glory admin
1.0.0
GloryAdmin est un framework d'arrière-plan basé sur springboot2.1.9.RELEASE et vue-admin-template ;
GloryAdmin utilise une gestion des autorisations basée sur les rôles. L'arborescence des rôles est une arborescence avec « Administrateur système » comme nœud racine, et l'arborescence des autorisations est composée de plusieurs arborescences de sous-autorisations. « Administrateur système » dispose de toutes les autorisations ; les rôles non-administrateur système peuvent afficher les informations du rôle actuel et des rôles directement subordonnés, mais peuvent uniquement ajouter, supprimer et modifier les informations des rôles directement subordonnés (subordonnés directs : A est le rôle direct). subordonné de B, alors A doit être le nœud enfant de B).
Gloire-Administrateur
| projet | technologie |
|---|---|
| Projet back-end | botte de printemps |
| Projet frontal | Interface utilisateur des éléments et Vue.js |
| base de données | MySQL |
| cache | Rédis |

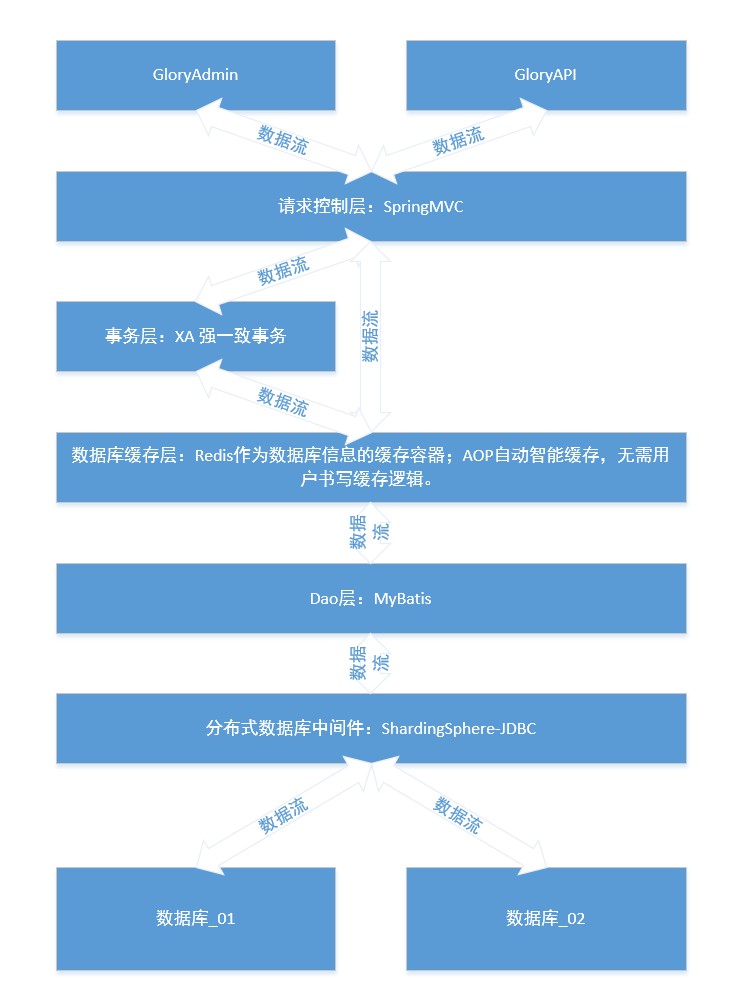
Ce projet utilise la base de données mysql, vous pouvez utiliser le script de base de données pour créer 2 bases de données multi_module_db multi_module_db_01
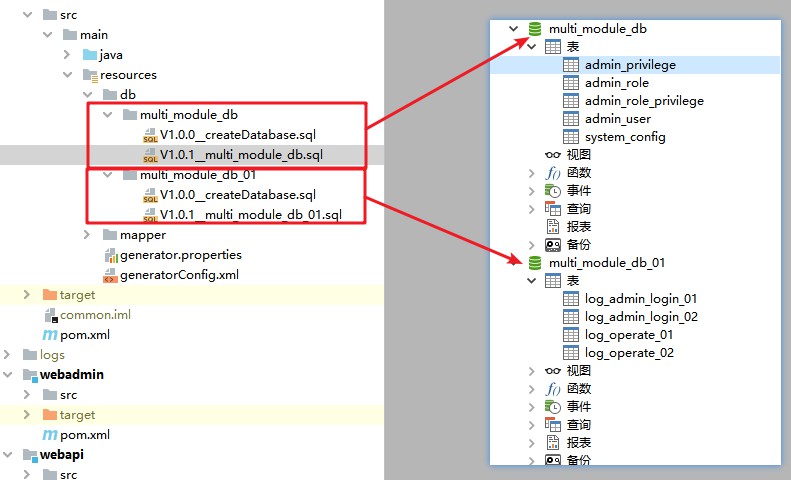
Démarrez en arrière-plan et utilisez le port 28081
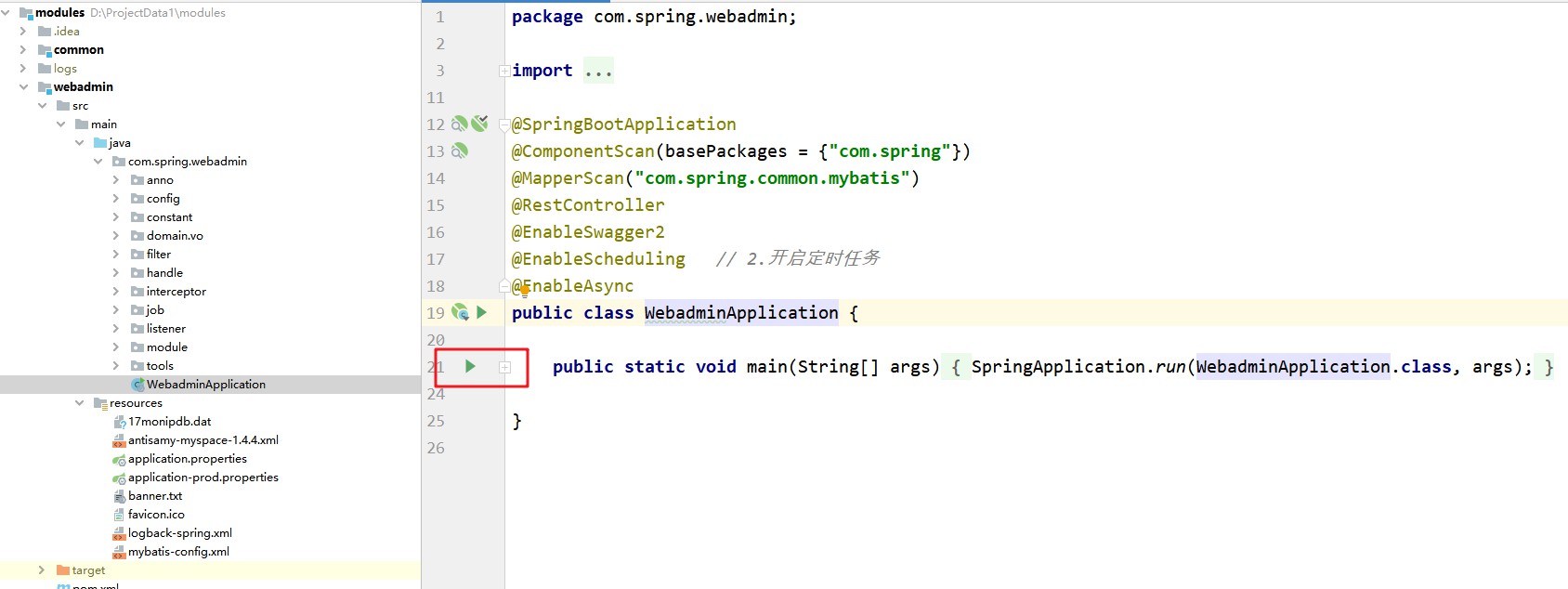
Démarrez le frontal et utilisez le port 9523
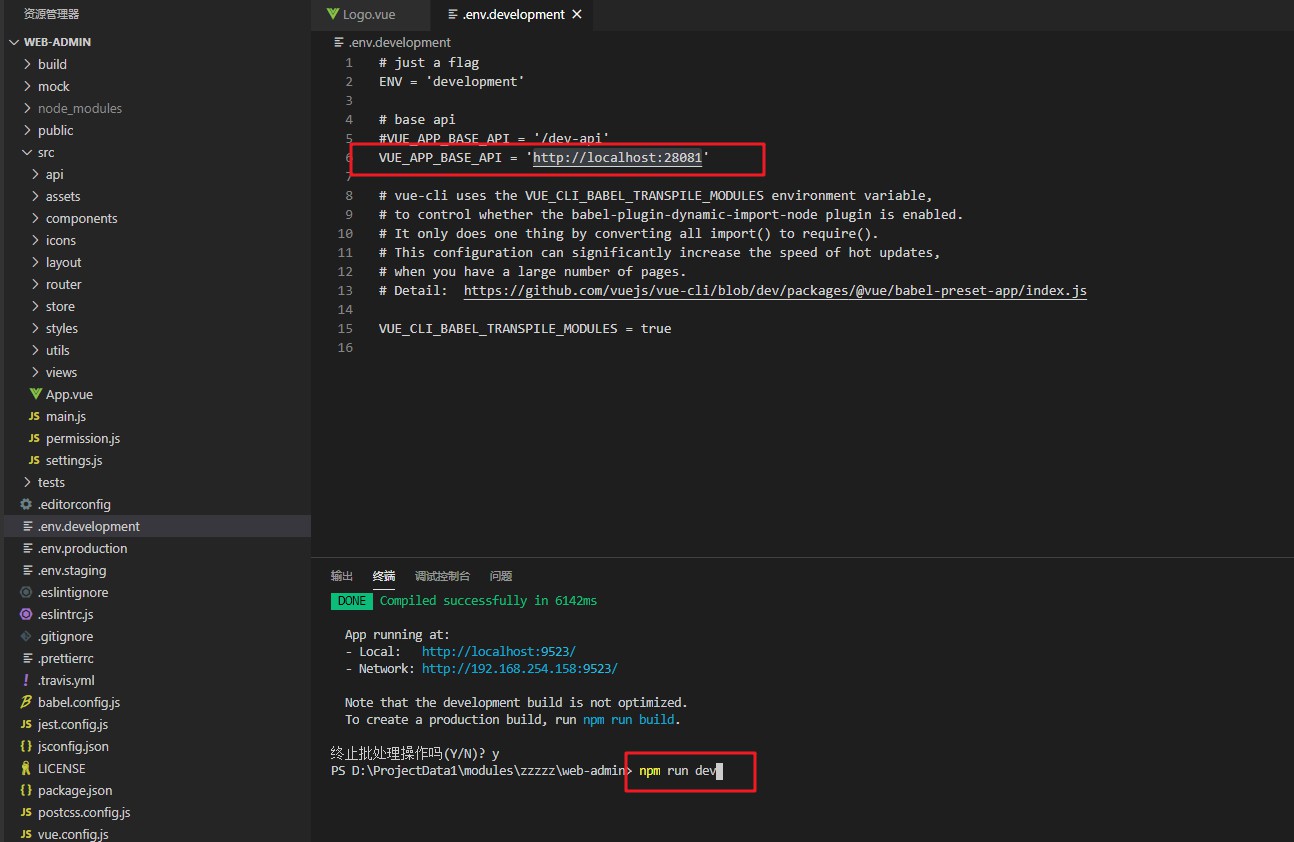
Ouvrez le navigateur et visitez http://localhost:9523 admin a123456
L'essence du sharding ou du sharding est l'échec de la loi de Moore. La solution consistant à stocker les données de manière centralisée sur un seul nœud de données a été difficile à répondre aux scénarios de données massives d'Internet en termes de performances, de disponibilité et de coûts d'exploitation et de maintenance.
Une seule base de données ne peut pas prendre en charge les entreprises existantes, c'est pourquoi des sous-bases de données et des tables ont vu le jour, et plusieurs bases de données sont utilisées pour le stockage des données. La simple compréhension de la sous-base de données et de la sous-table est que le contenu d'un panier est limité, ce qui affecte l'efficacité et la capacité de recherche. Le contenu du panier est divisé en N parties et placé dans différents paniers. Cela brise les contraintes de capacité et améliore l’efficacité des requêtes.
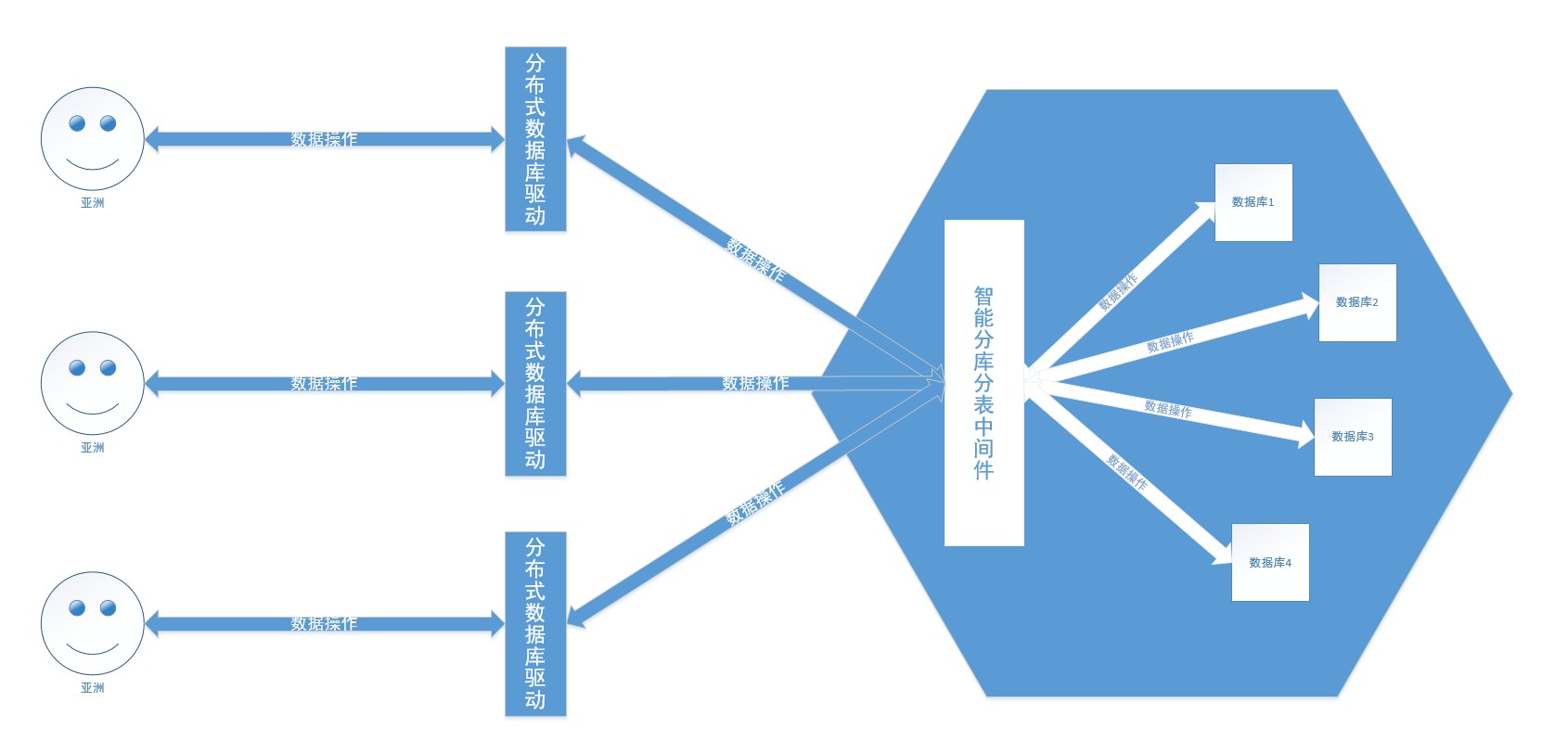
Parlons ensuite des bases de données distribuées. Les plus populaires en Chine incluent TDSQL de Tencent, OceanBase d’Alibaba, PolarDB, GaussDB de Huawei, etc. Fondamentalement, ils sont développés de manière indépendante, avec une forte cohérence et une haute disponibilité, une architecture de déploiement mondiale, une expansion horizontale distribuée illimitée, des performances élevées, des centaines de milliards d'enregistrements et des transactions entre lignes et tables sur des centaines de To de données (comme pour la patrie) . La base de données distribuée cache la stratégie de partitionnement de base de données et de partitionnement de tables, partage intelligemment les données dans des bases de données et des tables et les utilise comme si vous exploitiez une base de données.
Étant donné que les opérations de mémoire et les opérations de disque ne sont pas du tout du même ordre de grandeur, les grands projets nécessitent une couche tampon de type mémoire pour que les bases de données de type disque mettent en cache les données du disque en mémoire. La couche de mise en cache des données est utilisée pour mettre en cache les données de l'ensemble de la couche de données afin d'accélérer l'accès au site. Ce projet utilise la technologie AOP et la base de données en mémoire Redis comme couche de cache de données. Veuillez vérifier le code com/spring/common/aop/CacheDaoAspect.java pour plus de détails.
Ce projet utilise le partitionnement JDBC pour traiter la base de données et les tables de la base de données. Divisez vous-même les données selon des scénarios commerciaux.
Habituellement, les projets n'ont qu'une seule base de données et le druide d'Alibaba Cloud est plus fréquemment utilisé en Chine comme pool de connexion à la base de données. Ce projet utilise MySQL, Druid et JDBC sharding. Le principe du partage de données est de maintenir plusieurs pools de connexions à la base de données dans le programme, et chaque pool de connexions à la base de données correspond à une base de données. La base de données partitionnée et les tables partitionnées utilisent un traitement transactionnel en deux phases basé sur le protocole XA . Chemin de configuration com.spring.common.config.shardingJDBC
Fractionnement vertical : La méthode de fractionnement des activités est appelée fragmentation verticale, également connue sous le nom de fractionnement vertical. Distribuez les tables dans différentes bases de données en fonction de l'activité, répartissant ainsi la pression sur les différentes bases de données.
Répartition horizontale : elle ne se soucie pas de la classification de la logique métier, mais disperse les données dans plusieurs bibliothèques ou tables selon certaines règles via un certain champ (ou plusieurs champs) d'une certaine table. Les règles ici et l'algorithme impliqué sont appelés algorithmes de partitionnement .
( Le contenu suivant est tiré de la documentation shardingJDBC )
Correspond à PreciseShardingAlgorithm, utilisé pour gérer le scénario de partitionnement = et IN en utilisant une seule clé comme clé de partitionnement. Doit être utilisé avec StandardShardingStrategy.
Correspond au RangeShardingAlgorithm, qui est utilisé pour gérer les scénarios de partitionnement utilisant BETWEEN AND , > , < , >= et <= en utilisant une seule clé comme clé de partitionnement. Doit être utilisé avec StandardShardingStrategy.
Correspond à ComplexKeysShardingAlgorithm, qui est utilisé pour gérer les scénarios dans lesquels plusieurs clés sont utilisées comme clés de partitionnement pour le partitionnement. La logique contenant plusieurs clés de partitionnement est complexe et les développeurs d'applications doivent gérer eux-mêmes cette complexité. Doit être utilisé avec ComplexShardingStrategy.
Correspond à HintShardingAlgorithm, utilisé pour gérer les scénarios dans lesquels le partitionnement de lignes Hint est utilisé. Doit être utilisé avec HintShardingStrategy.
L'utilisateur se connecte pour obtenir le token et le stocker localement (adminLogin)
L'utilisateur envoie un jeton pour obtenir des informations utilisateur et des informations d'autorisation, et les stocke dans le magasin. Étant donné que F5 entraînera la perte du magasin, un intercepteur est ajouté à la demande frontale. S'il n'y a pas d'informations utilisateur ni d'informations d'autorisation, les informations utilisateur et les autorisations seront à nouveau obtenues (getAdminInfo).
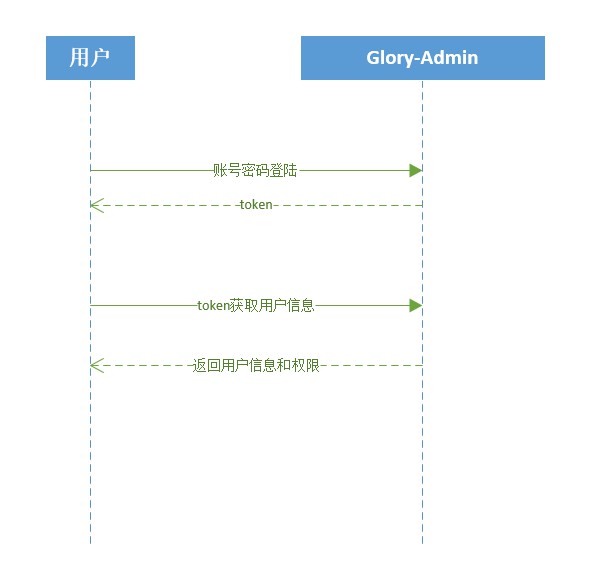
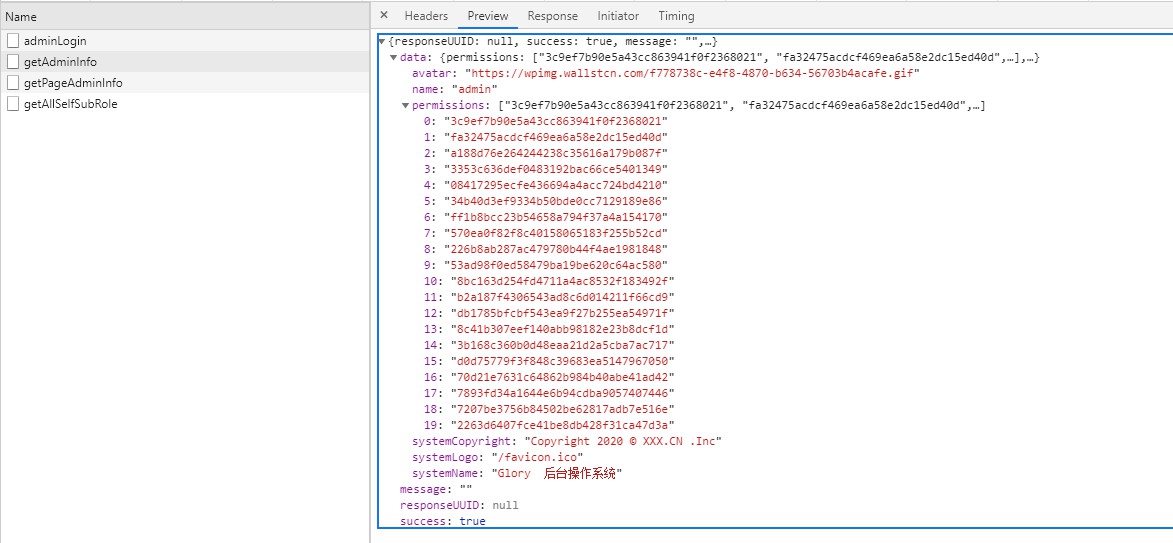
Ce qui est renvoyé ici, ce sont toutes les autorisations de l'utilisateur au lieu du rôle. L'utilisateur génère dynamiquement des routes frontales.
asyncRoutes est une autorisation générée dynamiquement. Si l'autorisation de l'utilisateur correspond à l'autorisation de la route, elle sera affichée ;
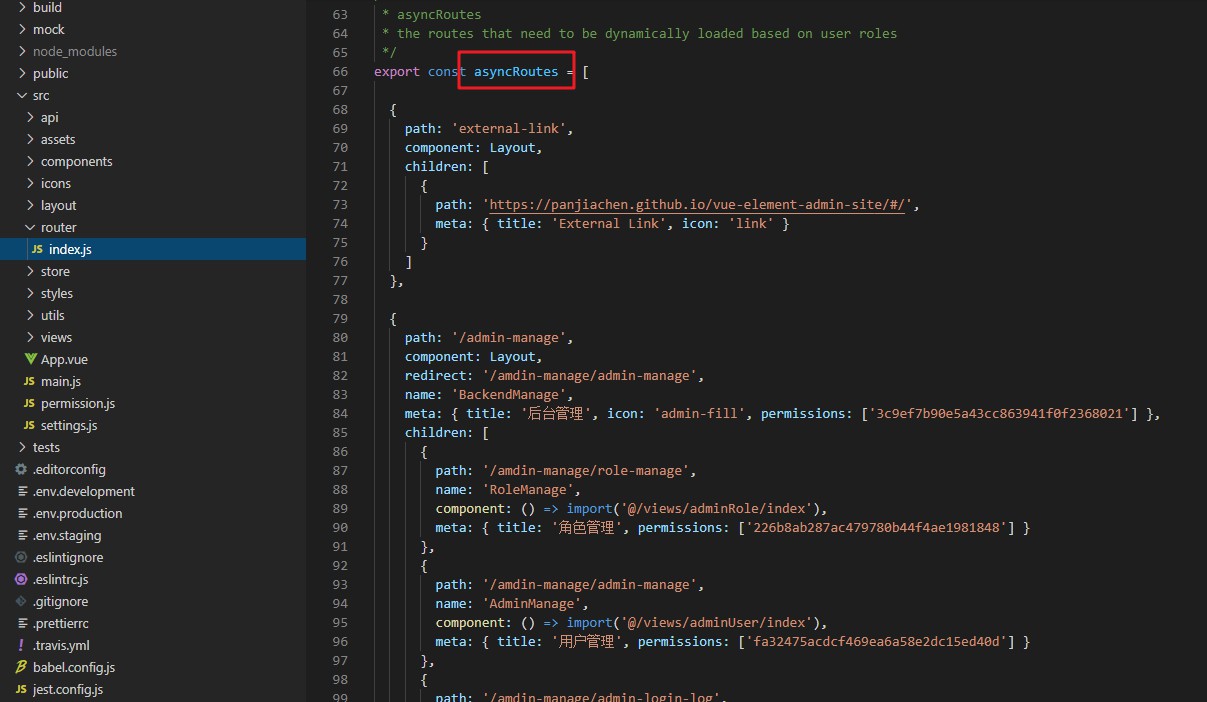
courants : opérations de données, mise en cache des données, opérations de transaction
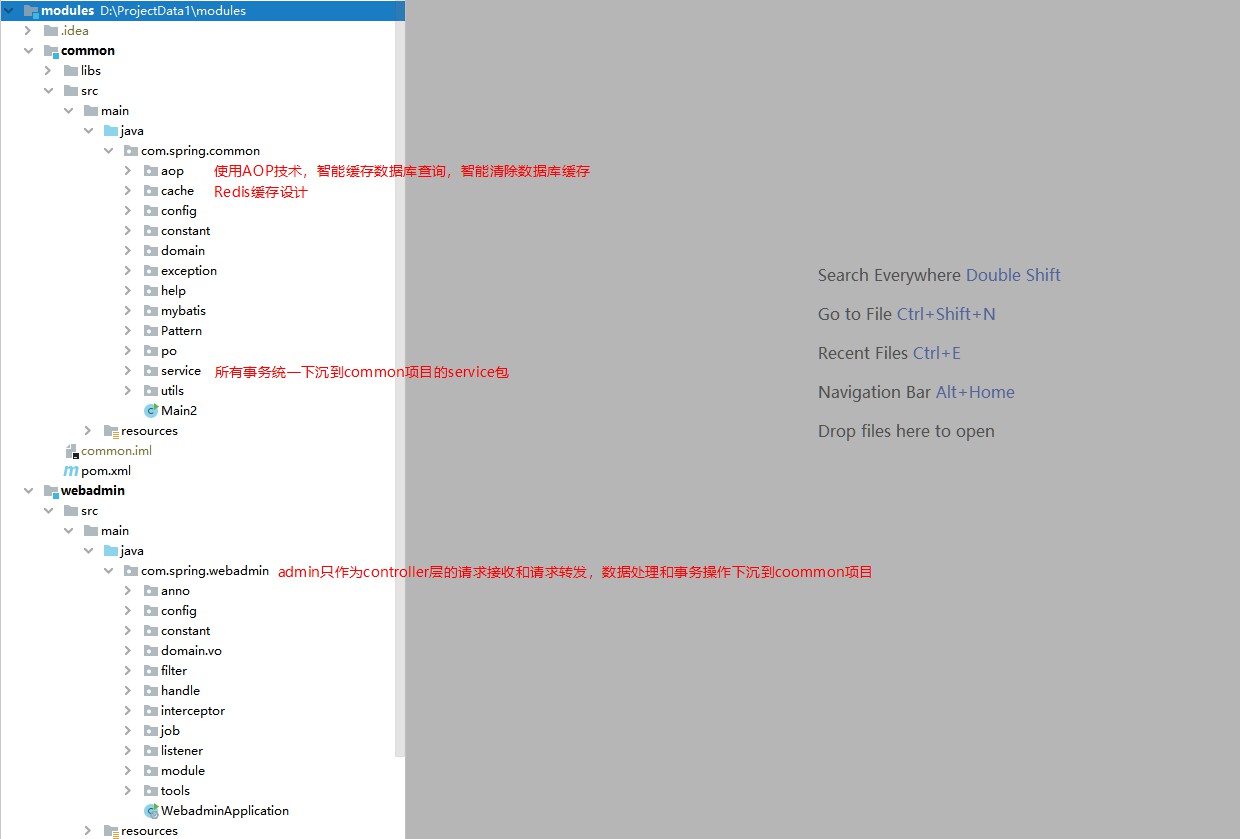
L'administrateur sert uniquement de contrôleur, utilisé pour gérer le transfert entre les demandes des utilisateurs et les activités back-end. (Pourquoi est-il conçu comme ça ?) Parce que certains systèmes middleware doivent utiliser le framework RPC pour le transfert des requêtes, et parce que certains systèmes confidentiels dédaignent d'utiliser springMVC et choisissent vertx pour développer indépendamment la couche de requête.
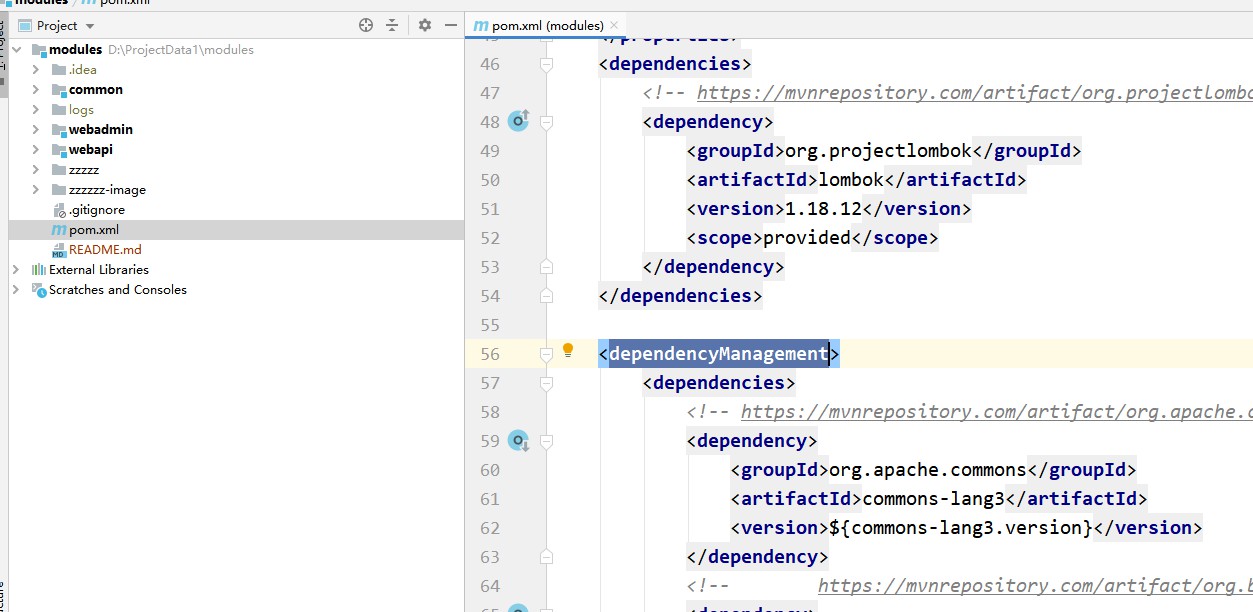
Utilisez l'héritage Maven pour gérer les dépendances du projet. Dans les modules, les dépendances sont introduites via dependencyManagement et les versions sont spécifiées. Les sous-projets héritent des modules et il n'est pas nécessaire de spécifier les versions lors de l'introduction des dépendances.
Traitement global des journaux
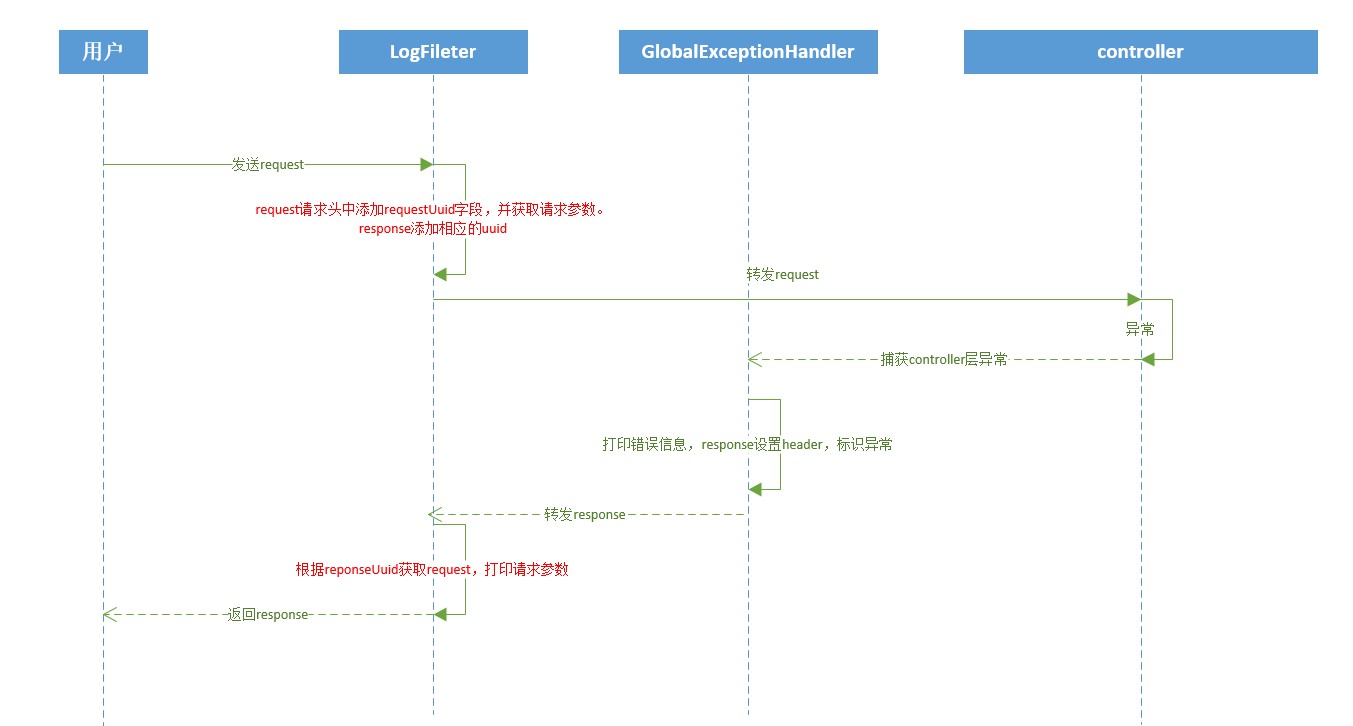
Les journaux d'opérations utilisateur utilisent des méthodes d'annotation. Si cette méthode doit enregistrer les journaux d'opérations, ajoutez simplement l'annotation **@OperateLog** au-dessus du nom de la méthode.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

