ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot est un robot de type chatGPT implémenté à l'aide du modèle de dialogue basé sur l'API officielle OpenAI, et est déployé sur WeChat via le framework Wechaty pour réaliser un chat robot.
ChatGPT WechatBot est une sorte de robot chatGPT basé sur l'API officielle OpenAI et utilisant le modèle de dialogue. Il est déployé sur WeChat via le framework Wechat pour réaliser un chat robot.
Remarque : Ce projet est une implémentation Win10 locale et ne nécessite pas de déploiement de serveur (si un déploiement de serveur est requis, vous pouvez déployer Docker sur le serveur)
(1), Windows10
(2), Docker 20.10.21
(3), Python3.9
(4), Wechaty 0.10.7
1. Téléchargez Docker
https://www.docker.com/products/docker-desktop/ Télécharger Docker
2. Activez la virtualisation Win10
Entrez control dans cmd pour ouvrir le panneau de configuration et entrez dans le programme, comme indiqué dans la figure ci-dessous :
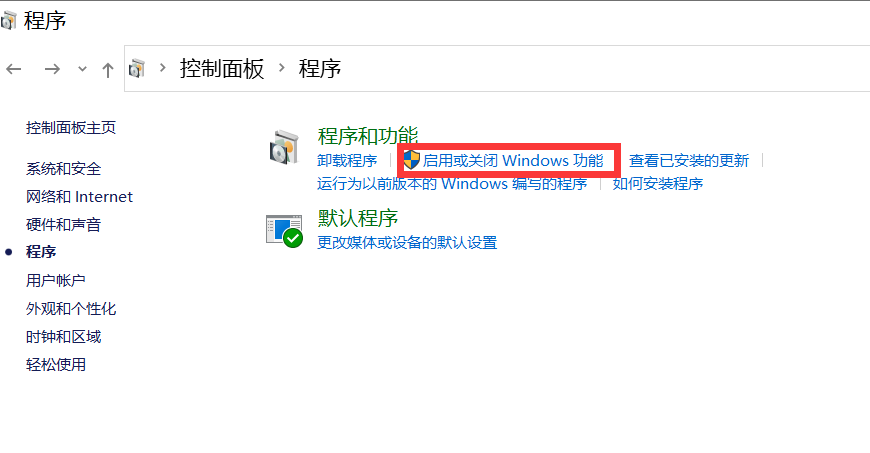
Accédez à Activer ou désactiver des fonctionnalités Windows et activez Hyper-V.
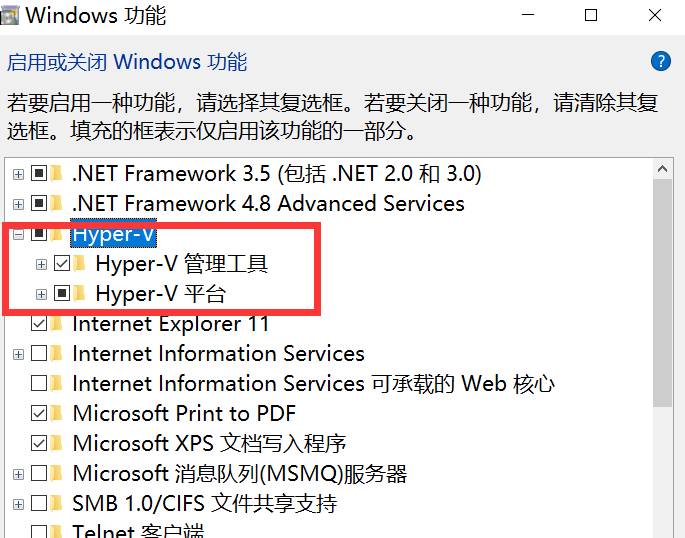
Remarque : Si votre ordinateur ne dispose pas d'Hyper-V, vous devez effectuer les opérations suivantes :
Créez un document texte, remplissez le code suivant et nommez- le Hyper.cmd
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALLExécutez ensuite ce fichier en tant qu'administrateur. Une fois l'exécution du script terminée, il y aura un nœud Hyper-V après le redémarrage de l'ordinateur.
3. Exécutez Docker
Remarque : Si ce qui suit se produit lors de la première exécution de Docker :
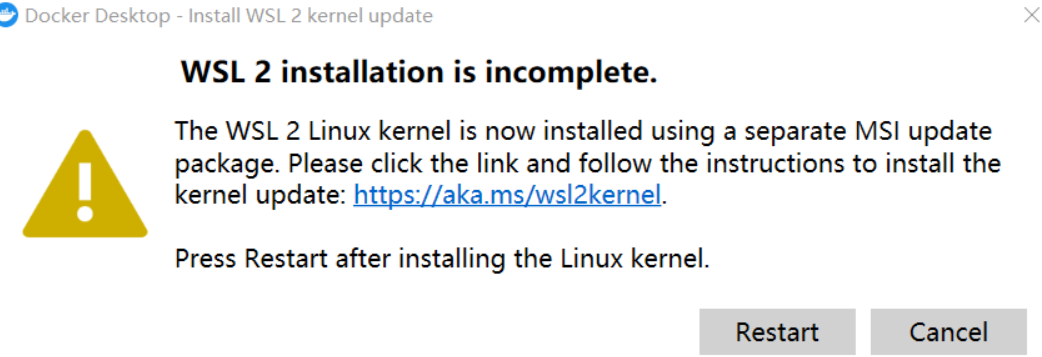
Besoin de télécharger le dernier package WSL 2
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
Après la mise à jour, vous pouvez accéder à la page principale, puis modifier les paramètres dans le moteur Docker et remplacer l'image par l'image nationale d'Alibaba Cloud :
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}De cette façon, il est plus rapide de retirer le miroir (pour les utilisateurs domestiques)
4. Extrayez l'image Wechaty :
docker pull wechaty:0 . 65Parce que lors des tests, il a été constaté que la version 0.65 de wechaty est la plus stable
Après avoir extrait l'image :
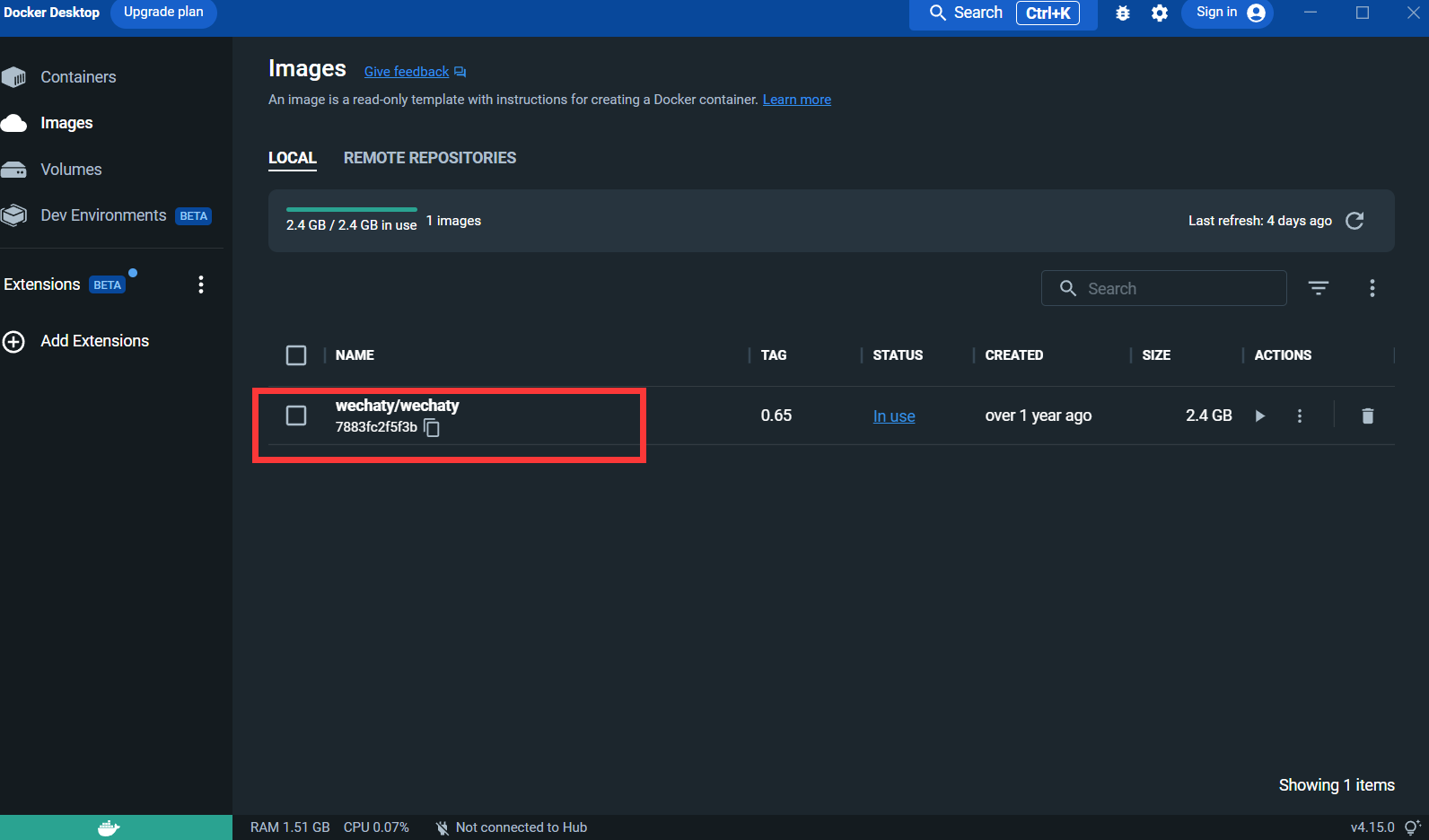
Puppet : Si vous souhaitez utiliser Wechaty pour développer un robot WeChat, vous devez utiliser un middleware Puppet pour contrôler le fonctionnement de WeChat. La traduction officielle de Puppet est actuellement Puppet. Il existe actuellement de nombreux types de Puppet. de Puppet sont les différentes fonctions du robot qui peuvent être réalisées. Par exemple, si vous souhaitez que votre robot exclue les utilisateurs d'une discussion de groupe, vous devez utiliser Puppet sous le protocole Pad.
Demande de connexion : http://pad-local.com/#/login
Remarque : Après avoir demandé un compte, vous recevrez un jeton de 7 jours.
Après avoir demandé le jeton, exécutez la commande suivante dans la fenêtre cmd :
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
Description du paramètre :
WECHATY_PUPPET_PADLOCAL_TOKEN : Demandez un bon token
**WECHATY_TOKEN ** : écrivez simplement une chaîne aléatoire dont l'unicité est garantie
WECHATY_PUPPET_SERVER_PORT : port du serveur docker
wechaty/wechaty:0.65 : version de l'image wechaty
Remarque : - "8080:8080"* est le port de votre machine locale et de votre serveur Docker. Notez que le port du serveur Docker doit être cohérent avec WECHATY_PUPPET_SERVER_PORT.
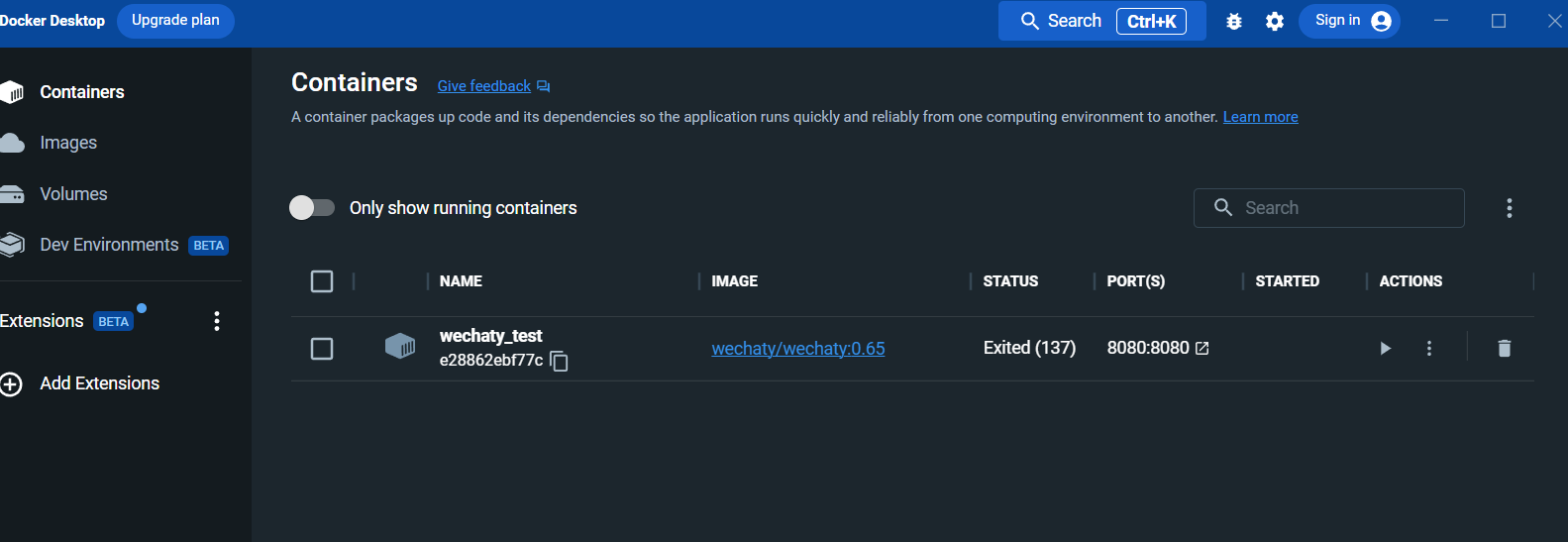
Après l'exécution, affichez le conteneur dans le panneau du bureau Docker :
Entrez dans l'interface du journal :
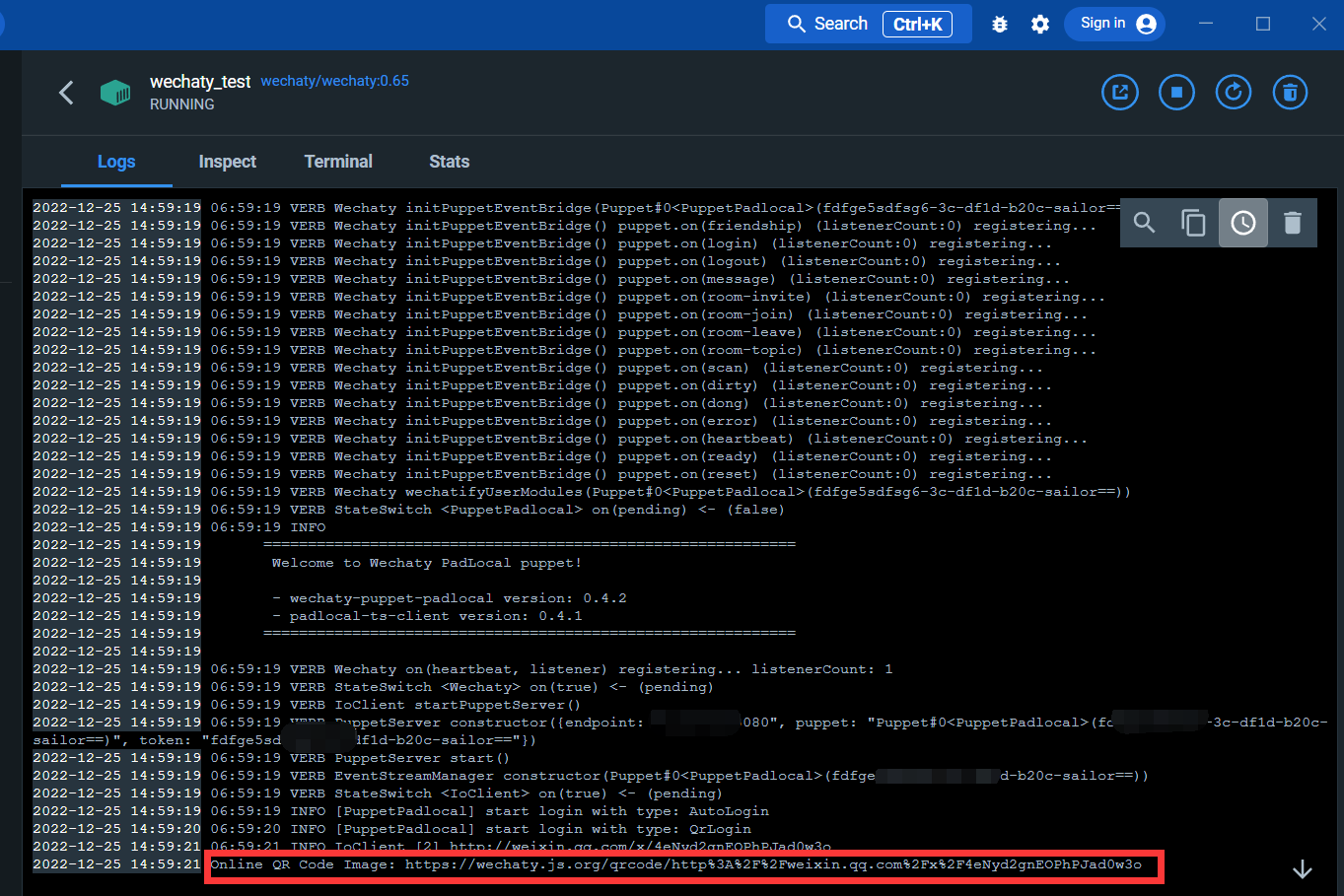
Grâce au lien ci-dessous, vous pouvez scanner le code QR pour vous connecter à WeChat
Une fois connecté, le service Docker est terminé.
Installer les bibliothèques wechaty et openai
Ouvrez cmd et exécutez la commande suivante :
pip install wechaty
pip install openaiConnectez-vous à openAI
https://beta.openai.com/
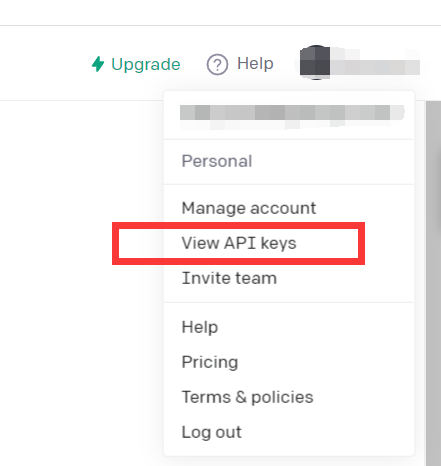
Cliquez sur Afficher les clés API
Obtenez simplement des clés API
A ce stade, l'environnement est mis en place
Vous pouvez essayer de lire ce code démo
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
Ce code appelle le modèle CPT-3, qui est le même modèle que chatGPT, et l'effet de réponse est également bon.
Le modèle GPT-3 d'openAI est présenté comme suit :
Nos modèles GPT-3 peuvent comprendre et générer du langage naturel. Nous proposons quatre modèles principaux avec différents niveaux de puissance adaptés à différentes tâches. Davinci est le modèle le plus performant et Ada est le plus rapide.
| DERNIER MODÈLE | DESCRIPTION | DEMANDE MAXIMALE | DONNÉES DE FORMATION |
|---|---|---|---|
| texte-davinci-003 | Modèle GPT-3 le plus performant. Peut effectuer toutes les tâches que les autres modèles peuvent effectuer, souvent avec une qualité supérieure, une sortie plus longue et un meilleur suivi des instructions. Prend également en charge l'insertion de complétions dans le texte. | 4 000 jetons | Jusqu'en juin 2021 |
| texte-curie-001 | Très performant, mais plus rapide et moins coûteux que Davinci. | 2 048 jetons | Jusqu'en octobre 2019 |
| texte-babbage-001 | Capable d’effectuer des tâches simples, très rapides et à moindre coût. | 2 048 jetons | Jusqu'en octobre 2019 |
| texte-ada-001 | Capable d'effectuer des tâches très simples, généralement le modèle le plus rapide de la série GPT-3 et le moins cher. | 2 048 jetons | Jusqu'en octobre 2019 |
Bien que Davinci soit généralement le plus performant, les autres modèles peuvent extrêmement bien effectuer certaines tâches avec des avantages significatifs en termes de vitesse ou de coût. Par exemple, Curie peut effectuer bon nombre des mêmes tâches que Davinci, mais plus rapidement et pour 1/10ème du coût.
Nous vous recommandons d'utiliser Davinci lors de vos expériences, car cela donnera les meilleurs résultats. Une fois que tout fonctionne, nous vous encourageons à essayer les autres modèles pour voir si vous pouvez obtenir les mêmes résultats avec une latence plus faible. Vous pourrez peut-être également améliorer l'autre. performances des modèles en les ajustant sur une tâche spécifique.
Bref, le modèle GPT-3 le plus puissant. Peut faire tout ce que d'autres modèles peuvent faire, généralement avec une qualité supérieure, une sortie plus longue et un meilleur suivi des instructions. L'insertion de complétions dans le texte est également prise en charge.
Bien que l'utilisation directe du modèle text-davinci-003 puisse obtenir l'effet de dialogue à un seul tour de chatGPT, mais afin de mieux obtenir le même effet de dialogue à plusieurs tours que chatGPT, un modèle de dialogue peut être conçu ;
Principe de base : Indiquer au modèle text-davinci-003 le contexte de la conversation en cours
Méthode de mise en œuvre : concevoir une file d'attente de mémoire de dialogue pour enregistrer les k premiers tours de dialogue du dialogue en cours, et indiquer au modèle text-davinci-003 le contenu des k premiers tours de dialogue avant de poser une question, puis obtenir la réponse actuelle via le contenu du modèle text-davinci-003
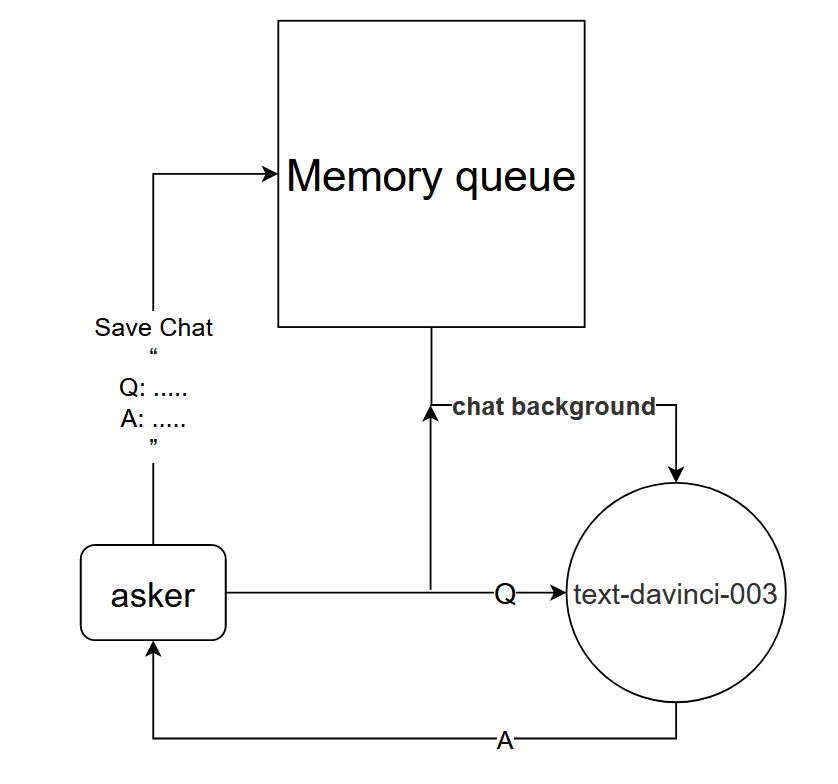
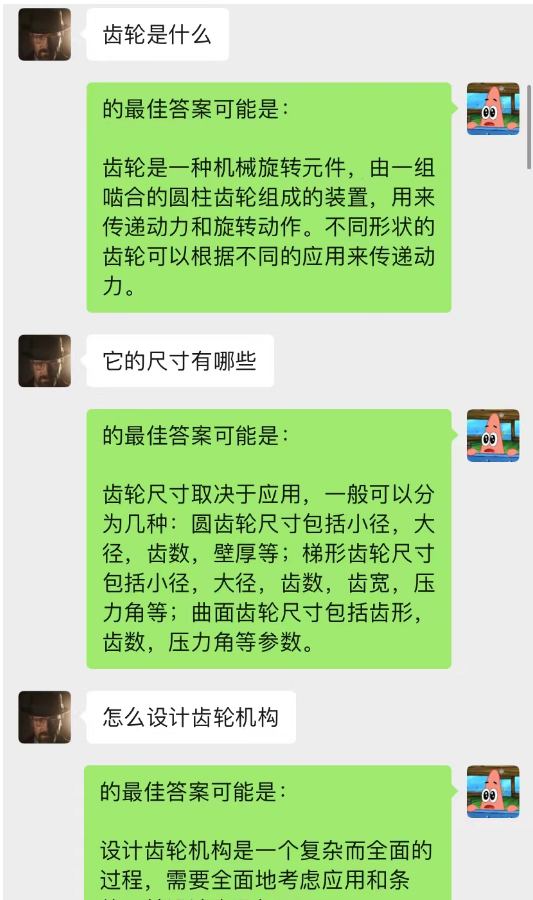
Cette méthode fonctionne étonnamment bien ! Donnez quelques enregistrements de chat
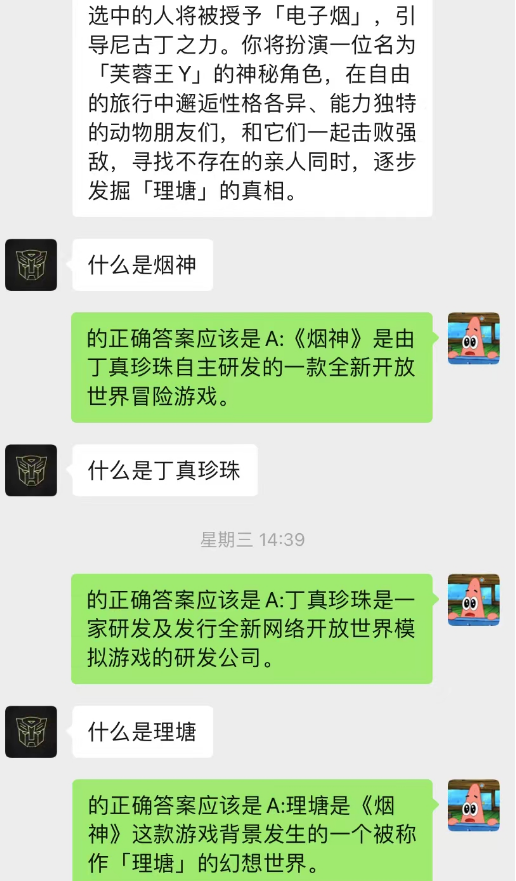
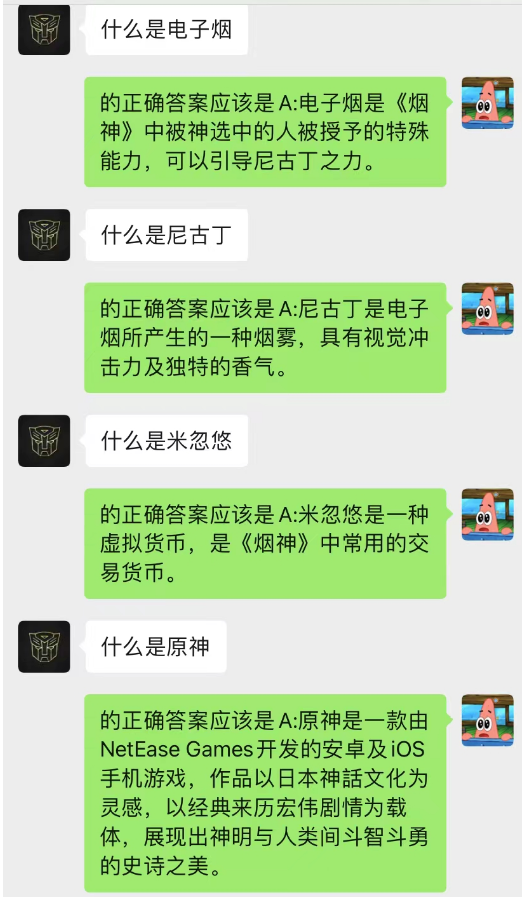
On peut voir que l’IA peut également compléter l’apprentissage situationnel via le chat en arrière-plan.
Non seulement cela, vous pouvez également réaliser la même rédaction d’articles guidée que chatGPT.
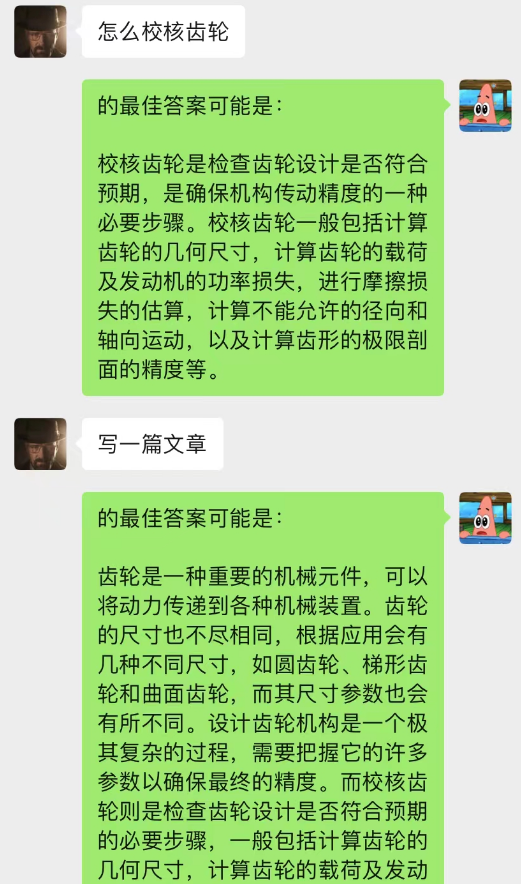
Ce modèle est une méthode que je conçois actuellement pour optimiser le modèle de dialogue en arrière-plan du chat. Sa logique de base est la même que celle du modèle de langage N-gram, sauf que N est modifié dynamiquement et que des propriétés de Markov sont ajoutées pour prédire la relation de dialogue actuelle. avec le contexte, afin de juger que la section du fond de discussion est la plus importante, puis utiliser le modèle text-davinci-003 pour donner une réponse basée sur le contenu du dialogue mémorisé le plus important combiné au problème actuel (équivalent pour laisser l'IA le faire pendant le chat, en utilisant le contenu du chat précédent)
La mise en œuvre de ce modèle nécessite une grande quantité de données pour la formation, et le code n'est pas encore terminé.
------ Creuser : Une fois le code implémenté, mettez à jour cette partie des étapes détaillées
La logique de base du projet est la suivante :
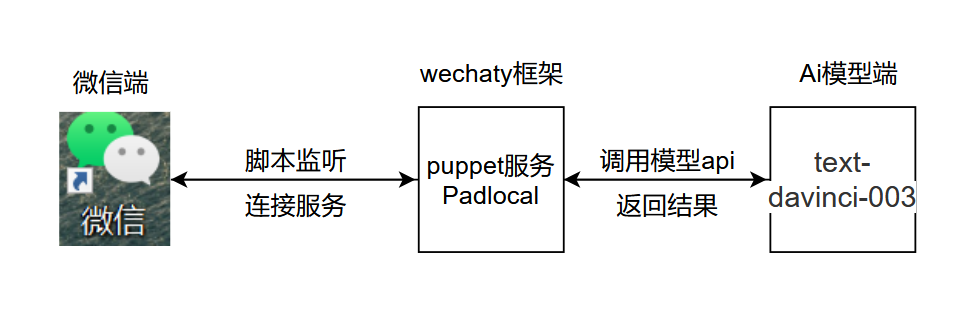 .py, ajoutez et ouvrez chatGPT.py à l'emplacement indiqué, ajoutez la clé secrète et configurez les variables d'environnement à l'emplacement indiqué
.py, ajoutez et ouvrez chatGPT.py à l'emplacement indiqué, ajoutez la clé secrète et configurez les variables d'environnement à l'emplacement indiqué

Explication du code :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
Exécuter avec succès
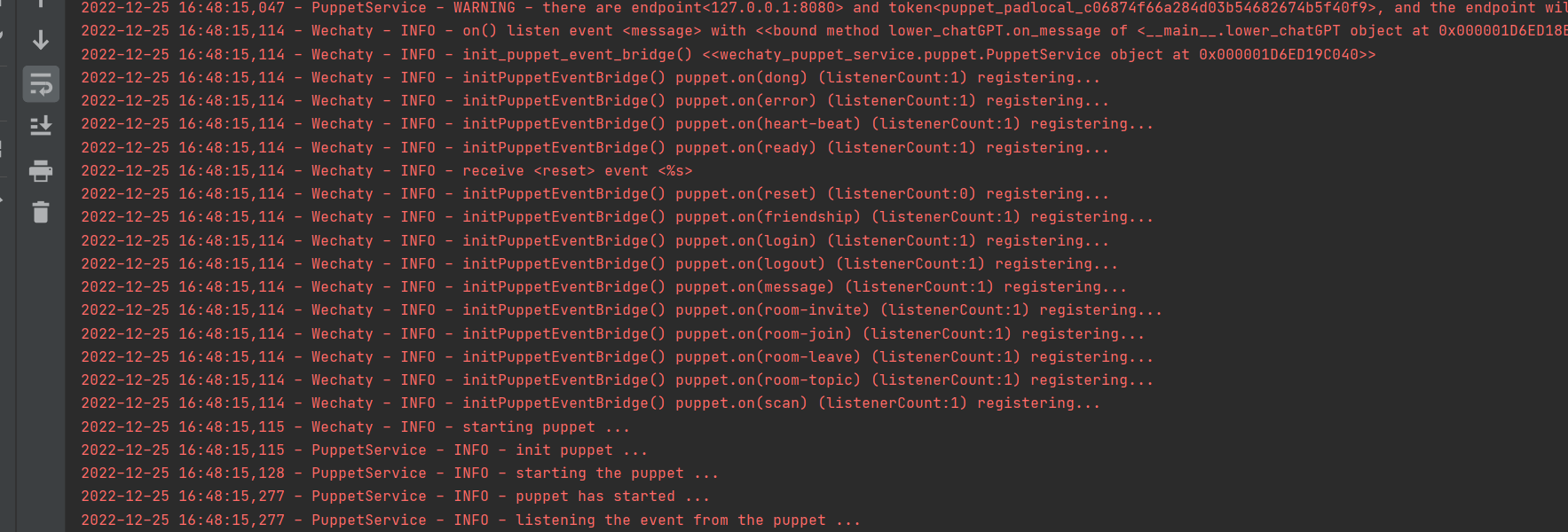
1. Connectez-vous au Docker, n'utilisez pas la connexion Wechaty en Python
2. Définissez time.sleep() dans le code pour simuler la vitesse à laquelle les gens répondent aux messages.
3. Il est préférable de ne pas utiliser une grande taille lors des tests. Il est recommandé de créer une petite taille dédiée aux tests d'IA.
Le contenu de ce projet est uniquement destiné à la recherche technique et à la vulgarisation scientifique et ne constitue aucune base concluante. Il ne fournit aucune autorisation d'application commerciale et n'est responsable d'aucun comportement.
~~e-mail : [email protected]


