lion pytorch
0.2.3
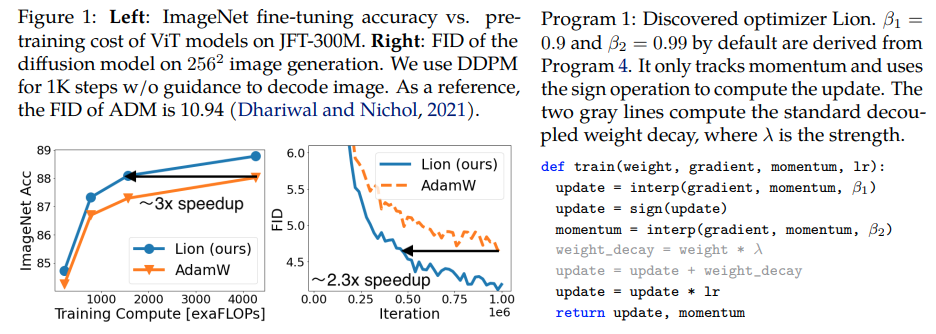
Lion, Evo L ved S i gn M o me n tum, nouvel optimiseur découvert par Google Brain et prétendument meilleur qu'Adam(w), dans Pytorch. Il s'agit presque d'une copie directe d'ici, avec quelques modifications mineures.
C'est tellement simple, autant le rendre accessible et utilisé au plus vite par tout le monde pour former de superbes modèles, si ça marche vraiment ?
Taux d'apprentissage et perte de poids : les auteurs écrivent dans la section 5 - Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. La valeur initiale, la valeur maximale et la valeur finale dans le calendrier de taux d'apprentissage doivent être modifiées simultanément avec le même rapport par rapport à AdamW, comme en témoigne un chercheur.
Barème de taux d'apprentissage : les auteurs utilisent le même barème de taux d'apprentissage pour Lion que pour AdamW dans l'article. Néanmoins, ils observent un gain plus important en utilisant un programme de désintégration du cosinus pour entraîner ViT, par rapport à un programme de racine carrée réciproque.
β1 et β2 : les auteurs écrivent dans la section 5 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. De la même manière que les gens réduisent β2 à 0,99 ou moins et augmentent ε à 1e-6 dans AdamW pour améliorer la stabilité, l'utilisation de β1=0.95, β2=0.98 dans Lion peut également être utile pour atténuer l'instabilité pendant l'entraînement, suggérée par les auteurs. Cela a été corroboré par un chercheur.
Mise à jour : semble fonctionner pour ma modélisation de langage autorégressive enwik8 locale.
Mise à jour 2 : les expériences semblent bien pires qu'Adam si le taux d'apprentissage restait constant.
Mise à jour 3 : diviser le taux d'apprentissage par 3, obtenant de meilleurs premiers résultats qu'Adam. Peut-être qu’Adam a été détrôné après près d’une décennie.
Mise à jour 4 : l'utilisation de la règle empirique du taux d'apprentissage 10 fois plus petit de l'article a abouti à la pire exécution. Donc je suppose que cela demande encore un peu de réglage.
Un résumé des mises à jour précédentes : comme le montrent les expériences, Lion avec un taux d'apprentissage 3 fois plus faible bat Adam. Cela nécessite encore un peu de réglage, car un taux d'apprentissage 10 fois inférieur conduit à un résultat moins bon.
Mise à jour 5 : jusqu'à présent, j'entends tous les résultats positifs pour la modélisation du langage, lorsqu'ils sont bien faits. Nous avons également entendu des résultats positifs pour une formation texte-image importante, même si cela nécessite un peu de réglage. Les résultats négatifs semblent concerner des problèmes et des architectures en dehors de ce qui a été évalué dans l'article - RL, réseaux feedforward, architectures hybrides étranges avec LSTM + convolutions, etc. Des anecdotes négatives confirment également que cette technique est sensible à la taille du lot, à la quantité de données/augmentation . À déterminer quel est le calendrier de taux d'apprentissage optimal et si le temps de recharge affecte les résultats. Il est également intéressant d'avoir un résultat positif à l'open-clip, qui est devenu négatif à mesure que la taille du modèle a augmenté (mais peut être résolu).
Mise à jour 6 : problème de clip ouvert résolu par l'auteur, en définissant une température initiale plus élevée.
Mise à jour 7 : je ne recommanderais cet optimiseur que dans le cadre de tailles de lots élevées (64 ou plus)
$ pip installer lion-pytorch
Alternativement, en utilisant conda :
$ conda installe lion-pytorch
# toy modelimport torchfrom torch import nnmodel = nn.Linear(10, 1)# import Lion et instancier avec les paramètresfrom lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4,weight_decay=1e-2)# forward et reversesloss = model(torch.randn(10))loss.backward()# optimiseur stepopt.step()opt.zero_grad()
Pour utiliser un noyau fusionné pour mettre à jour les paramètres, commencez par pip install triton -U --pre , puis
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # définissez ceci sur True pour utiliser le noyau cuda avec la langue Triton (Tillet et al))
Stability.ai pour son généreux parrainage en faveur du travail et de la recherche de pointe en intelligence artificielle open source
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen, Xiangning et Liang, Chen et Huang, Da et Real, Esteban et Wang, Kaiyuan et Liu, Yao et Pham, Hieu et Dong, Xuanyi et Luong, Thang et Hsieh, Cho-Jui et Lu, Yifeng et Le, Quoc V.},titre = {Découverte symbolique des algorithmes d'optimisation},éditeur = {arXiv},année = {2023}} @article{Tillet2019TritonAI,title = {Triton : un langage intermédiaire et un compilateur pour les calculs de réseaux neuronaux en mosaïque},author = {Philippe Tillet et H. Kung et D. Cox},journal = {Actes du 3e atelier international ACM SIGPLAN sur les machines Langages d'apprentissage et de programmation}, année = {2019}} @misc{Schaipp2024,author = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {Optimiseurs prudents : améliorer la formation avec une seule ligne de code},author = {Kaizhao Liang et Lizhang Chen et Bo Liu et Qiang Liu},year = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

