whisper.cpp
v1.7.2
Écurie: v1.7.2 / feuille de route | FAQ
Inférence à haute performance du modèle de reconnaissance de la parole automatique d'Openai (ASR):
Plateformes prises en charge:
L'ensemble de la mise en œuvre de haut niveau du modèle est contenu dans Whisper.h et Whisper.cpp. Le reste du code fait partie de la bibliothèque d'apprentissage automatique ggml .
Avoir une implémentation aussi légère du modèle permet de l'intégrer facilement dans différentes plates-formes et applications. À titre d'exemple, voici une vidéo de l'exécution du modèle sur un appareil iPhone 13 - entièrement hors ligne, sur périphérique: whisper.objc
Vous pouvez également facilement créer votre propre application vocale hors ligne: commande
Sur le silicium Apple, l'inférence fonctionne entièrement sur le GPU via le métal:
Ou vous pouvez même l'exécuter directement dans le navigateur: talk.wasm
Les opérateurs de tenseur sont fortement optimisés pour les processeurs de silicium Apple. Selon la taille du calcul, les intrinsèques SIMD ARM Neon ou les routines de cadre d'accélération CBLAS sont utilisées. Ces derniers sont particulièrement efficaces pour des tailles plus grandes, car le cadre Accelerate utilise le coprocesseur AMX à usage spécial disponible dans les produits Apple modernes.
Premier cloner le référentiel:
git clone https://github.com/ggerganov/whisper.cpp.gitNaviguer dans le répertoire:
cd whisper.cpp
Ensuite, téléchargez l'un des modèles Whisper convertis au format ggml . Par exemple:
sh ./models/download-ggml-model.sh base.enCréez maintenant l'exemple principal et transcrivez un fichier audio comme celui-ci:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav Pour une démo rapide, exécutez simplement make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
La commande télécharge le modèle base.en converti au format ggml personnalisé et exécute l'inférence sur tous les échantillons .wav dans les samples de dossier.
Pour des instructions détaillées d'utilisation, exécutez: ./main -h
Notez que l'exemple principal s'exécute actuellement uniquement avec des fichiers WAV 16 bits, assurez-vous de convertir votre entrée avant d'exécuter l'outil. Par exemple, vous pouvez utiliser ffmpeg comme ceci:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavSi vous voulez que des échantillons audio supplémentaires jouent avec, exécutez simplement:
make -j samples
Cela téléchargera quelques fichiers audio supplémentaires à partir de Wikipedia et les convertira au format WAV 16 bits via ffmpeg .
Vous pouvez télécharger et exécuter les autres modèles comme suit:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Modèle | Disque | Mem |
|---|---|---|
| minuscule | 75 MIB | ~ 273 Mo |
| base | 142 MIB | ~ 388 Mo |
| petit | 466 MIB | ~ 852 Mo |
| moyen | 1,5 gib | ~ 2,1 Go |
| grand | 2,9 Gib | ~ 3,9 Go |
whisper.cpp prend en charge la quantification entière des modèles Whisper ggml . Les modèles quantifiés nécessitent moins de mémoire et d'espace disque et en fonction du matériel peut être traité plus efficacement.
Voici les étapes de création et d'utilisation d'un modèle quantifié:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav Sur les appareils Apple Silicon, l'inférence du codeur peut être exécutée sur le moteur neuronal Apple (ANE) via Core ML. Cela peut entraîner une accélération significative - plus de x3 plus rapidement par rapport à l'exécution uniquement du processeur. Voici les instructions pour générer un modèle Core ML et l'utiliser avec whisper.cpp :
Installez les dépendances Python nécessaires pour la création du modèle Core ML:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools fonctionne correctement, veuillez confirmer que Xcode est installé et exécuter xcode-select --install pour installer les outils de ligne de commande.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper Générez un modèle Core ML. Par exemple, pour générer un modèle base.en , utilisez:
./models/generate-coreml-model.sh base.en Cela générera les models/ggml-base.en-encoder.mlmodelc
Build whisper.cpp avec le support Core ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseExécutez les exemples comme d'habitude. Par exemple:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
La première exécution sur un appareil est lente, car le service ANE compile le modèle Core ML dans un format spécifique à l'appareil. Les prochaines courses sont plus rapides.
Pour plus d'informations sur la mise en œuvre de Core ML, veuillez vous référer à PR # 566.
Sur les plates-formes qui prennent en charge OpenVino, l'inférence de l'encodeur peut être exécutée sur des appareils soutenus OpenVino, y compris les processeurs x86 et Intel (intégrés et discrets).
Cela peut entraîner une accélération significative des performances de l'encodeur. Voici les instructions pour générer le modèle OpenVino et l'utiliser avec whisper.cpp :
Tout d'abord, configurer Python Virtual Env. et installer des dépendances Python. Python 3.10 est recommandé.
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux et macOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt Générez un modèle d'encodeur OpenVino. Par exemple, pour générer un modèle base.en , utilisez:
python convert-whisper-to-openvino.py --model base.en
Cela produira GGML-Base.en-Encoder-Openvino.xml / .Bin IR Model Files. Il est recommandé de les déplacer dans le même dossier que les modèles ggml , car c'est l'emplacement par défaut que l'extension OpenVino recherchera au moment de l'exécution.
Construisez whisper.cpp avec le support OpenVino:
Téléchargez le package OpenVino à partir de la page de version. La version recommandée à utiliser est 2023.0.0.
Après avoir téléchargé et extrait le package sur votre système de développement, configurez l'environnement requis en s'approvisionnement du script SetupVars. Par exemple:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batPuis construire le projet à l'aide de cmake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseExécutez les exemples comme d'habitude. Par exemple:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
La première fois l'exécution sur un appareil OpenVino est lent, car le cadre OpenVino compilera le modèle IR (représentation intermédiaire) à un «blob» spécifique à un appareil. Ce blob spécifique à l'appareil sera mis en cache pour la prochaine exécution.
Pour plus d'informations sur la mise en œuvre de Core ML, veuillez vous référer à PR # 1037.
Avec les cartes NVIDIA, le traitement des modèles se fait efficacement sur le GPU via des Cublil et des grains CUDA personnalisés. Tout d'abord, assurez-vous que vous avez installé cuda : https://developer.nvidia.com/cuda-downloads
Maintenant, construisez whisper.cpp avec le support CUDA:
make clean
GGML_CUDA=1 make -j
Solution croisée de vendeurs qui vous permet d'accélérer la charge de travail sur votre GPU. Tout d'abord, assurez-vous que votre pilote de carte graphique prend en charge l'API Vulkan.
Construisez maintenant whisper.cpp avec le support Vulkan:
make clean
make GGML_VULKAN=1 -j
Le traitement de l'encodeur peut être accéléré sur le CPU via OpenBLAS. Tout d'abord, assurez-vous que vous avez installé openblas : https://www.openblas.net/
Construisez maintenant whisper.cpp avec le support OpenBlas:
make clean
GGML_OPENBLAS=1 make -j
Le traitement de l'encodeur peut être accéléré sur le CPU via l'interface compatible BLAS de la bibliothèque du noyau mathématique d'Intel. Tout d'abord, assurez-vous que vous avez installé les packages de course et de développement MKL d'Intel: https://www.intel.com/content/www/us/en/developer/tools/onapi/onemkl-download.html
Maintenant, construisez whisper.cpp avec le support Intel MKL Blas:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU fournit une accélération d'inférence via les noyaux CANN et AI.
Tout d'abord, vérifiez si votre appareil NPU Ascend est pris en charge:
Appareils vérifiés
| Ascendant npu | Statut |
|---|---|
| Atlas 300T A2 | Soutien |
Ensuite, assurez-vous que vous avez installé CANN toolkit . La version dure de Cann est recommandée.
Maintenant, construisez whisper.cpp avec le support cann:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
Exécutez les exemples d'inférence comme d'habitude, par exemple:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Notes:
Verified devices du tableau. Nous avons deux images Docker disponibles pour ce projet:
ghcr.io/ggerganov/whisper.cpp:main : cette image comprend le fichier exécutable principal ainsi que curl et ffmpeg . (Plateformes: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : Identique main mais compilé avec le soutien de Cuda. (Plateformes: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Vous pouvez installer des binaires prédéfinis pour Whisper.cpp ou le construire à partir de la source à l'aide de Conan. Utilisez la commande suivante:
conan install --requires="whisper-cpp/[*]" --build=missing
Pour des instructions détaillées sur la façon d'utiliser Conan, veuillez vous référer à la documentation de Conan.
Voici un autre exemple de transcription d'un discours de 3:24 minutes en environ une demi-minute sur un MacBook M1 Pro, en utilisant le modèle medium.en :
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
Ceci est un exemple naïf d'effectuer une inférence en temps réel sur l'audio de votre microphone. L'outil de flux échantillonne l'audio toutes les demi-secondes et exécute la transcription en continu. Plus d'informations sont disponibles dans le numéro 10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 L'ajout de l'argument --print-colors imprimera le texte transcrit à l'aide d'une stratégie de codage couleur expérimentale pour mettre en évidence les mots avec une confiance élevée ou faible:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors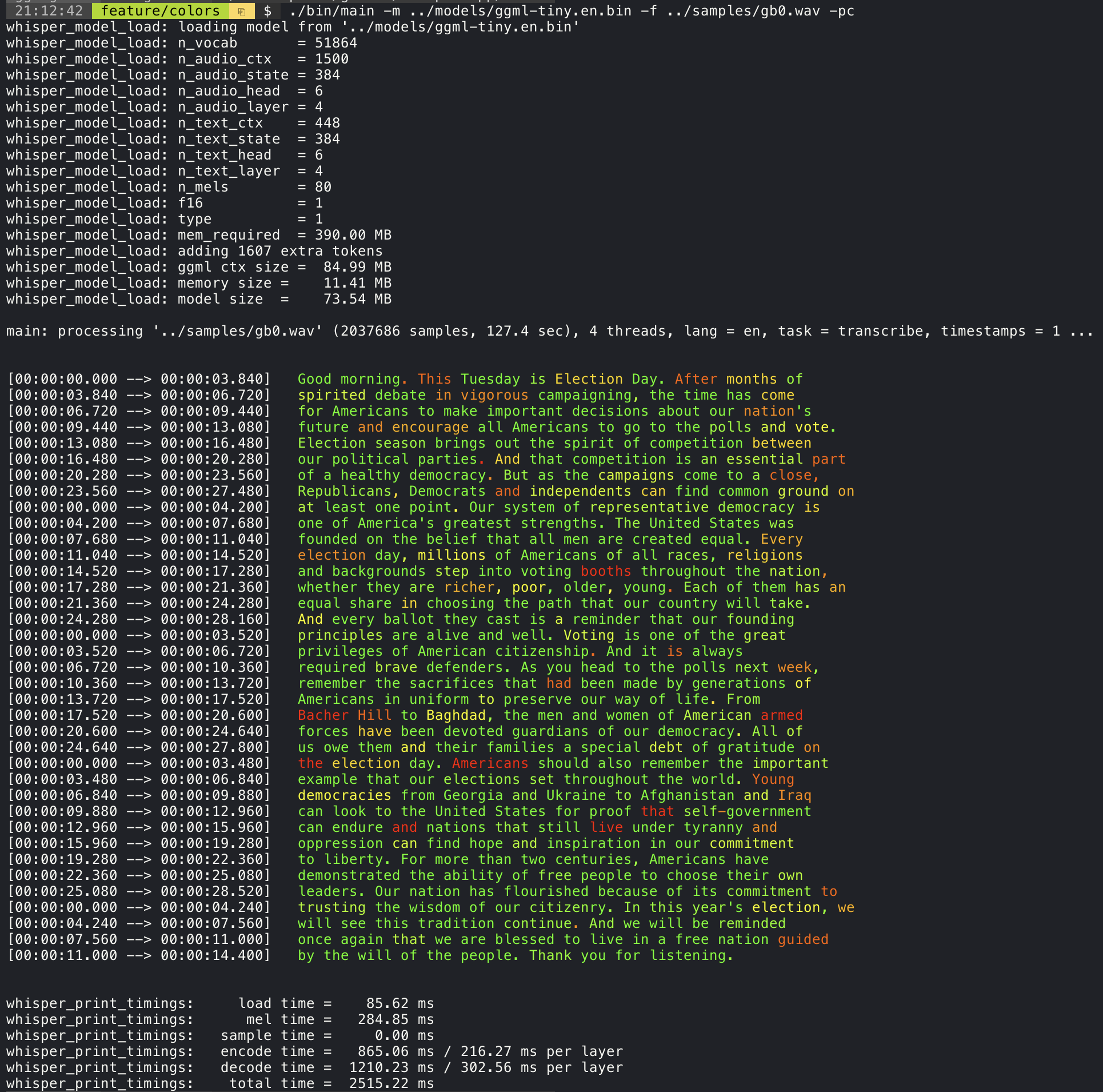
Par exemple, pour limiter la longueur de ligne à un maximum de 16 caractères, ajoutez simplement -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
L'argument --max-len peut être utilisé pour obtenir des horodatages au niveau des mots. Utilisez simplement -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
Plus d'informations sur cette approche sont disponibles ici: # 1058
Exemple d'utilisation:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . L'exemple principal fournit une prise en charge de la sortie des films de style karaoké, où le mot actuellement prononcé est mis en évidence. Utilisez l'argument -wts et exécutez le script bash généré. Cela nécessite d'installer ffmpeg .
Voici quelques exemples "typiques" :
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Utilisez le script scripts / bench-wts.sh pour générer une vidéo dans le format suivant:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4Afin d'avoir une comparaison objective des performances de l'inférence sur différentes configurations système, utilisez l'outil de banc. L'outil exécute simplement la partie de l'encodeur du modèle et imprime le temps qu'il a fallu pour l'exécuter. Les résultats sont résumés dans le problème de GitHub suivant:
Résultats de référence
De plus, un script pour exécuter Whisper.cpp avec différents modèles et fichiers audio est fourni Bench.py.
Vous pouvez l'exécuter avec la commande suivante, par défaut, il s'exécutera par rapport à n'importe quel modèle standard dans le dossier des modèles.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2Il est écrit en Python avec l'intention d'être facile à modifier et à étendre pour votre cas d'utilisation d'analyse comparative.
Il publie un fichier CSV avec les résultats du benchmarking.
ggmlLes modèles originaux sont convertis en format binaire personnalisé. Cela permet d'emballer tout ce qui est nécessaire dans un seul fichier:
Vous pouvez télécharger les modèles convertis à l'aide des modèles / téléchargement-gangml-model.sh script ou manuellement à partir d'ici:
Pour plus de détails, consultez les modèles de script de conversion / Convert-pt-to-ggml.py ou modèles / readme.md.
Il existe différents exemples d'utilisation de la bibliothèque pour différents projets dans le dossier Exemples. Certains exemples sont même portés pour s'exécuter dans le navigateur à l'aide de WebAssembly. Vérifiez-les!
| Exemple | Web | Description |
|---|---|---|
| principal | chuchoter | Outil pour traduire et transcrire l'audio à l'aide de Whisper |
| banc | banc. | Benchmark les performances de Whisper sur votre machine |
| flux | stream.wasm | Transcription en temps réel de la capture de microphone brut |
| commande | Command.WASM | Exemple de base de l'assistant vocal pour recevoir des commandes vocales du micro |
| wchess | wchess.wasm | Échecs contrôlés par la voix |
| parler | talk.wasm | Parler avec un bot GPT-2 |
| talk-llama | Parler avec un bot lama | |
| whisper.objc | Application mobile iOS utilisant whisper.cpp | |
| whisper.swiftui | Application swiftui iOS / macOS en utilisant whisper.cpp | |
| whisper.android | Application mobile Android utilisant Whisper.cpp | |
| chuchoter.nvim | Plugin Speech-to-Text pour Neovim | |
| générer-karaoke.sh | Script d'assistance pour générer facilement une vidéo karaoké de capture audio brute | |
| livestream.sh | Transcription audio en direct | |
| yt-wsp.sh | Télécharger + transcrire et / ou traduire une VOD (original) | |
| serveur | Serveur de transcription HTTP avec API de type OAI |
Si vous avez des commentaires sur ce projet, n'hésitez pas à utiliser la section des discussions et à ouvrir un nouveau sujet. Vous pouvez utiliser la catégorie Show and Tell pour partager vos propres projets qui utilisent whisper.cpp . Si vous avez une question, assurez-vous de vérifier la discussion des questions fréquemment posées (# 126).


