RoboFlamingo
1.0.0
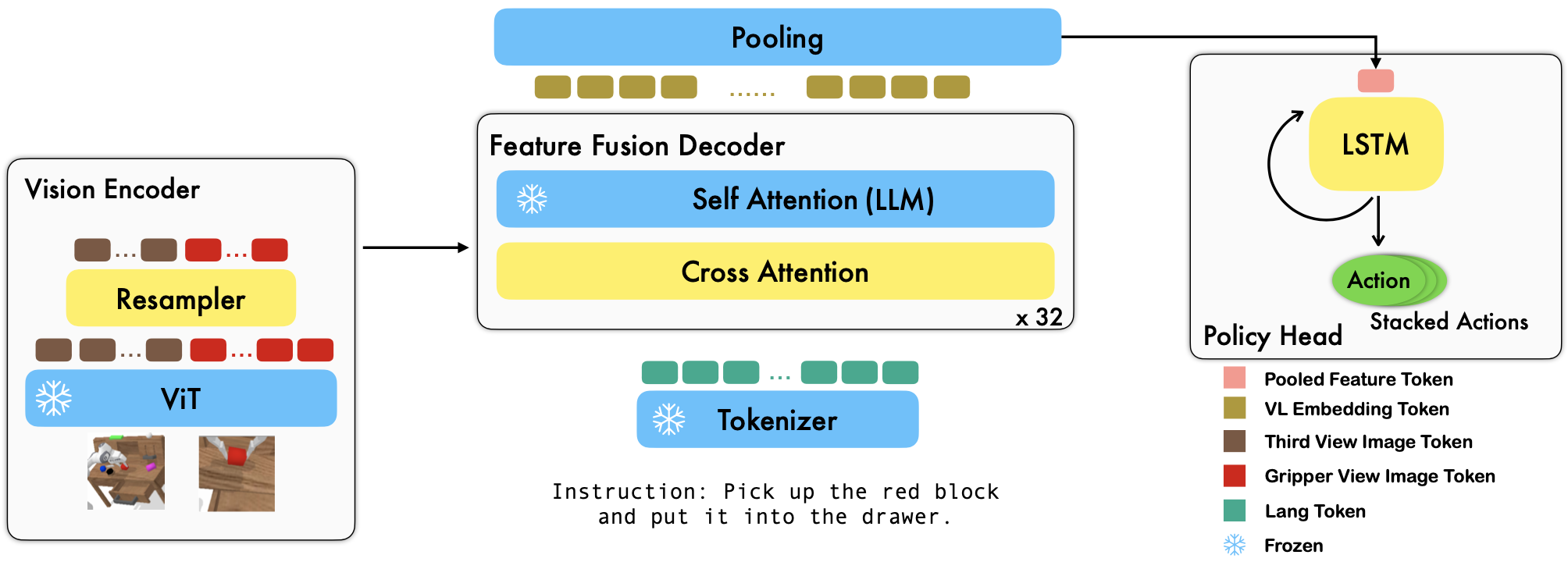
RoboFlamingo est un cadre d'apprentissage robotique pré-entraîné basé sur VLM qui apprend une grande variété de compétences robotiques conditionnées par le langage en affinant des ensembles de données d'imitation de forme libre hors ligne. En dépassant largement les performances de pointe sur le benchmark CALVIN, nous montrons que RoboFlamingo peut être une alternative efficace et compétitive pour adapter les VLM au contrôle des robots. Nos résultats expérimentaux approfondis révèlent également plusieurs conclusions intéressantes concernant le comportement de différents VLM pré-entraînés lors de tâches de manipulation. RoboFlamingo peut être formé ou évalué sur un seul serveur GPU (les exigences en matière de mémoire GPU dépendent de la taille du modèle), et nous pensons que RoboFlamingo a le potentiel d'être une solution rentable et facile à utiliser pour la manipulation robotique, donnant à chacun le pouvoir de le faire. capacité à affiner leur propre politique en matière de robotique.
Il s'agit également du dépôt de code officiel pour le document Vision-Language Foundation Models as Effective Robot Imitators.
Toutes nos expérimentations sont menées sur un seul serveur GPU avec 8 GPU Nvidia A100 (80G).
Des modèles pré-entraînés sont disponibles sur Hugging Face.
Nous prenons en charge les encodeurs de vision pré-entraînés du package OpenCLIP, qui inclut les modèles pré-entraînés d'OpenAI. Nous prenons également en charge les modèles de langage pré-entraînés du package transformers , tels que les modèles MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J et Pythia.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) L'argument cross_attn_every_n_layers contrôle la fréquence à laquelle les couches d'attention croisée sont appliquées et doit être cohérent avec le VLM. L'argument decoder_type contrôle le type du décodeur, actuellement, nous prenons en charge lstm , fc , diffusion (des bugs existent pour le chargeur de données) et GPT .
Nous rapportons les résultats du benchmark CALVIN.
| Méthode | Données de formation | Séparation des tests | 1 | 2 | 3 | 4 | 5 | Len moy. |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (complet) | D | 0,373 | 0,027 | 0,002 | 0,000 | 0,000 | 0,40 |
| HULC | ABCD (complet) | D | 0,889 | 0,733 | 0,587 | 0,475 | 0,383 | 3.06 |
| HULC (recyclé) | ABCD (Langue) | D | 0,892 | 0,701 | 0,548 | 0,420 | 0,335 | 2,90 |
| RT-1 (recyclé) | ABCD (Langue) | D | 0,844 | 0,617 | 0,438 | 0,323 | 0,227 | 2,45 |
| La nôtre | ABCD (Langue) | D | 0,964 | 0,896 | 0,824 | 0,740 | 0,66 | 4.09 |
| MCIL | ABC (complet) | D | 0,304 | 0,013 | 0,002 | 0,000 | 0,000 | 0,31 |
| HULC | ABC (complet) | D | 0,418 | 0,165 | 0,057 | 0,019 | 0,011 | 0,67 |
| RT-1 (recyclé) | ABC (Langue) | D | 0,533 | 0,222 | 0,094 | 0,038 | 0,013 | 0,90 |
| La nôtre | ABC (Langue) | D | 0,824 | 0,619 | 0,466 | 0,331 | 0,235 | 2,48 |
| HULC | ABCD (complet) | D (Enrichir) | 0,715 | 0,470 | 0,308 | 0,199 | 0,130 | 1,82 |
| RT-1 (recyclé) | ABCD (Langue) | D (Enrichir) | 0,494 | 0,222 | 0,086 | 0,036 | 0,017 | 0,86 |
| La nôtre | ABCD (Langue) | D (Enrichir) | 0,720 | 0,480 | 0,299 | 0,211 | 0,144 | 1,85 |
| Le nôtre (gelé-emb) | ABCD (Langue) | D (Enrichir) | 0,737 | 0,530 | 0,385 | 0,275 | 0,192 | 2.12 |
Suivez les instructions d'OpenFlamingo et de CALVIN pour télécharger l'ensemble de données nécessaire et les modèles pré-entraînés VLM.
Téléchargez le jeu de données CALVIN, choisissez un fractionnement avec :
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugTéléchargez les modèles OpenFlamingo publiés :
| # paramètres | Modèle de langage | Encodeur visuel | Intervalle Xattn* | COCO 4-shot CIDEr | Précision VQAv2 à 4 coups | Len moy. | Poids |
|---|---|---|---|---|---|---|---|
| 3B | anas-awadalla/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77.3 | 45,8 | 3,94 | Lien |
| 3B | anas-awadalla/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82,7 | 45,7 | 4.09 | Lien |
| 4B | ensembleordinateur/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81,8 | 49,0 | 3,67 | Lien |
| 4B | ensembleordinateur/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85,8 | 49,0 | 3,79 | Lien |
| 9B | anas-awadalla/mpt-7b | openai CLIP ViT-L/14 | 4 | 89,0 | 54,8 | 3,97 | Lien |
Remplacez les ${lang_encoder_path} et ${tokenizer_path} du dictionnaire de chemins (par exemple, mpt_dict ) dans robot_flamingo/models/factory.py pour chaque VLM pré-entraîné par vos propres chemins.
Cloner ce dépôt
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
Installez les packages requis :
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} est le chemin d'accès à l'ensemble de données CALVIN ;
${lm_path} est le chemin vers le LLM pré-entraîné;
${tokenizer_path} est le chemin d'accès au tokenizer VLM ;
${openflamingo_checkpoint} est le chemin d'accès au modèle pré-entraîné OpenFlamingo ;
${log_file} est le chemin d'accès au fichier journal.
Nous fournissons également robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash pour lancer la formation. Ce bash affine la version MPT-3B-IFT du modèle OpenFlamingo, qui contient les hyperparamètres par défaut pour entraîner le modèle, et correspond aux meilleurs résultats de l'article.
python eval_ckpts.py
En ajoutant le nom et le répertoire du point de contrôle dans eval_ckpts.py , le script chargerait automatiquement le modèle et l'évaluerait. Par exemple, si vous souhaitez évaluer le point de contrôle sur le chemin « votre chemin de point de contrôle », vous pouvez modifier les variables ckpt_dir et ckpt_names dans eval_ckpts.py, et les résultats de l'évaluation seront enregistrés sous « logs/your-checkpoint-prefix ». enregistrer'.
Les résultats présentés ci-dessous indiquent que la co-formation pourrait préserver la majeure partie des capacités du squelette VLM sur les tâches VL, tout en perdant un peu de performances sur les tâches du robot.
utiliser
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
pour lancer le co-train RoboFlamingo avec CoCO, VQAV2 et CALVIN. Vous devez mettre à jour les chemins CoCO et VQA dans get_coco_dataset et get_vqa_dataset dans robot_flamingo/data/data.py .
| Diviser | SR 1 | RS 2 | RS 3 | SR 4 | SR 5 | Len moy. |
|---|---|---|---|---|---|---|
| Co-train | ABC->D | 82,9% | 63,6% | 45,3% | 32,1% | 23,4% |
| Affiner | ABC->D | 82,4% | 61,9% | 46,6% | 33,1% | 23,5% |
| Co-train | ABCD->D | 95,7% | 85,8% | 73,7% | 64,5% | 56,1% |
| Affiner | ABCD->D | 96,4% | 89,6% | 82,4% | 74,0% | 66,2% |
| Co-train | ABCD->D (Enrichir) | 67,8% | 45,2% | 29,4% | 18,9% | 11,7% |
| Affiner | ABCD->D (Enrichir) | 72,0% | 48,0% | 29,9% | 21,1% | 14,4% |
| coco | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | MÉTÉORE | ROUGE_L | Cidre | PIMENTER | Acc | |
| Affiner (3B, zéro-shot) | 0,156 | 0,051 | 0,018 | 0,007 | 0,038 | 0,148 | 0,004 | 0,006 | 4.09 |
| Affiner (3B, 4 plans) | 0,166 | 0,056 | 0,020 | 0,008 | 0,042 | 0,158 | 0,004 | 0,008 | 3,87 |
| Co-Train (3B, tir nul) | 0,225 | 0,158 | 0,107 | 0,072 | 0,124 | 0,334 | 0,345 | 0,085 | 36.37 |
| Original Flamingo (80B, affiné) | - | - | - | - | - | - | 1.381 | - | 82,0 |
Le logo est généré à l'aide de MidJourney
Ce travail utilise le code des projets et ensembles de données open source suivants :
Original : https://github.com/mees/calvin Licence : MIT
Original : https://github.com/openai/CLIP Licence : MIT
Original : https://github.com/mlfoundations/open_flamingo Licence : MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


