toyCarIRL
1.0.0
L'apprentissage par renforcement (RL) est la forme la plus basique et la plus intuitive d'apprentissage par essais et erreurs, c'est la manière par laquelle la plupart des organismes vivants dotés d'une certaine forme de capacités de réflexion apprennent. Souvent appelé apprentissage par exploration, il s'agit de la manière par laquelle un nouveau-né humain apprend à faire ses premiers pas, c'est-à-dire en prenant d'abord des actions aléatoires, puis en comprenant lentement les actions qui conduisent au mouvement de marche vers l'avant.
Notez que cet article suppose une bonne compréhension du cadre d'apprentissage par renforcement, veuillez vous familiariser avec RL pendant les semaines 5 et 6 de ce superbe cours en ligne AI_Berkeley.
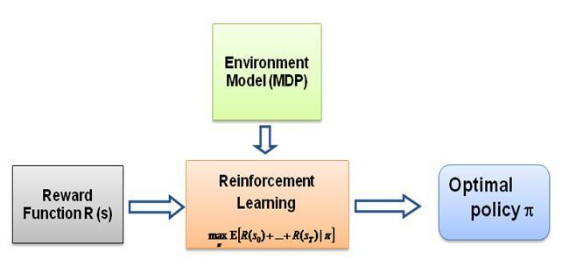
Maintenant, la question que je n'arrêtais pas de me poser est la suivante : quelle est la force motrice de ce type d'apprentissage, qu'est-ce qui force l'agent à apprendre un comportement particulier dans la manière dont il le fait. En en apprenant davantage sur RL, je suis tombé sur l'idée des récompenses . Fondamentalement, l'agent essaie de choisir ses actions de manière à maximiser les récompenses qu'il obtient de ce comportement particulier. Maintenant pour amener l'agent à adopter des comportements différents, c'est la structure de récompense qu'il faut modifier/exploiter. Mais supposons que nous connaissions uniquement le comportement de l’expert avec nous, alors comment pouvons-nous estimer la structure de récompense en fonction d’un comportement particulier dans l’environnement ? Eh bien, c'est le problème même de l'apprentissage par renforcement inverse (IRL) , où, étant donné la politique experte optimale (en réalité supposée optimale), nous souhaitons déterminer la structure de récompense sous-jacente.
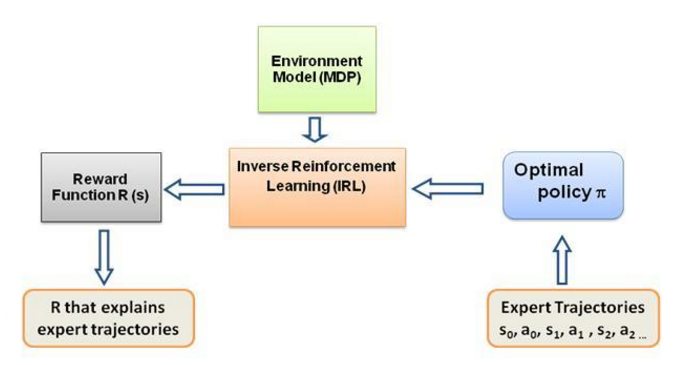
Encore une fois, il ne s'agit pas d'un article d'introduction à l'apprentissage par renforcement inverse, mais plutôt d'un tutoriel sur la façon d'utiliser/coder le cadre d'apprentissage par renforcement inverse pour votre propre problème, mais l'IRL en est le cœur même, et il est essentiel de le savoir. cela en premier. L'IRL a été largement étudié dans le passé et des algorithmes ont été développés pour cela. Veuillez consulter les articles Ng et Russell, 2000, et Abbeel et Ng, 2004 pour plus d'informations.
Cet article adapte l'algorithme d'Abbeel et Ng, 2004 pour résoudre le problème IRL.
L'idée ici est de programmer un agent simple dans un monde 2D rempli d'obstacles pour copier/cloner différents comportements dans l'environnement, les comportements sont saisis à l'aide de trajectoires expertes données manuellement par un expert humain/informatique. Cette forme d'apprentissage à partir de démonstrations d'experts est appelée apprentissage par apprentissage dans la littérature scientifique. Au cœur de celle-ci se trouve l'apprentissage par renforcement inverse, et nous essayons simplement de comprendre les différentes fonctions de récompense pour ces différents comportements.
En général, oui, c'est la même chose, ce qui signifie apprendre de la démonstration (LfD). Les deux méthodes apprennent de la démonstration, mais elles apprennent des choses différentes :
L'apprentissage par apprentissage via l'apprentissage par renforcement inverse tentera de déduire l'objectif de l'enseignant . En d’autres termes, il apprendra une fonction de récompense à partir de l’observation, qui pourra ensuite être utilisée dans l’apprentissage par renforcement. S’il découvre que l’objectif est d’enfoncer un clou avec un marteau, il ignorera les clignements et les égratignures de l’enseignant, car ils n’ont aucun rapport avec l’objectif.
L'apprentissage par imitation (c'est-à-dire le clonage comportemental) tentera de copier directement l'enseignant . Ceci peut être réalisé par le seul apprentissage supervisé. L'IA va essayer de copier chaque action, même les actions non pertinentes comme cligner des yeux ou gratter, par exemple, ou encore les erreurs. Vous pouvez également utiliser RL ici, mais seulement si vous disposez d'une fonction de récompense.
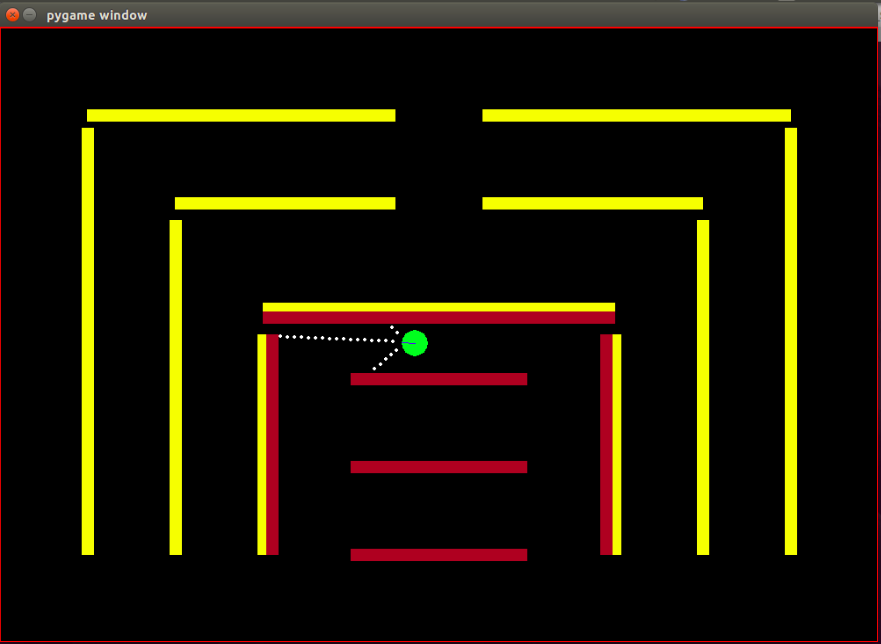
Agent : l'agent est un petit cercle vert dont la direction est indiquée par une ligne bleue.
Capteurs : l'agent est équipé de 3 capteurs de distance et de couleur, et ce sont les seules informations dont dispose l'agent sur l'environnement.
Espace d'état : l'état de l'agent se compose de 8 caractéristiques observables :
Notez que la normalisation est effectuée pour garantir que chaque valeur de caractéristique observable est dans la plage [0,1], ce qui est une condition nécessaire aux récompenses pour que l'algorithme IRL converge.
Récompenses : la récompense après chaque image est calculée comme une combinaison linéaire pondérée des valeurs de caractéristiques observées dans cette image respective. Ici, la récompense r_t dans la t ème trame est calculée par le produit scalaire du vecteur de poids w avec le vecteur de valeurs de caractéristiques dans la t ème trame, c'est-à-dire le vecteur d'état phi_t. Tel que r_t = w^T x phi_t.
Actions disponibles : à chaque nouvelle image, l'agent fait automatiquement un pas en avant , les actions disponibles peuvent soit faire tourner l'agent à gauche , à droite ou ne rien faire qui soit un simple pas en avant, notez que les actions de rotation incluent également le mouvement vers l'avant, cela n’est pas une rotation sur place.
Obstacles : l'environnement est constitué de murs rigides, volontairement colorés de différentes couleurs. L'agent possède des capacités de détection des couleurs qui l'aident à distinguer les types d'obstacles. L'environnement est conçu de cette manière pour faciliter les tests de l'algorithme IRL.
La position (état) de départ du bot est fixe, car selon l'algorithme IRL il faut que l'état de départ soit le même pour toutes les itérations.
Notez que l'algorithme RL est complètement repris de cet article de Matt Harvey avec des modifications mineures, il est donc parfaitement logique de parler des modifications que j'ai apportées, même si le lecteur est à l'aise avec RL, je recommande fortement d'y jeter un coup d'œil. ce message afin de comprendre comment se déroule l'apprentissage par renforcement.
L'environnement est considérablement modifié, l'agent ayant la capacité non seulement de détecter la distance des 3 capteurs, mais également de détecter la couleur des obstacles, lui permettant ainsi de faire la distinction entre les obstacles. De plus, l'agent est désormais plus petit et ses points de détection sont désormais plus proches afin d'obtenir plus de résolution et de meilleures performances. Les obstacles ont dû être rendus statiques pour l'instant, afin de simplifier le processus de test de l'algorithme IRL, cela pourrait très bien conduire à un surajustement des données, mais cela ne m'inquiète pas pour le moment. Comme indiqué ci-dessus, l'ensemble d'observations ou l'état de l'agent a été augmenté de 3 à 8, avec l'inclusion de la fonction de crash dans l'état de l'agent. La structure de récompense est complètement modifiée, la récompense est désormais une combinaison linéaire pondérée de ces 8 fonctionnalités, l'agent ne reçoit plus de récompense de -500 en se heurtant à des obstacles, mais la valeur de la fonctionnalité pour se heurter est de +1 et ne pas se heurter est de 0 et c'est à l'algorithme de décider quel poids doit être attribué à cette fonctionnalité en fonction du comportement de l'expert.
Comme indiqué dans le blog de Matt, le but ici n'est pas seulement d'apprendre à l'agent RL à éviter les obstacles, je veux dire pourquoi supposer quoi que ce soit sur la structure des récompenses, laisser la structure des récompenses être entièrement décidée par l'algorithme à partir des démonstrations d'experts et voir quel comportement un ensemble particulier de récompenses atteint !
Les caractéristiques ou fonctions de base phi_i qui sont fondamentalement observables dans l'état. Les fonctionnalités du problème actuel sont discutées ci-dessus dans la section espace d'état. Nous définissons phi(s_t) comme la somme de toutes les attentes de fonctionnalités phi_i telles que :
Récompenses r_t - combinaison linéaire de ces valeurs de caractéristiques observées à chaque état s_t.
Les attentes en matière de fonctionnalités mu(pi) d'une politique pi sont la somme des valeurs de fonctionnalités actualisées phi(s_t).
Les attentes en termes de fonctionnalités d'une politique sont indépendantes des poids, elles dépendent uniquement des états visités pendant l'exécution (selon la politique) et du facteur d'actualisation gamma, un nombre compris entre 0 et 1 (par exemple 0,9 dans notre cas). Pour obtenir les fonctionnalités attendues d'une politique, nous devons exécuter la politique en temps réel avec l'agent et enregistrer les états visités et les valeurs des fonctionnalités obtenues.
Les attentes des fonctionnalités de la politique de l'expert ou les attentes des fonctionnalités de l'expert mu(pi_E) sont obtenues par les actions prises en fonction du comportement de l'expert. Nous exécutons essentiellement cette politique et obtenons les attentes en matière de fonctionnalités comme nous le faisons avec toute autre politique. Les attentes des fonctionnalités de l'expert sont transmises à l'algorithme IRL pour trouver les poids tels que la fonction de récompense correspondant aux poids ressemble à la fonction de récompense sous-jacente que l'expert tente de maximiser (dans le langage RL habituel).
Attentes de fonctionnalités de politique aléatoire : exécutez une politique aléatoire et utilisez les attentes de fonctionnalités obtenues pour initialiser IRL.
Tenir à jour une liste des attentes en matière de fonctionnalités de politique que nous obtenons après chaque itération.
Au tout début, nous n'avons que pi ^ 1 -> les attentes en matière de fonctionnalités de politique aléatoire.
Trouvez le premier ensemble de poids de w^1 par optimisation convexe, le problème est similaire à un classificateur SVM qui tente de donner une étiquette +1 à l'expec de fonctionnalité experte. et -1 étiquette à toutes les autres attentes en matière de fonctionnalités de politique.-
tel que,
Condition de résiliation :
Maintenant, une fois que nous obtenons les poids après une itération d'optimisation, c'est-à-dire une fois que nous obtenons une nouvelle fonction de récompense, nous devons apprendre la politique à laquelle cette fonction de récompense donne lieu. Cela revient à dire : trouvez une politique qui tente de maximiser cette fonction de récompense obtenue. Pour trouver cette nouvelle politique, nous devons entraîner l'algorithme d'apprentissage par renforcement avec cette nouvelle fonction de récompense, et l'entraîner jusqu'à ce que les valeurs Q convergent, pour obtenir une estimation correcte de la politique.
Après avoir appris une nouvelle politique, nous devons tester cette politique en ligne, afin d'obtenir les fonctionnalités attendues correspondant à cette nouvelle politique. Ensuite, nous ajoutons ces nouvelles attentes de fonctionnalités à notre liste d'attentes de fonctionnalités et poursuivons sans la prochaine itération de l'algorithme IRL jusqu'à la convergence.
Essayons maintenant de comprendre le code. Veuillez trouver le code complet dans ce dépôt git. Il y a principalement 3 fichiers dont vous devez vous soucier :
manualControl.py - pour obtenir les attentes en matière de fonctionnalités de l'expert en déplaçant manuellement l'agent. Exécutez "python3 manualControl.py", attendez que l'interface graphique se charge, puis utilisez vos touches fléchées pour commencer à vous déplacer. Donnez-lui le comportement que vous souhaitez qu'il copie (notez que le comportement que vous attendez de lui doit être raisonnable avec l'espace d'état donné). Une bonne astuce serait de vous mettre à la place de l'agent et de vous demander si vous serez capable de distinguer le comportement donné en fonction de l'espace d'état actuel uniquement. Voir le fichier source pour plus de détails.
toy_car_IRL.py - le fichier principal, c'est là que repose le code IRL. Jetons un coup d'œil au code étape par étape.
{% résumé 51542f27e97eac1559a00f06b757df1a %}
Importez les dépendances et définissez les paramètres importants, modifiez le COMPORTEMENT selon vos besoins. FRAMES est le nombre d'images que vous souhaitez que l'algorithme RL exécute. 100K, c'est bien et prend environ 2 heures.
{% résumé 49b602b9a3090773d492310175bb2e3f %}
Créez la classe irlAgent facile à utiliser, qui prend en compte les comportements aléatoires et experts, ainsi que les autres paramètres importants, comme indiqué.
{% résumé bc17c06a07ea3b915827e89f3c13a2ae %}
La fonction getRLAgentFE utilise l'IRL_helper de l'apprenant par renforcement pour former un nouveau modèle et obtenir les attentes en matière de fonctionnalités en jouant ce modèle pendant 2 000 itérations. Il renvoie essentiellement les attentes en matière de fonctionnalités pour chaque ensemble de poids (W) obtenu.
{% essentiel ce0ef99adc652c7469f1bc4303a3af41 %}
Mettre à jour le dictionnaire dans lequel nous conservons nos politiques obtenues et leurs valeurs t respectives. Où t = (weights.tanspose)x (expert-newPolicy).
{% essentiel be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
L'implémentation de l'algorithme IRL principal, discutée ci-dessus. {% résumé 9faee18596467ee33ac5d91fd0cb675f %}
L'optimisation convexe pour mettre à jour les poids lors de la réception d'une nouvelle politique, attribue essentiellement l'étiquette +1 à la politique experte et l'étiquette -1 à toutes les autres politiques et optimise les poids sous les contraintes mentionnées. Pour en savoir plus sur cette optimisation, visitez le site
{% résumé 30cf6c59b9915054f3cf6d278f8f8a11 %}
Créez un irlAgent et transmettez les paramètres souhaités, sélectionnez le type de comportement expert pour lequel vous souhaitez connaître les poids, puis exécutez la fonction optimalWeightFinder(). Notez que j'ai déjà obtenu les fonctionnalités attendues pour les comportements rouge, jaune et marron. Une fois l'algorithme terminé, vous obtiendrez une liste de poids dans « poids-rouge/jaune/brun.txt », avec le COMPORTEMENT sélectionné respectif. Maintenant, pour sélectionner le meilleur comportement possible parmi tous les poids obtenus, lisez les modèles enregistrés dans le répertoire Saved-models_BEHAVIOR/evaluatedPolicies/, les modèles sont enregistrés au format suivant 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ numéro d'itération+ '-164-150-100-50000-100000' + '.h5' . En gros vous obtiendrez différents poids pour différentes itérations, jouez d'abord les modèles pour découvrir le modèle qui fonctionne le mieux, puis notez le numéro d'itération de ce modèle, les poids obtenus correspondant à ce numéro d'itération sont les poids qui vous rapprochent le plus de l'expert. comportement.
Et puis il y a des fichiers que vous n'avez probablement pas besoin de mettre à jour/modifier, du moins pour le contenu de cet article -
Après environ 10 à 15 itérations, l'algorithme converge dans les 4 comportements différents choisis, j'ai obtenu les résultats suivants :
| Poids | j'adore le jaune | J'aime Brun | J'aime le rouge | J'adore le cognement |
|---|---|---|---|---|
| w1 (Dist. capteur gauche) | -0,0880 | -0,2627 | 0,2816 | -0,5892 |
| w2 (dist. du capteur central) | -0,0624 | 0,0363 | -0,5547 | -0,3672 |
| w3 (dist. capteur droit) | 0,0914 | 0,0931 | -0,2297 | -0,4660 |
| w4 (couleur noire) | -0,0114 | 0,0046 | 0,6824 | -0,0299 |
| w5 (couleur jaune) | 0,6690 | -0,1829 | -0,3025 | -0,1528 |
| w6 (couleur marron) | -0,0771 | 0,6987 | 0,0004 | -0,0368 |
| w7 (couleur rouge) | -0,6650 | -0,5922 | 0,0525 | -0,5239 |
| w8 (crash) | -0,2897 | -0,2201 | -0,0075 | 0,0256 |
Une valeur négative élevée est attribuée au poids qui appartient à la fonction de heurt dans les trois premiers comportements, car ces 3 comportements experts ne souhaitent pas que l'agent se heurte à des obstacles. Alors que le poids de la même fonctionnalité dans le dernier comportement, à savoir le bot Nasty, est positif, car le comportement expert préconise le bumping.
Apparemment, les poids des caractéristiques de couleur dépendent du comportement expert, élevés lorsque cette couleur est souhaitée, sinon une valeur plutôt faible/négative pour obtenir un comportement distinct.
Les pondérations des caractéristiques de distance sont très ambiguës (contre-intuitives) et il est très difficile de trouver une tendance significative dans les pondérations. La seule chose que je souhaite souligner est qu'il est même possible de distinguer les comportements dans le sens des aiguilles d'une montre et dans le sens inverse des aiguilles d'une montre dans le réglage actuel, les fonctions de distance porteront cette information.
Notez qu'il est très important de commencer par déterminer si vous, en tant qu'humain, serez capable de faire la distinction entre les comportements donnés et la disponibilité de l'ensemble d'états actuel (les observations) lors de la conception de la structure du problème. Sinon, vous pourriez simplement forcer l'algorithme à trouver des poids différents sans lui fournir complètement les informations nécessaires.
Si vous voulez vraiment vous lancer dans l'IRL, je vous recommande d'essayer d'enseigner à l'agent un nouveau comportement (vous devrez peut-être modifier l'environnement pour cela, car les comportements distincts possibles pour l'ensemble d'états actuel ont déjà été exploités, eh bien du moins selon moi).
Installez les dépendances de Pygame avec :
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
Installez ensuite Pygame lui-même :
pip3 install hg+http://bitbucket.org/pygame/pygame
Il s'agit du moteur physique utilisé par la simulation. Il vient de subir une réécriture assez importante (v5), vous devez donc récupérer l'ancienne version v4. La v4 est écrite pour Python 2, il y a donc quelques étapes supplémentaires.
Retournez chez vous ou téléchargez et récupérez Pymunk 4 :
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
Déballez-le :
tar zxvf pymunk-4.0.0.tar.gz
Mise à jour de Python 2 vers 3 :
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
Installez-le :
cd .. python3 setup.py install
Revenez maintenant à l'endroit où vous avez cloné reinforcement-learning-car et assurez-vous que tout a fonctionné avec un rapide python3 learning.py . Si vous voyez un écran apparaître avec un petit point volant autour de l'écran, vous êtes prêt à partir !
Tout d’abord, vous devez former un modèle. Cela enregistrera les poids dans le dossier saved-models . Vous devrez peut-être créer ce dossier avant d'exécuter . Vous pouvez entraîner le modèle en exécutant :
python3 learning.py
La formation d'un modèle peut prendre entre une heure et 36 heures, selon la complexité du réseau et la taille de votre échantillon. Cependant, il crachera des poids toutes les 25 000 images, ce qui vous permettra de passer à l'étape suivante en beaucoup moins de temps.
Modifiez le fichier playing.py pour modifier le nom de chemin du modèle que vous souhaitez charger. Désolé, je sais que cela devrait être un argument de ligne de commande.
Ensuite, regardez la voiture contourner les obstacles !
python3 playing.py
C'est tout ce qu'il y a à faire.


