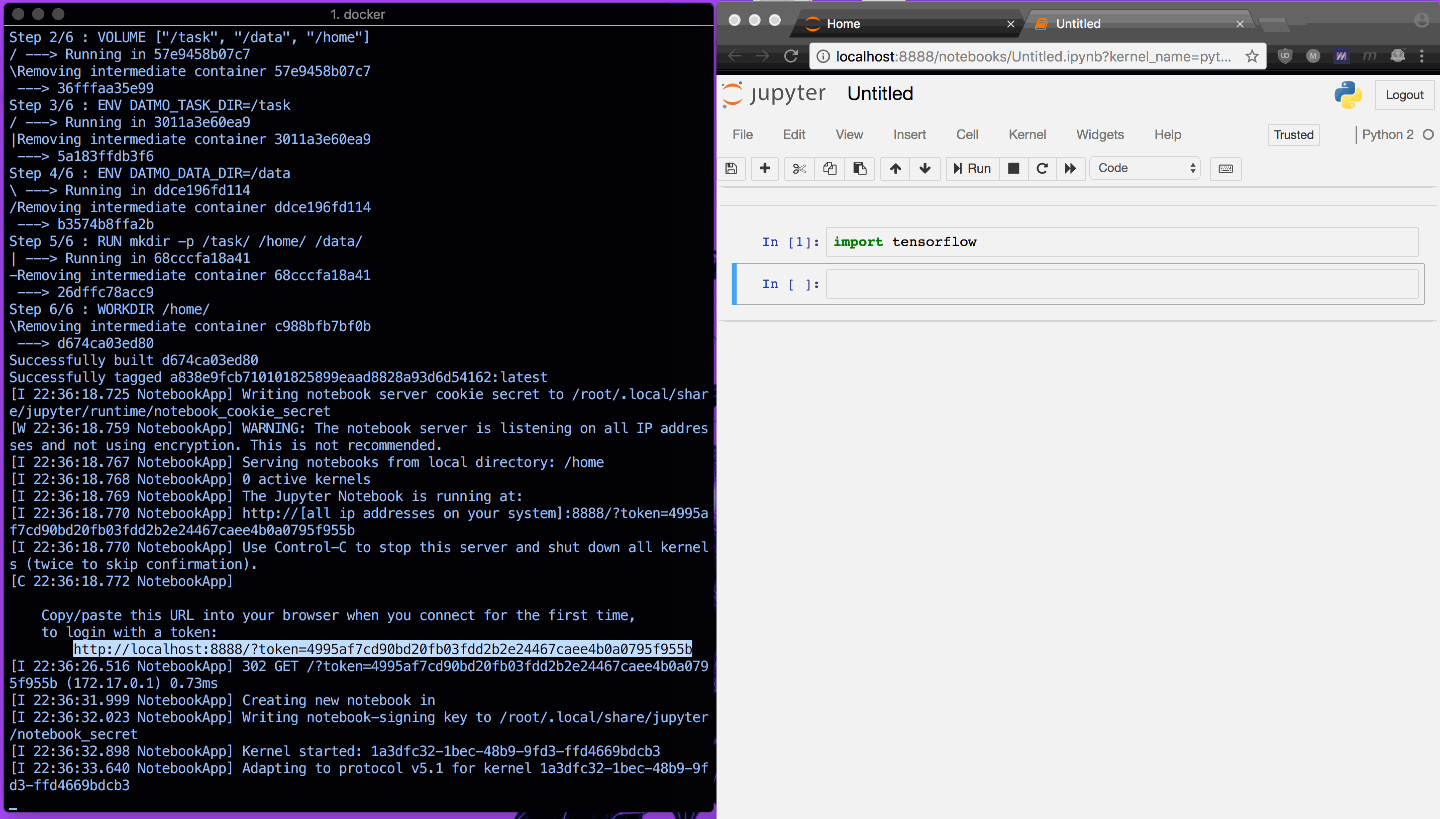
Voici une comparaison d'un modèle de régression logistique typique avec un modèle tirant parti de Datmo.
| Script normal | Avec Datmo |
|---|---|
# train.py#from sklearn importer des ensembles de données depuis sklearn importer linéaire_model en tant que lmfrom sklearn importer model_selection en tant que msfrom sklearn importer des éléments externes en tant qu'ex######iris_dataset = datasets.load_iris()X = iris_dataset.datay = iris_dataset.targetdata = ms.train_test_split (X, y)X_train, X_test, y_train, y_test = data#model = lm.LogisticRegression(solver="newton-cg")model.fit(X_train, y_train)ex.joblib.dump(model, 'model.pkl')#train_acc = model.score(X_train , y_train)test_acc = model.score(X_test, y_test)#print(train_acc)print(test_acc)######### | # train.py#from sklearn import datasetsfrom sklearn import linéaire_model as lmfrom sklearn import model_selection as msfrom sklearn import externals as eximport datmo # extra line#config = {"solver": "newton-cg"} # extra line#iris_dataset = datasets. load_iris()X = iris_dataset.datay = iris_dataset.targetdata = ms.train_test_split(X, y)X_train, X_test, y_train, y_test = data#model = lm.LogisticRegression(**config)model.fit(X_train, y_train)ex.joblib.dump(model, "model.pkl") #train_acc = model.score(X_train, y_train)test_acc = model.score(X_test, y_test)#stats = {"train_accuracy": train_acc,"test_accuracy": test_acc} # ligne supplémentaire#datmo.snapshot.create(message="mon premier instantané",filepaths=["model.pkl"],config=config,stats=stats) # ligne supplémentaire |
Pour exécuter le code ci-dessus, vous pouvez procéder comme suit.
Accédez à un répertoire avec un projet
$ mkdir MY_PROJECT $ cd MY_PROJECT
Initialiser un projet Datmo
$ datmo init
Copiez le code datmo ci-dessus dans un fichier train.py dans votre répertoire MY_PROJECT
Exécutez le script comme vous le feriez normalement en python
$ python train.py
Bravo! Vous venez de créer votre premier instantané :) Exécutez maintenant une commande ls pour les instantanés afin de voir votre premier instantané.
$ datmo snapshot ls
Lors de l'exécution datmo init , Datmo ajoute un répertoire .datmo caché qui assure le suivi de toutes les différentes entités en jeu. Ceci est nécessaire pour rendre un référentiel compatible avec les données.
Consultez notre page de concepts dans la documentation pour voir comment les pièces mobiles fonctionnent ensemble dans datmo.
Les documents complets sont hébergés ici. Si vous souhaitez contribuer à la documentation (code source situé ici dans /docs ), suivez la procédure décrite dans CONTRIBUTING.md .
Vous pouvez transformer votre référentiel existant en un référentiel compatible Datmo avec la commande suivante
$ datmo init
Si à tout moment vous souhaitez supprimer datmo, vous pouvez simplement supprimer le répertoire .datmo de votre référentiel ou exécuter la commande suivante
$ datmo cleanup
AVERTISSEMENT : il ne s'agit pas actuellement d'une option officiellement prise en charge et ne fonctionne que pour les couches de stockage basées sur des fichiers (telles que définies dans la configuration) comme solution de contournement pour partager des projets Datmo.
Bien que datmo soit conçu pour suivre les modifications localement, vous pouvez partager un projet en le poussant vers un serveur distant en procédant comme suit (cela s'affiche uniquement pour git, si vous utilisez un autre outil de suivi SCM, vous pouvez probablement faire quelque chose de similaire). Si vos fichiers sont trop volumineux ou ne peuvent pas être ajoutés à SCM, cela risque de ne pas fonctionner pour vous.
Ce qui suit a été testé sur les terminaux BASH uniquement. Si vous utilisez un autre terminal, vous risquez de rencontrer des erreurs.
$ git add -f .datmo/* # add in .datmo to your scm $ git commit -m "adding .datmo to tracking" # commit it to your scm $ git push # push to remote $ git push origin +refs/datmo/*:refs/datmo/* # push datmo refs to remote
Ce qui précède vous permettra de partager des résultats et des entités Datmo avec vous-même ou avec d'autres personnes sur d'autres machines. REMARQUE : vous devrez supprimer .datmo/ du suivi pour commencer à utiliser datmo sur l'autre machine ou à un autre emplacement. Consultez les instructions ci-dessous pour voir comment le répliquer à un autre emplacement.
$ git clone YOUR_REMOTE_URL $ cd YOUR_REPO $ echo '.datmo/*' > .git/info/exclude # include .datmo into your .git exclude $ git rm -r --cached .datmo # remove cached versions of .datmo from scm $ git commit -m "removed .datmo from tracking" # clean up your scm so datmo can work $ git pull origin +refs/datmo/*:refs/datmo/* # pull datmo refs from remote $ datmo init # This enables datmo in the new location. If you enter blanks, no project information will be updated
Si vous souhaitez partager via le protocole Datmo, vous pouvez visiter le site Web de Datmo
Q : Que dois-je faire si le datmo stop --all ne fonctionne pas et que je ne peux pas démarrer un nouveau conteneur en raison d'une réallocation de port ?
R : Cela peut être dû à un conteneur fantôme exécuté à partir d'un autre projet Datmo ou d'un autre conteneur. Soit vous pouvez créer une image Docker avec une allocation de port spécifique (autre que 8888), rechercher l'image Docker, l'arrêter et la supprimer à l'aide docker ps --all et docker conntainer stop <ID> et docker container rm <ID> . Ou vous pouvez arrêter et supprimer toutes les images en cours d'exécution sur la machine [REMARQUE : cela peut affecter d'autres processus Docker sur votre machine, alors PROCÉDEZ AVEC ATTENTION] docker container stop $(docker ps -a -q) et docker container rm $(docker ps -a -q)


