liuli
v0.2.0
Expliquez-le simplement brièvement :
Collecteur : surveille les sources de lecture personnalisées telles que les comptes publics, les livres ou les sources de blogs qu'elles suivent, et les diffuse dans Liuli dans un format standard unifié en tant que source d'entrée ;
Processeur : personnalisez le contenu cible, par exemple en utilisant l'apprentissage automatique pour étiqueter automatiquement un classificateur publicitaire en fonction des données publicitaires historiques, ou en introduisant des fonctions de hook à exécuter sur les nœuds pertinents ;
Distributeur : s'appuie sur la couche d'interface pour effectuer des demandes et des réponses de données, fournit aux utilisateurs des configurations personnalisées, puis distribue automatiquement en fonction de la configuration, en diffusant des articles propres vers les clients WeChat, DingTalk, TG, RSS et même des sites Web auto-construits ;
Backer : sauvegardez les articles traités, par exemple en les conservant dans une base de données ou GitHub, etc.
Cela permet de construire un environnement de lecture propre. De manière dérivée, de nombreuses choses peuvent être faites sur la base des données obtenues. Vous souhaiterez peut-être diffuser vos idées.
Tableau de bord de progression du développement :
v0.2.0 : implémenter des fonctions de base pour garantir que les solutions pour les scénarios courants peuvent être appliquées
v0.3.0 : implémentez la personnalisation du collecteur, les utilisateurs peuvent collecter ce qu'ils voient
Afin d'améliorer la précision de la reconnaissance du modèle, j'espère que tout le monde pourra contribuer avec des échantillons publicitaires. Veuillez consulter l'exemple de fichier : .files/datasets/ads.csv. J'ai défini le format comme suit :
| titre | URL | est_processus |
|---|---|---|
| Titre de l'article publicitaire | Lien vers l'article publicitaire | 0 |
Description du champ :
titre : titre de l'article
URL : lien de l'article Si vous souhaitez utiliser l'article WeChat, veuillez d'abord vérifier s'il est invalide.
is_process : indique s'il faut effectuer un traitement d'échantillon. Remplissez 0 par défaut.
Donnons un exemple :
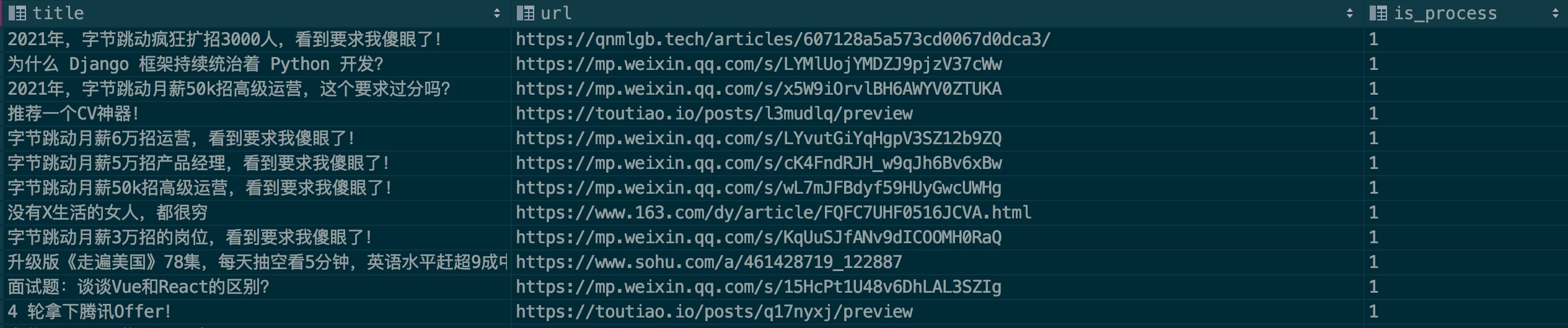
Généralement, les publicités seront placées à plusieurs reprises sur plusieurs comptes publics. Veuillez vérifier si ce dossier existe lorsque vous le remplissez. J'espère que tout le monde pourra travailler ensemble pour contribuer. Cher, venez apporter votre force grâce aux relations publiques !
Grâce aux projets open source suivants :
Flacon : framework Web
Vue : framework JavaScript progressif
Ruia : framework de robots d'exploration asynchrone (auto-développé et utilisé)
dramaturge : Récupération de données à l'aide du navigateur
Ce qui précède répertorie uniquement les dépendances open source principales. Pour plus de dépendances tierces, veuillez consulter le fichier Pipfile.
Tout PR que vous recevez est un soutien solide pour le projet Liuli . Nous sommes très reconnaissants aux développeurs suivants pour leurs contributions (sans ordre particulier) :
Bienvenue pour communiquer ensemble (suivre le groupe) :


