article_spider
1.0.0
Sortie de la console :
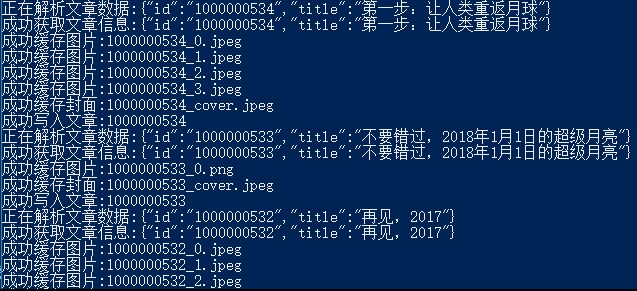
Données de l'article :
Aperçu HTML :

Actuellement, deux méthodes sont prises en charge pour explorer les articles.
Recherchez des articles via les résultats de recherche Sogou WeChat.
Avantages : Cette méthode ne nécessite pas d'authentification de connexion et est simple à utiliser.
Inconvénients : Seules les 10 dernières données peuvent être capturées.
Scénario d'utilisation : convient à la configuration de tâches d'analyse planifiées pour obtenir de grandes quantités de données.
Interceptez les paramètres de requête Ajax de la liste d'articles du compte public WeChat et simulez le client WeChat pour lire la liste d'articles et les informations sur l'article.
Avantages : Peut obtenir toutes les données d'articles des comptes publics.
Inconvénients : Vous devez vous connecter à WeChat et définir manuellement des paramètres tels que les cookies via des outils avant de pouvoir l'utiliser.
Scénario d'utilisation : capturez une grande quantité de données de comptes publics en même temps et mettez à jour les données avec la méthode Sogou une fois la capture terminée.
NodeJS & NPM, navigateur Chrome, client de bureau WeChat (Mac ou Windows)
git clone [email protected]:f111fei/article_spider.git
cd article_spider
npm install typescript -g
npm install
tsc
Définissez le fichier config.json dans le répertoire racine du projet. Les champs sont définis comme suit :
interface Config {
// 必填,要抓取的微信公众号名称。
name: string;
// 可选,若快打码平台的账号密码。用于搜狗抓取模式下自动识别验证码。
ruokuai: {
username: string;
password: string;
};
wechat: {
// 可选,要抓取文章的起始页,默认0
start?: number;
// 可选,要抓取的文章数,默认不限制
maxNum?: number;
// 可选,抓取模式(sougou, all)。默认all
mode?: string;
// 抓取模式为all时有效,公众号的biz字段,获取方法参见下面
biz?: string;
// 抓取模式为all时有效,当前cookie字段,获取方法参见下面
cookie?: string;
// 抓取模式为all时有效,当前appmsg_token字段,获取方法参见下面
appmsg_token?: string;
};
}
Si le mode d'analyse est sougou , ignorez cette section.
Pour obtenir les données de demande Ajax de la liste d'articles, vous devez capturer la demande pour obtenir les données de la liste d'articles et trouver des paramètres clés tels que biz, cookie, appmsg_token, etc. Voici comment récupérer les paramètres de la requête.
Prenons comme exemple le compte public des NASA爱好者.
1. Ouvrez le compte officiel --- coin supérieur droit --- cliquez pour afficher les messages historiques
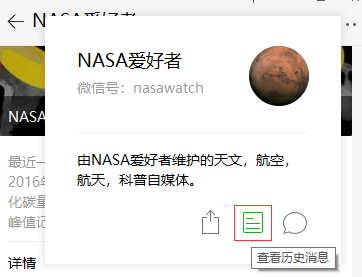
Remarque : le champ
namedans la configuration doit être rempli avec l'identifiant WeChatnasawatchici, et non avecNASA爱好者.
2. Dans la fenêtre ouverte, cliquez sur Ouvrir avec le navigateur par défaut (Chrome) dans la barre de menu et utilisez Chrome pour ouvrir la page de liste d'articles.

3. Si le lien apparaît lors de l'ouverture dans le navigateur请在微信客户端打开链接。 », indiquant que l'URL a été chiffrée. Veuillez suivre les étapes ci-dessous pour obtenir l'URL correcte. Sinon, sautez cette étape.
Fermez le client WeChat et recherchez l'emplacement du programme exécutable du client de bureau WeChat. Démarrez le programme en utilisant la ligne de commande :
Sous Windows, il s'agit généralement de :
"C:Program Files (x86)TencentWeChatWeChat.exe" --remote-debugging-port=9222
Sous Mac, il s'agit généralement de :
"/Applications/WeChat.app/Contents/MacOS/WeChat" --remote-debugging-port=9222
Suivez l'étape 1 pour ouvrir la page des messages d'historique.
Ouvrez l'URL http://127.0.0.1:9222/json à l'aide du navigateur Chrome.
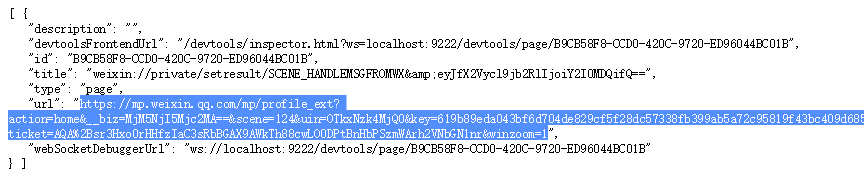
Copiez le champ URL et ouvrez-le dans un nouvel onglet, et vous verrez la page de message historique correcte.
4. Dans la page des messages d'historique, cliquez avec le bouton droit ---- Vérifiez, ouvrez les outils de développement Chrome ---- Basculez vers l'onglet Réseau ---- Actualisez le navigateur. Recherchez cookie, biz, appmsg_token et d'autres champs sur la droite et remplissez-les dans config.json .
Vous devez faire défiler la page de liste pour charger la page suivante afin de trouver la requête commençant par
https://mp.weixin.qq.com/mp/profile_ext?action=getmsget afficher ses paramètres.
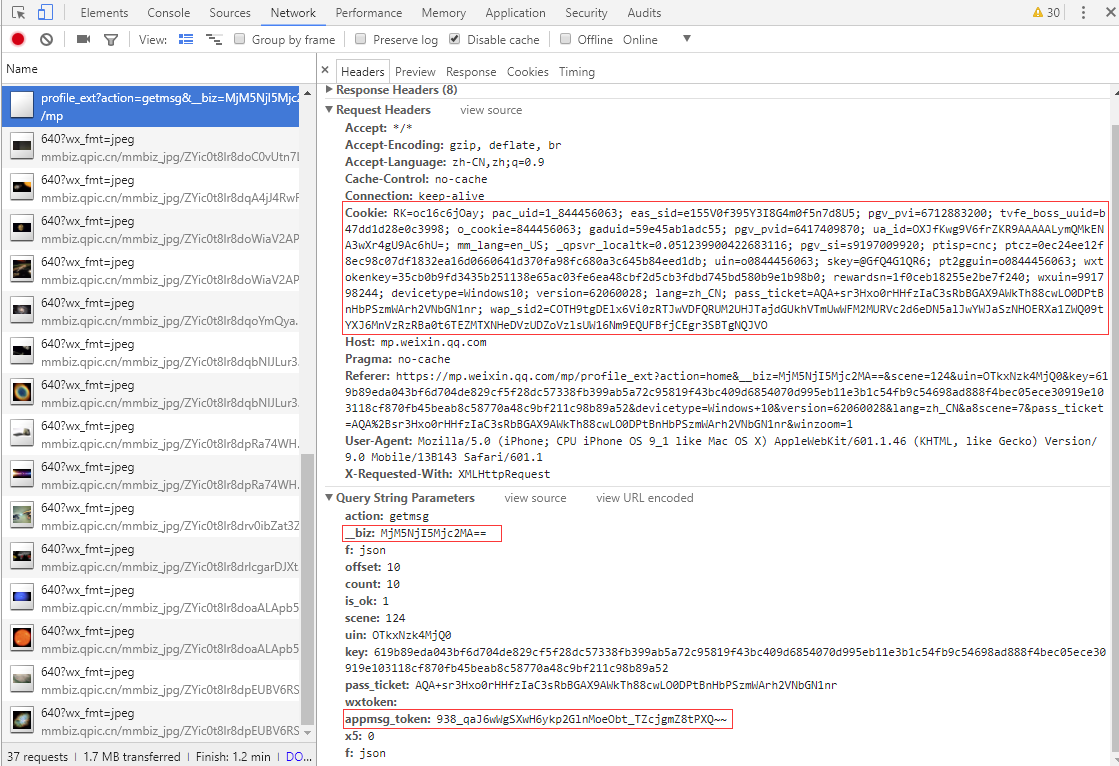
Ces champs peuvent devenir invalides après quelques heures et vous pouvez les récupérer en suivant les étapes ci-dessus.
npm start
Les informations sur l'article analysé, les images et les données de l'article original seront stockées dans le dossier db dans le répertoire racine du projet.


