DI-mouton : Apprentissage par renforcement profond + Le mouton fait un mouton
Lorsque la perle de la technologie de l'IA, l'apprentissage par renforcement profond, rencontre un jeu avec un soi-disant « taux de liquidation de seulement 0,01 % », quel genre d'idées étranges en ressortiront ?
PS Si vous passez par là, n'oubliez pas de cliquer sur une étoile pour continuer à mettre à jour.
PSS Vous voulez en savoir plus sur l’apprentissage par renforcement profond ? Venez chez DI-engine pour former votre propre agent.
Nouvelles
- [bilibili] Vous ne pouvez pas rejoindre le troupeau ? Alors venez rejoindre le groupe félin ! La version d'apprentissage par renforcement profond du mouton est arrivée.
- [WeChat] Est-ce que tout est difficile au début ? Ce n'est pas difficile pour Meow DI de jouer à « le mouton fait le mouton »
Guide de l'utilisateur
Analyse des principes de l'algorithme
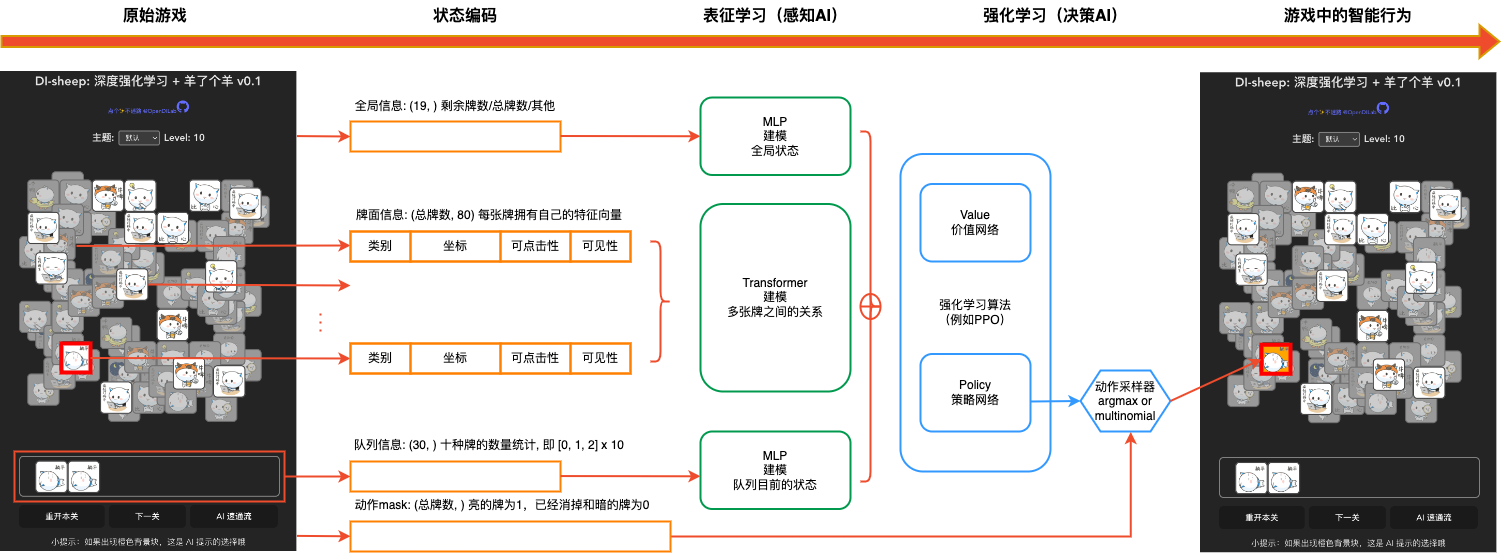
Commencez rapidement
- Si vous souhaitez l'essayer en ligne --> Page Web en ligne (en cours d'amélioration)
- Si vous souhaitez déployer/tester localement
- Serveur (Python)
# 预先安装好 Python3
cd service
pip install -r requirement.txt
FLASK_APP=app.py flask run # 玩家试玩
# FLASK_APP=agent_app.py flask run # 玩家 + AI 试玩
- Client (réagir)
# 预先安装好 node.js 和 react
cd ui
npm run build
npm run preview
- Si vous souhaitez effectuer une formation complète d'apprentissage par renforcement profond
# 预先安装好 Python3
cd service
pip install -r requirement-train.txt
python3 -u sheep_ppo_main.py
- Si vous souhaitez utiliser la salle de sport définie, créez un environnement mouton --> cliquez sur étoile et utilisez directement CTRL C+V pour prendre
service/sheep_env.py et modifiez-le autant que vous le souhaitez. - Si vous souhaitez obtenir le modèle d'apprentissage par renforcement profond formé --> Visitez le lien de téléchargement du site officiel d'OpenDILab (actuellement, deux modèles d'essai sont fournis, mais l'agent a encore beaucoup à faire)
- Si vous souhaitez en savoir plus sur l'apprentissage par renforcement profond --> Bienvenue pour vous référer au moteur DI et aux documents associés
- Si vous souhaitez connaître le futur plan de mise à jour --> veuillez vous référer au plan de mise à jour
- Si vous avez d'autres questions ou idées -> Bienvenue pour discuter dans la zone github ISSUE, ou contribuer aux demandes Pull
Structure du projet
.
├── LICENSE
├── ui --> react 网页前端
└── service --> Python 核心模块(算法和服务端)
├── app.py --> flask 服务 app (仅人类操作)
├── agent_app.py --> flask 服务 app(人类+AI操作)
├── requirement.txt --> Python 依赖库列表
├── sheep_env.py --> gym 格式环境
├── sheep_model.py --> 基于 PyTorch 的 Actor-Critic 神经网络模型
├── sheep_ppo_main.py --> 基于 DI-engine 的深度强化学习训练主函数
├── test_sheep_env.py --> gym 格式环境的单元测试
└── test_sheep_model.py --> 神经网络模型的单元测试
Plan de mise à jour
algorithme
environnement
application
Remerciements
- La référence principale pour la partie front-end de réaction est https://github.com/StreakingMan/solvable-sheep-game Veuillez prendre en charge ce dépôt.
Licence
DI-sheep est publié sous la licence Apache 2.0.