reaver
1.0.0
Statut du projet : Plus maintenu !
Malheureusement, je ne suis plus en mesure de développer davantage ou de soutenir le projet.
Reaver est un cadre modulaire d'apprentissage par renforcement profond axé sur diverses tâches basées sur StarCraft II, suivant les traces de DeepMind qui pousse l'état de l'art dans le domaine à travers le prisme du jeu vidéo moderne avec une interface de type humain et limites. Cela inclut l'observation de caractéristiques visuelles similaires (mais pas identiques) à ce qu'un joueur humain percevrait et le choix d'actions parmi un ensemble d'options similaires dont disposerait un joueur humain. Voir l'article StarCraft II : Un nouveau défi pour l'apprentissage par renforcement pour plus de détails.
Bien que le développement soit axé sur la recherche, la philosophie derrière l'API Reaver s'apparente au jeu StarCraft II lui-même : elle a quelque chose à offrir à la fois aux novices et aux experts dans le domaine. Pour les programmeurs amateurs, Reaver propose tous les outils nécessaires pour former les agents DRL en modifiant seulement une partie petite et isolée de l'agent (par exemple les hyperparamètres). Pour les chercheurs chevronnés, Reaver propose une base de code simple mais optimisée en termes de performances avec une architecture modulaire : l'agent, le modèle et l'environnement sont découplés et peuvent être échangés à volonté.
Bien que Reaver se concentre sur StarCraft II, il prend également entièrement en charge d'autres environnements populaires, notamment Atari et MuJoCo. Les algorithmes de l'agent Reaver sont validés par rapport aux résultats de référence, par exemple l'agent PPO est capable de correspondre aux algorithmes d'optimisation de politique proximale. Veuillez voir ci-dessous pour plus de détails.
Le moyen le plus simple d'installer Reaver consiste à utiliser le gestionnaire de packages PIP :
pip install reaver
Vous pouvez également installer des extras supplémentaires (par exemple, un support gym ) via les drapeaux d'assistance :
pip install reaver[gym,atari,mujoco]
Si vous envisagez de modifier la base de code Reaver vous pouvez conserver les fonctionnalités de son module en l'installant à partir des sources :
$ git clone https://github.com/inoryy/reaver-pysc2
$ pip install -e reaver-pysc2/
En installant avec l'indicateur -e , Python recherchera désormais reaver dans le dossier spécifié, plutôt que dans le stockage site-packages .
Veuillez consulter la page wiki pour des instructions détaillées sur la configuration de Reaver sous Windows.
Cependant, si possible, envisagez plutôt d'utiliser Linux OS - pour des raisons de performances et de stabilité. Si vous souhaitez voir votre agent fonctionner avec tous les graphiques activés, vous pouvez enregistrer une rediffusion de l'agent sous Linux et l'ouvrir sous Windows. C’est ainsi qu’a été réalisé l’enregistrement vidéo répertorié ci-dessous.
Si vous souhaitez utiliser Reaver avec d'autres environnements pris en charge, vous devez également installer les packages appropriés :
Vous pouvez former un agent DRL avec plusieurs environnements StarCraft II exécutés en parallèle avec seulement quatre lignes de code !
import reaver as rvr
env = rvr . envs . SC2Env ( map_name = 'MoveToBeacon' )
agent = rvr . agents . A2C ( env . obs_spec (), env . act_spec (), rvr . models . build_fully_conv , rvr . models . SC2MultiPolicy , n_envs = 4 )
agent . run ( env )De plus, Reaver est livré avec des outils de ligne de commande hautement configurables, cette tâche peut donc être réduite à une courte phrase !
python -m reaver.run --env MoveToBeacon --agent a2c --n_envs 4 2> stderr.logAvec la ligne ci-dessus, Reaver initialisera la procédure de formation avec un ensemble d'hyperparamètres prédéfinis, optimisés spécifiquement pour l'environnement et l'agent donnés. Après un certain temps, vous commencerez à voir des journaux avec diverses statistiques utiles sur l'écran de votre terminal.
| T 118 | Fr 51200 | Ep 212 | Up 100 | RMe 0.14 | RSd 0.49 | RMa 3.00 | RMi 0.00 | Pl 0.017 | Vl 0.008 | El 0.0225 | Gr 3.493 | Fps 433 |
| T 238 | Fr 102400 | Ep 424 | Up 200 | RMe 0.92 | RSd 0.97 | RMa 4.00 | RMi 0.00 | Pl -0.196 | Vl 0.012 | El 0.0249 | Gr 1.791 | Fps 430 |
| T 359 | Fr 153600 | Ep 640 | Up 300 | RMe 1.80 | RSd 1.30 | RMa 6.00 | RMi 0.00 | Pl -0.035 | Vl 0.041 | El 0.0253 | Gr 1.832 | Fps 427 |
...
| T 1578 | Fr 665600 | Ep 2772 | Up 1300 | RMe 24.26 | RSd 3.19 | RMa 29.00 | RMi 0.00 | Pl 0.050 | Vl 1.242 | El 0.0174 | Gr 4.814 | Fps 421 |
| T 1695 | Fr 716800 | Ep 2984 | Up 1400 | RMe 24.31 | RSd 2.55 | RMa 30.00 | RMi 16.00 | Pl 0.005 | Vl 0.202 | El 0.0178 | Gr 56.385 | Fps 422 |
| T 1812 | Fr 768000 | Ep 3200 | Up 1500 | RMe 24.97 | RSd 1.89 | RMa 31.00 | RMi 21.00 | Pl -0.075 | Vl 1.385 | El 0.0176 | Gr 17.619 | Fps 423 |
Reaver devrait rapidement converger vers environ 25-26 RMe (récompenses moyennes des épisodes), ce qui correspond aux résultats de DeepMind pour cet environnement. La durée de formation spécifique dépend de votre matériel. Les journaux ci-dessus sont produits sur un ordinateur portable équipé d'un processeur Intel i5-7300HQ (4 cœurs) et d'un GPU GTX 1050, la formation a duré environ 30 minutes.
Une fois que Reaver a terminé son entraînement, vous pouvez voir ses performances en ajoutant les indicateurs --test et --render au one-liner.
python -m reaver.run --env MoveToBeacon --agent a2c --test --render 2> stderr.logUn ordinateur portable Google Colab est disponible pour essayer Reaver en ligne.
De nombreux algorithmes DRL modernes reposent sur une exécution simultanée et parallèle dans plusieurs environnements. Comme Python possède GIL, cette fonctionnalité doit être implémentée via le multitraitement. La majorité des implémentations open source résolvent cette tâche avec une approche basée sur les messages (par exemple Python multiprocessing.Pipe ou MPI ), où les processus individuels communiquent en envoyant des données via IPC. Il s’agit d’une approche valable et probablement la seule raisonnable pour les approches distribuées à grande échelle sur lesquelles opèrent des sociétés comme DeepMind et openAI.
Cependant, pour un chercheur ou un amateur typique, un scénario beaucoup plus courant consiste à n'avoir accès qu'à un seul environnement de machine, qu'il s'agisse d'un ordinateur portable ou d'un nœud sur un cluster HPC. Reaver est optimisé spécifiquement pour ce cas en utilisant la mémoire partagée sans verrouillage. Cette approche permet d'obtenir une amélioration significative des performances, allant jusqu'à 1,5 fois la vitesse d'échantillonnage de StarCraft II (et jusqu'à 100 fois l'accélération dans le cas général), étant goulot d'étranglement presque exclusivement par le pipeline d'entrée/sortie du GPU.
Les trois modules principaux de Reaver - envs , models et agents sont presque complètement détachés les uns des autres. Cela garantit que l’extension des fonctionnalités d’un module est parfaitement intégrée aux autres.
Toute la configuration est gérée via gin-config et peut être facilement partagée sous forme de fichiers .gin . Cela inclut tous les hyperparamètres, arguments d’environnement et définitions de modèle.
Lorsque vous expérimentez de nouvelles idées, il est important d’obtenir rapidement des retours, ce qui n’est souvent pas réaliste dans des environnements complexes comme StarCraft II. Comme Reaver a été construit avec une architecture modulaire, ses implémentations d'agents ne sont pas du tout liées à StarCraft II. Vous pouvez effectuer des remplacements immédiats pour de nombreux environnements de jeu populaires (par exemple, openAI gym ) et vérifier en premier que les implémentations fonctionnent avec ceux-ci :
python -m reaver.run --env CartPole-v0 --agent a2c 2> stderr.log import reaver as rvr
env = rvr . envs . GymEnv ( 'CartPole-v0' )
agent = rvr . agents . A2C ( env . obs_spec (), env . act_spec ())
agent . run ( env )Actuellement, les environnements suivants sont pris en charge par Reaver :
CartPole-v0 )PongNoFrameskip-v0 )InvertedPendulum-v2 et HalfCheetah-v2 ) | Carte | Saccageur (A2C) | DeepMindSC2LE | DeepMindReDRL | Expert humain |
|---|---|---|---|---|
| Déplacer vers la balise | 26,3 (1,8) [21, 31] | 26 | 27 | 28 |
| Collecter des fragments minéraux | 102,8 (10,8) [81, 135] | 103 | 196 | 177 |
| DéfaiteCafards | 72,5 (43,5) [21, 283] | 100 | 303 | 215 |
| Trouver et vaincre les Zerglings | 22,1 (3,6) [12, 40] | 45 | 62 | 61 |
| Vaincre les Zerglings et les Banelings | 56,8 (20,8) [21, 154] | 62 | 736 | 727 |
| Collecter des minéraux et du gaz | 2267,5 (488,8) [0, 3320] | 3 978 | 5 055 | 7 566 |
| ConstruireMarines | -- | 3 | 123 | 133 |
Human Expert ont été collectés par DeepMind auprès d’un joueur de niveau GrandMaster.DeepMind ReDRL fait référence aux résultats de pointe actuels, décrits dans l'article Relational Deep Reinforcement Learning.DeepMind SC2LE sont des résultats publiés dans l'article StarCraft II: A New Challenge for Reinforcement Learning.Reaver (A2C) sont des résultats rassemblés en formant l'agent reaver.agents.A2C , en répliquant l'architecture SC2LE aussi fidèlement que possible sur le matériel disponible. Les résultats sont collectés en exécutant l'agent formé en mode --test pendant 100 épisodes, en calculant les récompenses totales des épisodes. Sont répertoriés la moyenne, l’écart type (entre parenthèses) et les min et max (entre crochets).| Carte | Échantillons | Épisodes | Env. Temps (heure) |
|---|---|---|---|
| Déplacer vers la balise | 563 200 | 2 304 | 0,5 |
| Collecter des fragments minéraux | 74 752 000 | 311 426 | 50 |
| DéfaiteCafards | 172 800 000 | 1 609 211 | 150 |
| Trouver et vaincre les Zerglings | 29 760 000 | 89 654 | 20 |
| Vaincre les Zerglings et les Banelings | 10 496 000 | 273 463 | 15 |
| Collecter des minéraux et du gaz | 16 864 000 | 20 544 | 10 |
| ConstruireMarines | - | - | - |
Samples font référence au nombre total de chaînes observe -> step -> reward dans un environnement.Episodes font référence au nombre total d'indicateurs StepType.LAST renvoyés par PySC2.Approx. Time est la durée approximative de formation sur un laptop équipé d'un processeur Intel i5-7300HQ (4 cœurs) et d'un GPU GTX 1050 . Notez que je n'ai pas consacré beaucoup de temps au réglage des hyperparamètres, me concentrant principalement sur la vérification que l'agent est capable d'apprendre plutôt que sur la maximisation de l'efficacité des échantillons. Par exemple, un premier essai naïf sur MoveToBeacon a nécessité environ 4 millions d'échantillons, mais après quelques essais, j'ai pu le réduire jusqu'à 102 000 (réduction d'environ 40x) avec l'agent PPO.
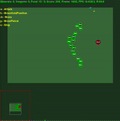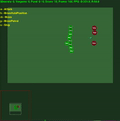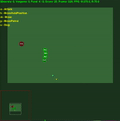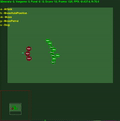
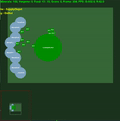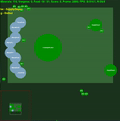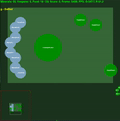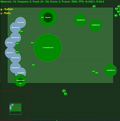
Récompenses moyennes de l'épisode avec std.dev rempli entre les deux. Cliquez pour agrandir.
Un enregistrement vidéo de l'agent jouant aux six mini-jeux est disponible en ligne sur : https://youtu.be/gEyBzcPU5-w. Dans la vidéo de gauche, l'agent agit avec des poids initialisés de manière aléatoire et sans entraînement, tandis qu'à droite, il est entraîné à cibler des scores.
Le problème de la reproductibilité de la recherche est récemment devenu un sujet de nombreux débats dans la science en général, et l'apprentissage par renforcement ne fait pas exception. L’un des objectifs de Reaver en tant que projet scientifique est de faciliter la recherche reproductible. À cette fin, Reaver est fourni avec divers outils qui simplifient le processus :
Pour ouvrir la voie en matière de reproductibilité, Reaver est fourni avec des poids pré-entraînés et des journaux récapitulatifs complets de Tensorboard pour les six mini-jeux. Téléchargez simplement une archive d'expérience depuis l'onglet releases et décompressez-la dans le répertoire results/ .
Vous pouvez utiliser des poids pré-entraînés en ajoutant l'indicateur --experiment à la commande reaver.run :
python reaver.run --map <map_name> --experiment <map_name>_reaver --test 2> stderr.log
Les journaux Tensorboard sont disponibles si vous lancez tensorboard --logidr=results/summaries .
Vous pouvez également les consulter directement en ligne via Aughie Boards.
Reaver est une unité Protoss très spéciale et subjectivement mignonne dans l'univers du jeu StarCraft. Dans la version StarCraft: Brood War du jeu, Reaver était connu pour être lent, maladroit et souvent inutile s'il était laissé seul à cause d'une IA boguée dans le jeu. Cependant, entre les mains de joueurs dévoués qui ont investi du temps dans la maîtrise de l'unité, Reaver est devenu l'un des atouts les plus puissants du jeu, jouant souvent un rôle clé dans les parties gagnantes des tournois.
Un prédécesseur de Reaver, nommé simplement pysc2-rl-agent , a été développé dans le cadre de la partie pratique d'une thèse de licence à l'Université de Tartu sous la direction d'Ilya Kuzovkin et Tambet Matiisen. Vous pouvez toujours y accéder sur la branche v1.0.
Si vous rencontrez un problème lié à la base de code, veuillez ouvrir un ticket sur GitHub et le décrire de manière aussi détaillée que possible. Si vous avez des questions plus générales ou si vous avez simplement besoin de conseils, n'hésitez pas à m'envoyer un e-mail.
Je suis également fier d'être membre d'une communauté en ligne SC2AI active et conviviale, nous utilisons principalement Discord pour la communication. Les personnes de tous horizons et de tous niveaux d’expertise sont les bienvenues !
Si vous avez trouvé Reaver utile dans votre recherche, pensez à le citer avec le bibtex suivant :
@misc{reaver,
author = {Ring, Roman},
title = {Reaver: Modular Deep Reinforcement Learning Framework},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/inoryy/reaver}},
}


