se3 transformer pytorch
0.9.0
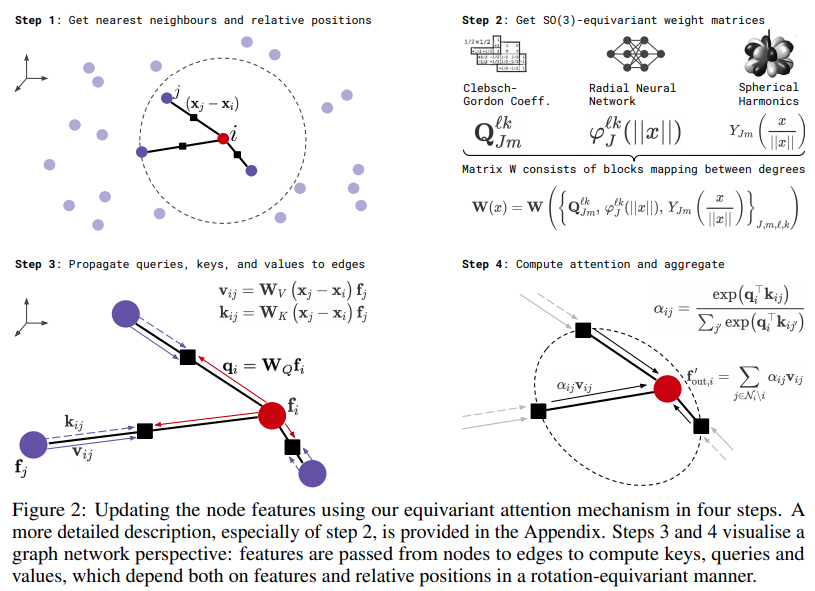
Implémentation de transformateurs SE3 pour l'auto-attention équivariante, dans Pytorch. Peut être nécessaire pour reproduire les résultats d’Alphafold2 et d’autres applications de découverte de médicaments.
Exemple d'équivariance
Si vous avez utilisé une version de SE3 Transformers antérieure à la version 0.6.0, veuillez la mettre à jour. Un énorme bug a été découvert par @MattMcPartlon, si vous n'utilisiez pas les paramètres de voisins clairsemés de contiguïté et si vous ne comptiez pas sur la fonctionnalité des voisins les plus proches.
Mise à jour : il est recommandé d'utiliser Equiformer à la place
$ pip install se3-transformer-pytorch import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512)Exemple d'utilisation potentielle dans Alphafold2, comme indiqué ici
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True ,
differentiable_coors = True
)
atom_feats = torch . randn ( 2 , 32 , 64 )
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atom_feats , coors , mask , return_type = 1 ) # (2, 32, 3)Vous pouvez également laisser la classe de transformateur de base s'occuper de l'intégration des fonctionnalités de type 0 transmises. En supposant qu'il s'agisse d'atomes
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 , # 28 unique atoms
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atoms , coors , mask , return_type = 1 ) # (2, 32, 3)Si vous pensez que le réseau pourrait bénéficier davantage du codage positionnel, vous pouvez caractériser vos positions dans l'espace et les transmettre comme suit.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 2 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True # reduce out the final dimension
)
atom_feats = torch . randn ( 2 , 32 , 64 , 1 ) # b x n x d x type0
coors_feats = torch . randn ( 2 , 32 , 64 , 3 ) # b x n x d x type1
# atom features are type 0, predicted coordinates are type 1
features = { '0' : atom_feats , '1' : coors_feats }
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( features , coors , mask , return_type = 1 ) # (2, 32, 3) - equivariant to input type 1 features and coordinates Pour offrir des informations de bord aux transformateurs SE3 (par exemple les types de liaisons entre atomes), il vous suffit de transmettre deux arguments de mots-clés supplémentaires lors de l'initialisation.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 , # number of edge type, say 4 bond types
edge_dim = 16 , # dimension of edge embedding
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds , return_type = 0 ) # (2, 32, 1) Si vous souhaitez transmettre des valeurs continues pour vos arêtes, vous pouvez choisir de ne pas définir le num_edge_tokens , d'encoder vos types de liaisons discrètes, puis de les concaténer aux caractéristiques de Fourier de ces valeurs continues.
import torch
from se3_transformer_pytorch import SE3Transformer
from se3_transformer_pytorch . utils import fourier_encode
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
edge_dim = 34 # edge dimension must match the final dimension of the edges being passed in
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
pairwise_continuous_values = torch . randint ( 0 , 4 , ( 1 , 32 , 32 , 2 )) # say there are 2
edges = fourier_encode (
pairwise_continuous_values ,
num_encodings = 8 ,
include_self = True
) # (1, 32, 32, 34) - {2 * (2 * 8 + 1)}
out = model ( feats , coors , mask , edges = edges , return_type = 1 ) Si vous connaissez la connectivité de vos points (disons que vous travaillez avec des molécules), vous pouvez passer dans une matrice d'adjacence, sous la forme d'un masque booléen (où True indique la connectivité).
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
heads = 8 ,
depth = 1 ,
dim_head = 64 ,
num_degrees = 2 ,
valid_radius = 10 ,
attend_sparse_neighbors = True , # this must be set to true, in which case it will assert that you pass in the adjacency matrix
num_neighbors = 0 , # if you set this to 0, it will only consider the connected neighbors as defined by the adjacency matrix. but if you set a value greater than 0, it will continue to fetch the closest points up to this many, excluding the ones already specified by the adjacency matrix
max_sparse_neighbors = 8 # you can cap the number of neighbors, sampled from within your sparse set of neighbors as defined by the adjacency matrix, if specified
)
feats = torch . randn ( 1 , 128 , 32 )
coors = torch . randn ( 1 , 128 , 3 )
mask = torch . ones ( 1 , 128 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat ) # (1, 128, 512) Vous pouvez également demander au réseau de dériver automatiquement pour vous les voisins du Nième degré avec un mot-clé supplémentaire num_adj_degrees . Si vous souhaitez que le système fasse la différence entre le degré des voisins en tant qu'informations de bord, transmettez en outre un adj_dim non nul.
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
num_neighbors = 0 ,
attend_sparse_neighbors = True ,
num_adj_degrees = 2 , # automatically derive 2nd degree neighbors
adj_dim = 4 # embed 1st and 2nd degree neighbors (as well as null neighbors) with edge embeddings of this dimension
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat , return_type = 1 ) Pour avoir un contrôle précis sur la dimensionnalité de chaque type, vous pouvez utiliser les mots-clés hidden_fiber_dict et out_fiber_dict pour passer dans un dictionnaire avec les valeurs de degré à dimension comme clé/valeurs.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 ,
edge_dim = 16 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
hidden_fiber_dict = { 0 : 16 , 1 : 8 , 2 : 4 },
out_fiber_dict = { 0 : 16 , 1 : 1 },
reduce_dim_out = False
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds )
pred [ '0' ] # (2, 32, 16)
pred [ '1' ] # (2, 32, 1, 3) Vous pouvez contrôler davantage les nœuds qui peuvent être pris en compte en transmettant un masque de voisin. Toutes les valeurs False seront masquées.
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 16 ,
dim_head = 16 ,
attend_self = True ,
num_degrees = 4 ,
output_degrees = 2 ,
num_edge_tokens = 4 ,
num_neighbors = 8 , # make sure you set this value as the maximum number of neighbors set by your neighbor_mask, or it will throw a warning
edge_dim = 2 ,
depth = 3
)
feats = torch . randn ( 1 , 32 , 16 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
bonds = torch . randint ( 0 , 4 , ( 1 , 32 , 32 ))
neighbor_mask = torch . ones ( 1 , 32 , 32 ). bool () # set the nodes you wish to be masked out as False
out = model (
feats ,
coors ,
mask ,
edges = bonds ,
neighbor_mask = neighbor_mask ,
return_type = 1
)Cette fonctionnalité vous permet de transmettre des vecteurs qui peuvent être considérés comme des nœuds globaux vus par tous les autres nœuds. L'idée serait de regrouper votre graphique en quelques vecteurs de caractéristiques, qui seront projetés en clés/valeurs sur toutes les couches d'attention du réseau. Tous les nœuds auront un accès complet aux informations globales sur les nœuds, quels que soient les voisins les plus proches ou le calcul de contiguïté.
import torch
from torch import nn
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 2 ,
num_neighbors = 4 ,
valid_radius = 10 ,
global_feats_dim = 32 # this must be set to the dimension of the global features, in this example, 32
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# naively derive global features
# by pooling features and projecting
global_feats = nn . Linear ( 64 , 32 )( feats . mean ( dim = 1 , keepdim = True )) # (1, 1, 32)
out = model ( feats , coors , mask , return_type = 0 , global_feats = global_feats )Faire:
Vous pouvez utiliser les transformateurs SE3 de manière autorégressive avec un seul indicateur supplémentaire
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10 ,
causal = True # set this to True
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512) J'ai découvert que l'utilisation de clés projetées linéairement (plutôt que la convolution par paires) semble fonctionner correctement dans une tâche de débruitage de jouet. Cela conduit à 25 % d’économie de mémoire. Vous pouvez essayer cette fonctionnalité en définissant linear_proj_keys = True
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
linear_proj_keys = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )Il existe une technique relativement inconnue pour les transformateurs où l'on peut partager une tête clé/valeur entre toutes les têtes des requêtes. D'après mon expérience en PNL, cela conduit généralement à de moins bonnes performances, mais si vous avez vraiment besoin de sacrifier la mémoire pour plus de profondeur ou un nombre de degrés plus élevé, cela peut être une bonne option.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
one_headed_key_values = True # one head of key / values shared across all heads of the queries
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )Vous pouvez également lier les clés/valeurs (les faire en sorte qu'elles soient identiques), pour économiser la moitié de la mémoire.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
tie_key_values = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 ) Il s'agit d'une version expérimentale d'EGNN qui fonctionne pour des types supérieurs et une dimensionnalité supérieure à 1 (pour les coordonnées). Le nom de la classe est toujours SE3Transformer car il réutilise une logique préexistante, alors ignorez-le pour l'instant jusqu'à ce que je le nettoie plus tard.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
num_edge_tokens = 4 ,
edge_dim = 4 ,
num_degrees = 4 , # number of higher order types - will use basis on a TCN to project to these dimensions
use_egnn = True , # set this to true to use EGNN instead of equivariant attention layers
egnn_hidden_dim = 64 , # egnn hidden dimension
depth = 4 , # depth of EGNN
reduce_dim_out = True # will project the dimension of the higher types to 1
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 )). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , edges = bonds , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement Si vous souhaitez spécifier des dimensions individuelles pour chacun des types supérieurs, transmettez simplement hidden_fiber_dict où le dictionnaire est au format {<degree>:<dim>} au lieu de num_degrees
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
hidden_fiber_dict = { 0 : 32 , 1 : 16 , 2 : 8 , 3 : 4 },
use_egnn = True ,
depth = 4 ,
egnn_hidden_dim = 64 ,
egnn_weights_clamp_value = 2 ,
reduce_dim_out = True
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement Cette section répertorie les efforts en cours pour améliorer un peu l'échelle du SE3 Transformer.
Tout d'abord, j'ai ajouté des réseaux réversibles. Cela me permet d'ajouter un peu plus de profondeur avant de rencontrer les obstacles de mémoire habituels. La préservation de l’équivariance est démontrée dans les tests.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 20 ,
dim = 32 ,
dim_head = 32 ,
heads = 4 ,
depth = 12 , # 12 layers
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True ,
reversible = True # set reversible to True
). cuda ()
atoms = torch . randint ( 0 , 4 , ( 2 , 32 )). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
pred = model ( atoms , coors , mask = mask , return_type = 0 )
loss = pred . sum ()
loss . backward () Installez d’abord sidechainnet
$ pip install sidechainnetEnsuite, exécutez la tâche de débruitage du squelette protéique
$ python denoise.py Par défaut, les vecteurs de base sont mis en cache. Cependant, s'il est nécessaire de vider le cache, il vous suffit de définir l'indicateur environnemental CLEAR_CACHE sur une certaine valeur lors du lancement du script.
$ CLEAR_CACHE=1 python train.pyOu vous pouvez essayer de supprimer le répertoire cache, qui devrait exister à l'emplacement
$ rm -rf ~ /.cache.equivariant_attentionVous pouvez également désigner votre propre répertoire dans lequel vous souhaitez que les caches soient stockés, au cas où le répertoire par défaut aurait des problèmes d'autorisation.
CACHE_PATH=./path/to/my/cache python train.py$ python setup.py pytestCette bibliothèque est en grande partie un portage du référentiel officiel de Fabian, mais sans la bibliothèque DGL.
@misc { fuchs2020se3transformers ,
title = { SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks } ,
author = { Fabian B. Fuchs and Daniel E. Worrall and Volker Fischer and Max Welling } ,
year = { 2020 } ,
eprint = { 2006.10503 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { satorras2021en ,
title = { E(n) Equivariant Graph Neural Networks } ,
author = { Victor Garcia Satorras and Emiel Hoogeboom and Max Welling } ,
year = { 2021 } ,
eprint = { 2102.09844 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { gomez2017reversible ,
title = { The Reversible Residual Network: Backpropagation Without Storing Activations } ,
author = { Aidan N. Gomez and Mengye Ren and Raquel Urtasun and Roger B. Grosse } ,
year = { 2017 } ,
eprint = { 1707.04585 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2019fast ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam Shazeer } ,
year = { 2019 } ,
eprint = { 1911.02150 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.NE }
}

