MambaTransformer
1.0.0

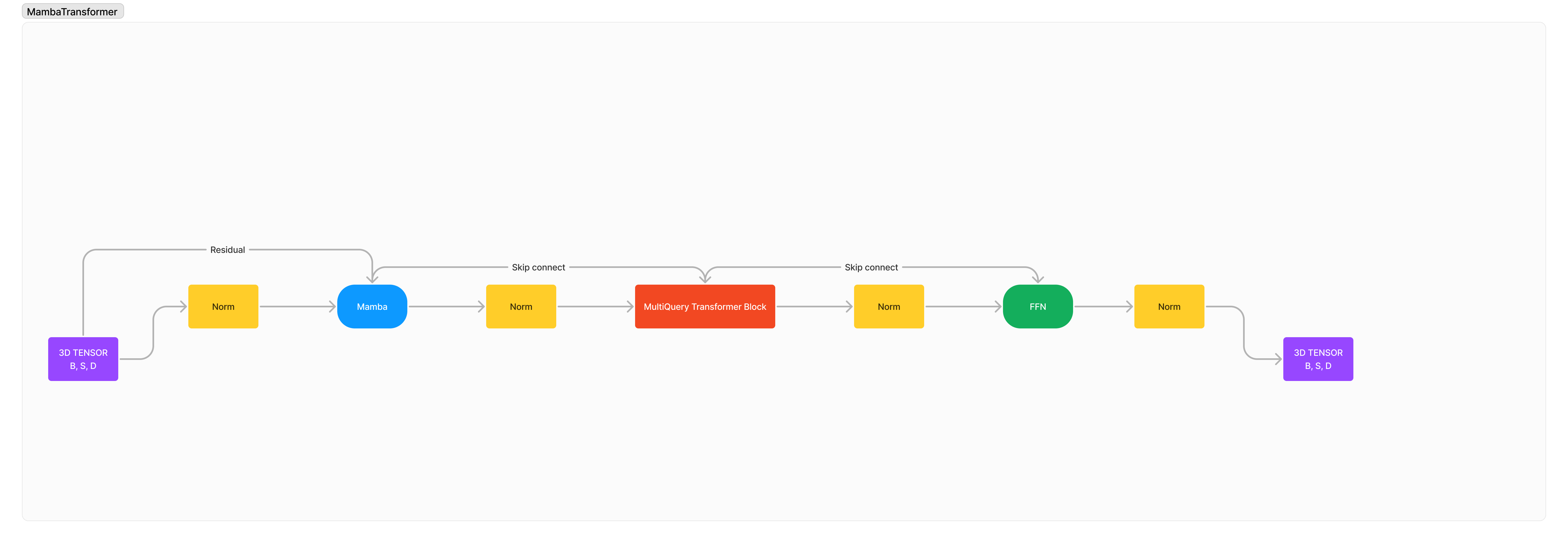
Intégration de Mamba/SSM avec Transformer pour un contexte long amélioré et une modélisation de séquence de haute qualité.
Il s'agit d'une architecture 100% nouvelle que j'ai conçue pour combiner les forces et les faiblesses des SSM et d'Attention pour une toute nouvelle architecture avancée dans le but de dépasser nos anciennes limites. Vitesse de traitement plus rapide, longueurs de contexte plus longues, moins de perplexité sur de longues séquences, raisonnement amélioré et supérieur tout en restant petit et compact.
L'architecture est essentiellement la suivante : x -> norm -> mamba -> norm -> transformer -> norm -> ffn -> norm -> out .
J'ai ajouté de nombreuses normalisations car je pense que par défaut, la stabilité de la formation serait gravement dégradée en raison de l'intégration de 2 architectures étrangères.
pip3 install mambatransformer
import torch
from mamba_transformer import MambaTransformer
# Generate a random tensor of shape (1, 10) with values between 0 and 99
x = torch . randint ( 0 , 100 , ( 1 , 10 ))
# Create an instance of the MambaTransformer model
model = MambaTransformer (
num_tokens = 100 , # Number of tokens in the input sequence
dim = 512 , # Dimension of the model
heads = 8 , # Number of attention heads
depth = 4 , # Number of transformer layers
dim_head = 64 , # Dimension of each attention head
d_state = 512 , # Dimension of the state
dropout = 0.1 , # Dropout rate
ff_mult = 4 , # Multiplier for the feed-forward layer dimension
return_embeddings = False , # Whether to return the embeddings,
transformer_depth = 2 , # Number of transformer blocks
mamba_depth = 10 , # Number of Mamba blocks,
use_linear_attn = True , # Whether to use linear attention
)
# Pass the input tensor through the model and print the output shape
out = model ( x )
print ( out . shape )
# After many training
model . eval ()
# Would you like to train this model? Zeta Corporation offers unmatchable GPU clusters at unbeatable prices, let's partner!
# Tokenizer
model . generate ( text )
MIT


