WeClone
1.0.0
En utilisant les enregistrements de discussion WeChat pour affiner un grand modèle de langage, j'ai utilisé environ 20 000 éléments de données efficaces intégrées. Le résultat final ne peut être considéré que comme insatisfaisant, mais parfois il est vraiment drôle.
Important
Actuellement, le projet utilise par défaut le modèle chatglm3-6b et la méthode LoRA est utilisée pour affiner l'étape sft, qui nécessite environ 16 Go de mémoire vidéo. Vous pouvez également utiliser d'autres modèles et méthodes pris en charge par LLaMA Factory, qui occupent moins de mémoire vidéo. Vous devez modifier vous-même les mots d'invite système du modèle et les autres configurations associées.
Besoins estimés en mémoire vidéo :
| méthode de formation | Précision | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| Paramètres complets | 16 | 160 Go | 320 Go | 600 Go | 1200 Go | 900 Go |
| Quelques paramètres | 16 | 20 Go | 40 Go | 120 Go | 240 Go | 200 Go |
| LoRA | 16 | 16 GB | 32 Go | 80 Go | 160 Go | 120 Go |
| QLoRA | 8 | 10 Go | 16 GB | 40 Go | 80 Go | 80 Go |
| QLoRA | 4 | 6 Go | 12 Go | 24 Go | 48 Go | 32 Go |
| Requis | Au moins | recommander |
|---|---|---|
| python | 3.8 | 3.10 |
| torche | 1.13.1 | 2.2.1 |
| transformateurs | 4.37.2 | 4.38.1 |
| ensembles de données | 2.14.3 | 2.17.1 |
| accélérer | 0.27.2 | 0.27.2 |
| peft | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| Facultatif | Au moins | recommander |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| vitesse profonde | 0.10.0 | 0.13.4 |
| bits et octets | 0.39.0 | 0.41.3 |
| flash-attn | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtLes configurations liées à la formation et à l'inférence sont unifiées dans le fichier settings.json
Veuillez utiliser PyWxDump pour extraire les enregistrements de discussion WeChat. Après avoir téléchargé le logiciel et déchiffré la base de données, cliquez sur Chat Backup. Le type d'exportation est CSV. Vous pouvez exporter plusieurs contacts ou discussions de groupe. Placez ensuite le dossier csv exporté situé dans wxdump_tmp/export dans le répertoire ./data , qui est différent. Les dossiers des enregistrements de discussion des personnes sont regroupés dans ./data/csv . Les exemples de données se trouvent dans data/example_chat.csv.
Par défaut, le projet supprime les numéros de téléphone mobile, les numéros d'identification, les adresses e-mail et les adresses de sites Web des données. Il fournit également une base de données de mots interdits, block_words, dans laquelle vous pouvez ajouter des mots et des phrases qui doivent être filtrés (la phrase entière, y compris les mots interdits, sera supprimée par défaut). Exécutez le script ./make_dataset/csv_to_json.py pour traiter les données.
Lorsqu’une même personne répond successivement à plusieurs phrases, il existe trois manières de procéder :
| document | Méthode de traitement |
|---|---|
| csv_to_json.py | Connectez-vous avec des virgules |
| csv_to_json-phrase unique réponse.py (obsolète) | Seules les réponses les plus longues sont sélectionnées comme données finales |
| csv_to_json-phrase unique plusieurs tours.py | Placé dans 'l'historique' du mot d'invite |
Le premier choix est de télécharger le modèle ChatGLM3 depuis Hugging Face. Si vous rencontrez des problèmes pour télécharger le modèle Hugging Face, vous pouvez utiliser la communauté MoDELSCOPE via les méthodes suivantes. Pour une formation et une inférence ultérieures, vous devez d'abord exécuter export USE_MODELSCOPE_HUB=1 pour utiliser le modèle de la communauté MoDELSCOPE.
En raison de la grande taille du modèle, le processus de téléchargement prendra beaucoup de temps, soyez patient.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(Facultatif) Modifiez settings.json pour sélectionner d'autres modèles téléchargés localement.
Modifiez per_device_train_batch_size et gradient_accumulation_steps pour ajuster l'utilisation de la mémoire vidéo.
Vous pouvez modifier des paramètres tels que num_train_epochs , lora_rank , lora_dropout en fonction de la quantité et de la qualité de votre propre ensemble de données.
Exécutez src/train_sft.py pour affiner l'étape sft. Ma perte n'est tombée qu'à environ 3,5. Si elle est trop réduite, cela peut provoquer un surajustement.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyNote
Vous pouvez également affiner l'étape pt en premier. Il semble que l'effet d'amélioration ne soit pas évident. L'entrepôt fournit également le code pour le prétraitement et la formation de l'ensemble de données de l'étape pt.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyImportant
Il existe un risque de fermeture de compte sur WeChat. Il est recommandé d'utiliser un petit compte et doit lier une carte bancaire pour l'utiliser.
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py Par défaut, le QR code est affiché sur le terminal, il suffit de scanner le code pour vous connecter. Il peut être utilisé en chat privé ou en chat de groupe @bot.
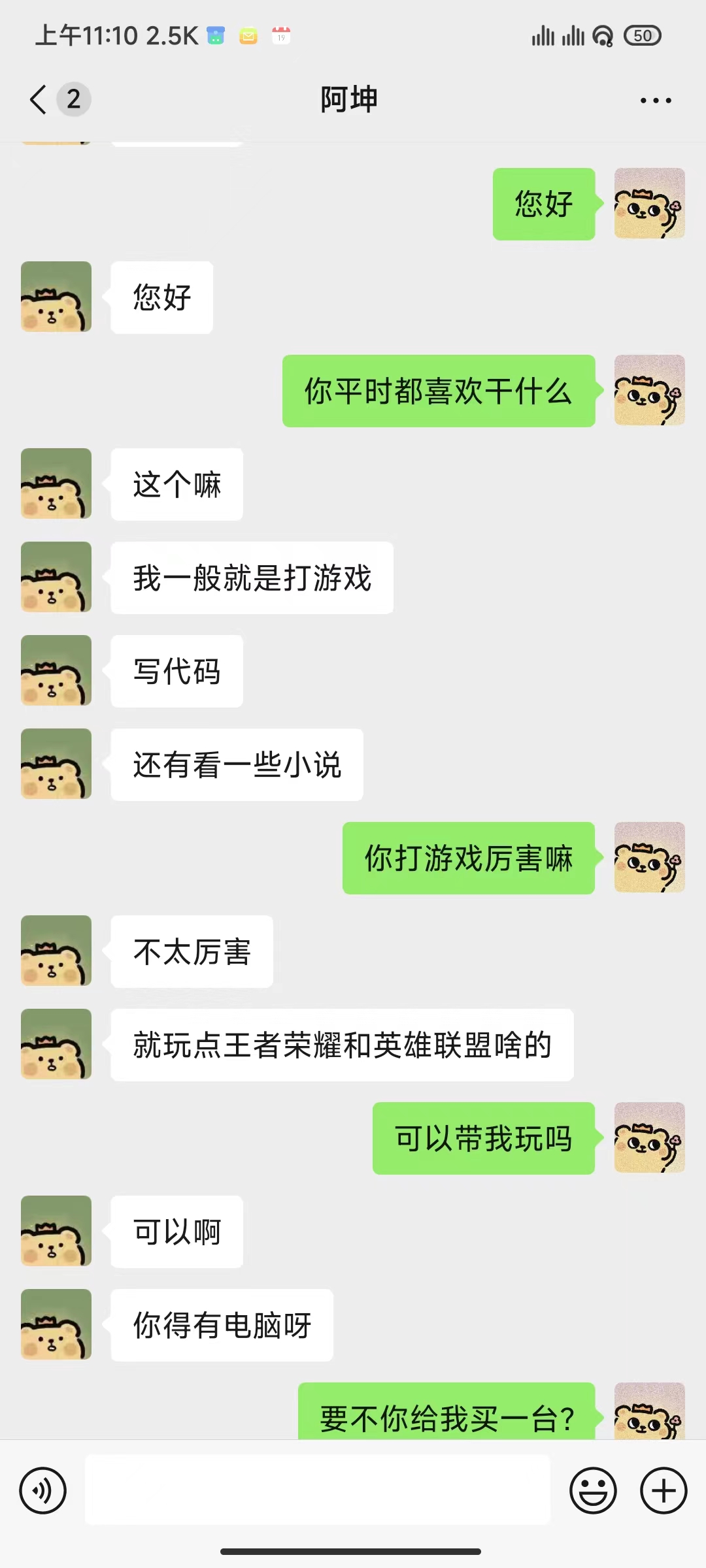

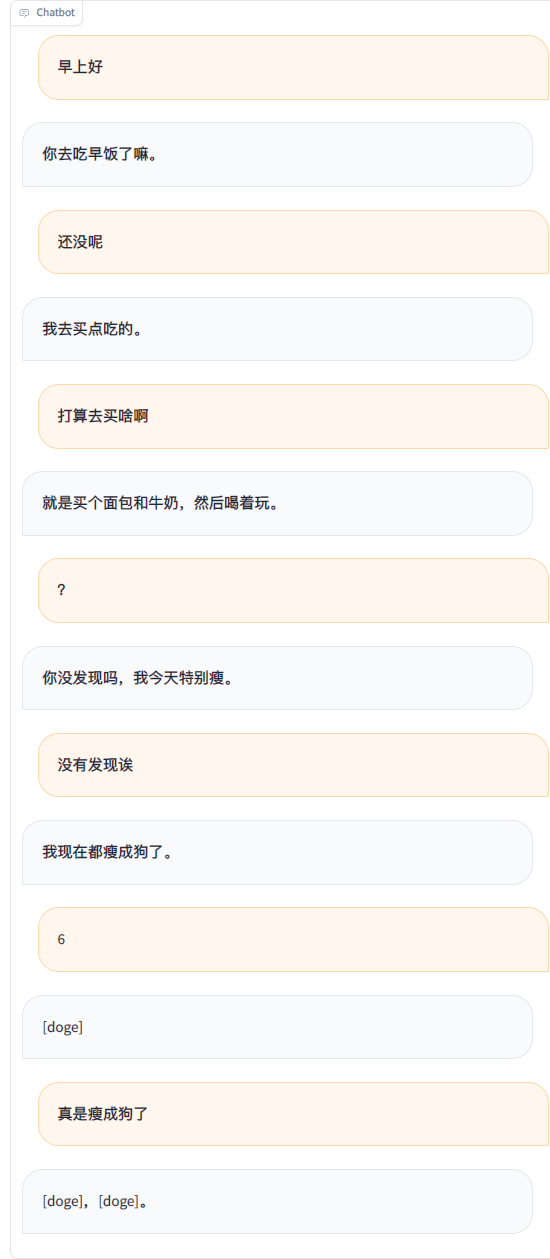
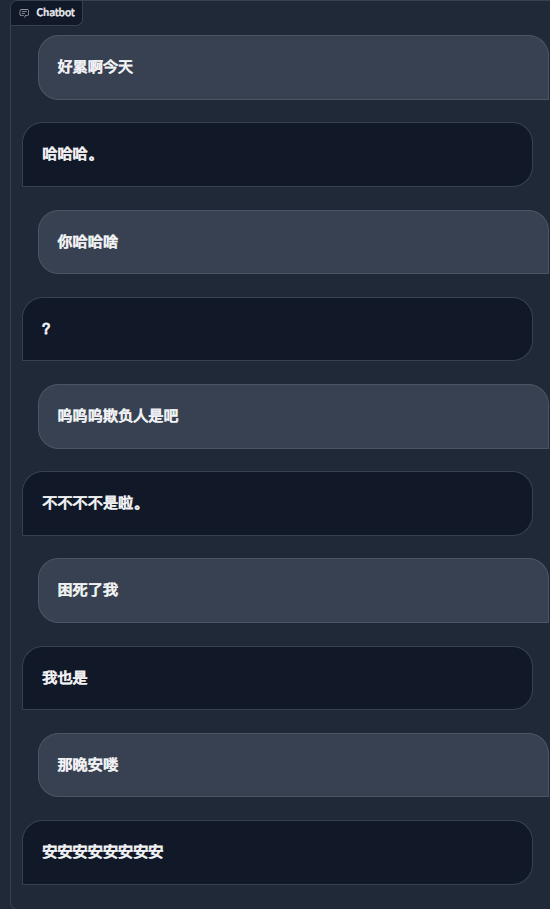
Faire
Faire


