Étant donné que l'apparition d'un modèle grand langage (LLM) représenté par Chatgpt, en raison de sa capacité incroyable de l'intelligence artificielle universelle générale (AGI), elle a déclenché une vague de recherche et d'application dans le domaine du traitement du langage naturel. Surtout après la petite open source LLM à Small Scale qui peut être exécutée avec ChatGlM, LLAMA et d'autres joueurs civils peuvent fonctionner, il existe de nombreux cas d'applications de LLM, basées sur LLM, basées sur LLM. Ce projet vise à collecter et à trier les modèles open source, les applications, les ensembles de données et les tutoriels liés à la LLM chinois.
Si ce projet peut vous apporter un peu d'aide, laissez-moi un peu
Dans le même temps, vous êtes également invités à contribuer aux modèles open source impopulaires, aux applications, aux ensembles de données, etc. de ce projet. Fournir de nouvelles informations sur l'entrepôt, veuillez lancer des relations publiques et fournir des informations connexes telles que les liens entre les entrepôts, les nombres d'étoiles, les profils, les briefing et autres informations connexes en fonction du format de ce projet.
Présentation des détails du modèle de base commun:
Base
Inclure un modèle
Taille du paramètre du modèle
Numéro de jeton de trail
Formation maximale
De commercialiser
Chatglm
CHATGLM / 2/3/4 BASE ET CHAT
6B
1T / 1.4
2k / 32k
Usage commercial
Lama
Base lama / 2/3 et chat
7b / 8b / 13b / 33b / 70b
1T / 2T
2k / 4k
Partiellement commercialisé
Baichuan
Baichuan / 2 base et chat
7b / 13b
1.2T / 1.4T
4K
Usage commercial
Qwen
Qwen / 1.5 / 2/2,5 base et chat et VL
7b / 14b / 32b / 72b / 110b
2.2T / 3T / 18T
8k / 32k
Usage commercial
Floraison
Floraison
1B / 7B / 176B-MT
1.5T
2K
Usage commercial
Aquila
Aquila / 2 base / chat
7b / 34b
-
2K
Usage commercial
Internet
Internet
7b / 20b
-
200K
Usage commercial
Mixtrac
Base et chat
8x7b
-
32k
Usage commercial
Yi
Base et chat
6b / 9b / 34b
3T
200K
Usage commercial
En profondeur
Base et chat
1.3b / 7b / 33b / 67b
-
4K
Usage commercial
Xverse
Base et chat
7b / 13b / 65b / a4.2b
2.6T / 3.2T
8K / 16K / 256K
Usage commercial
Table des matières
Table des matières
1. Modèle
1.1 Modèle LLM texte
1.2 Modèle Multifamily LLM
2. Application
2.1 Filtrage dans le champ vertical
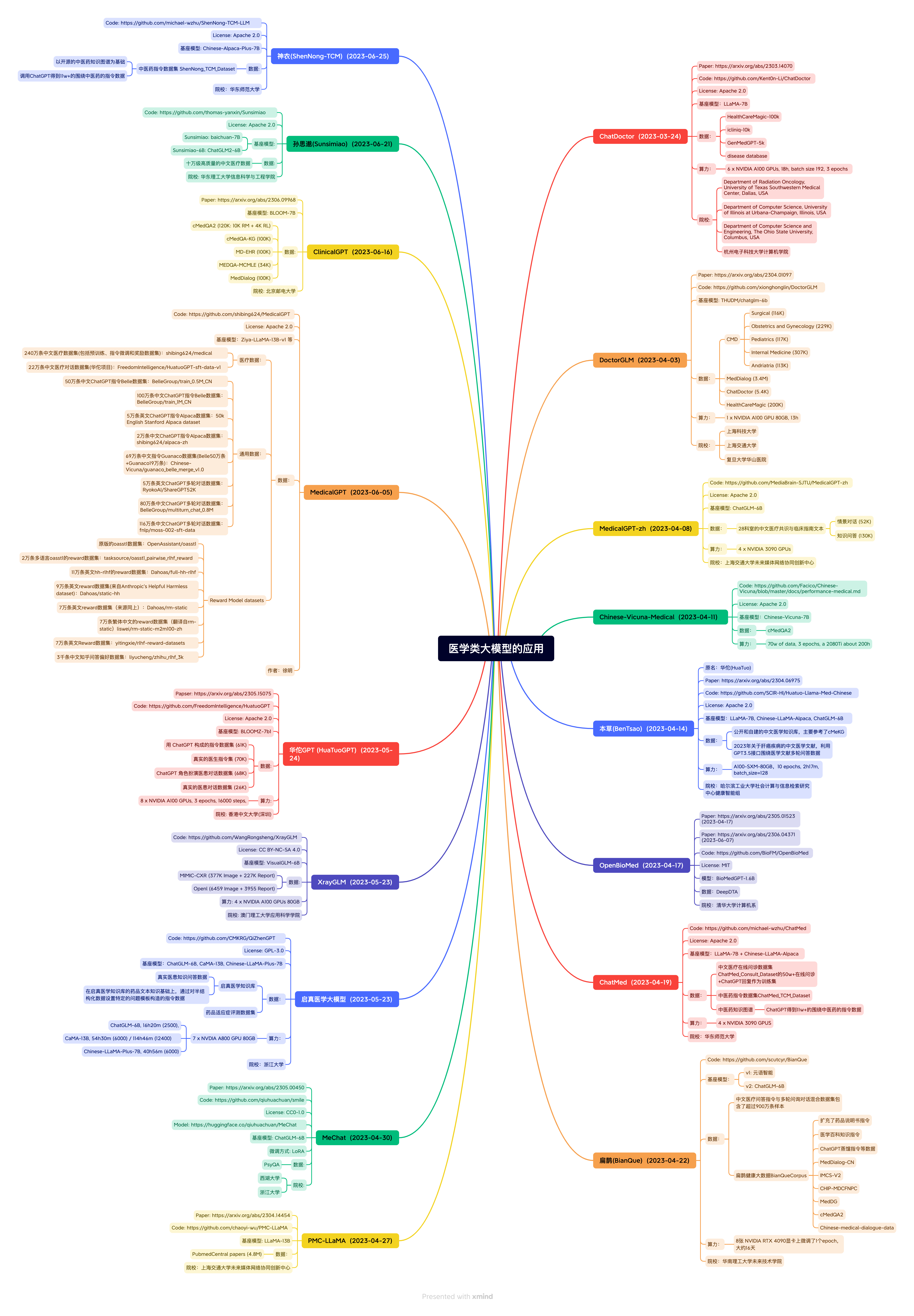
Soins médicaux
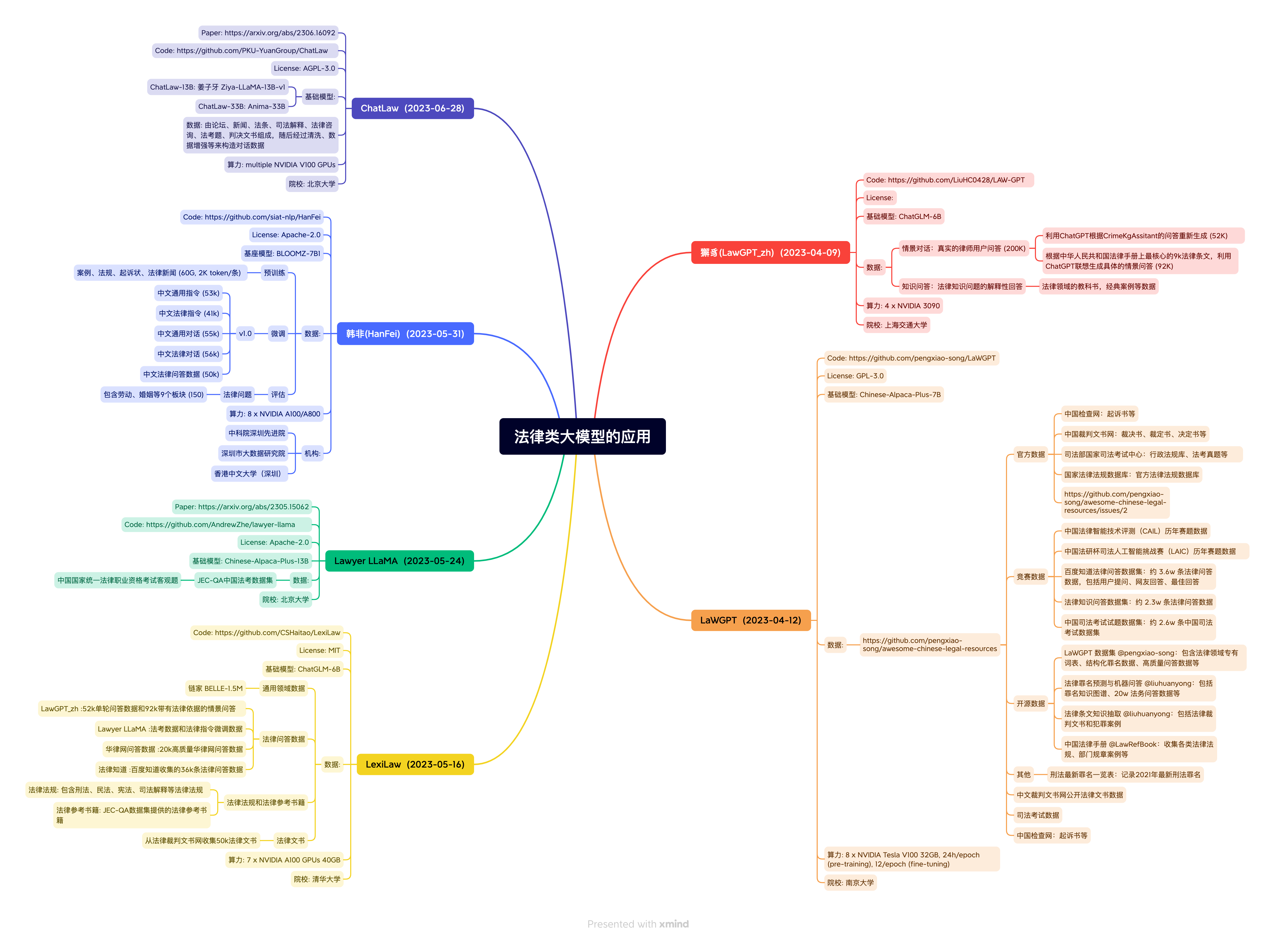
loi
finance
éduquer
science et technologie
E -Commerce
Sécurité du réseau
agriculture
2.2 Application Langchain
2.3 Autres applications
3. Ensemble de données
Ensemble de données de pré-formation
Ensemble de données SFT
Ensemble de données de préférence
4. Formation de formation LLM-TUNING
5. Cadre de déploiement du raisonnement LLM
6. Évaluation LLM
7. Tutoriel LLM
LLM Connaissances de base
Inviter un tutoriel d'ingénierie
Tutoriel d'application LLM
Tutoriel de combat réel LLM
8. Entrepôt connexe
Histoire des étoiles
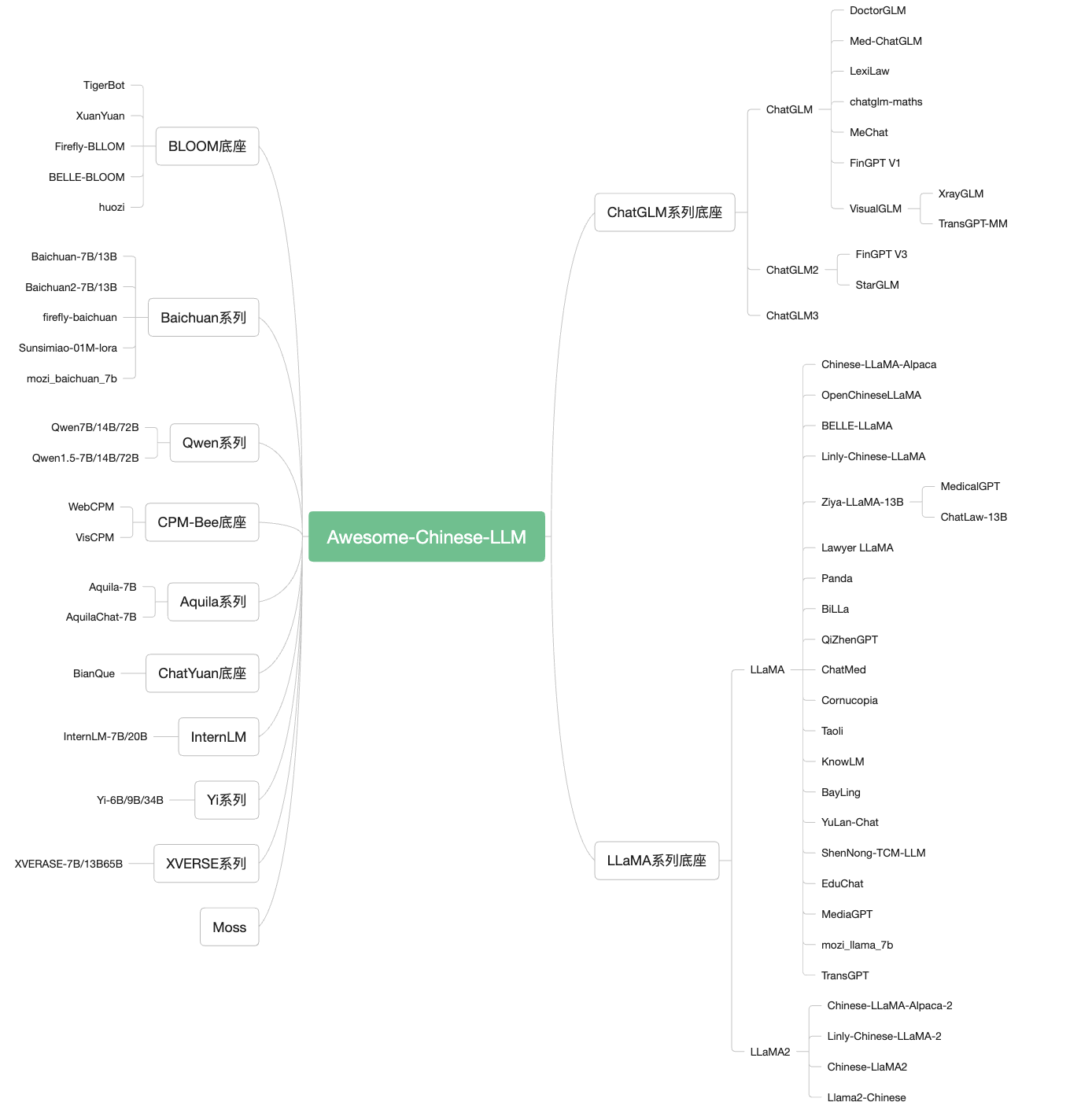
1. Modèle
1.1 Modèle LLM texte
Chatglm:
Adresse: https://github.com/thudm/chatglm-6b
Introduction: L'un des modèles de base open source les plus efficaces dans le domaine chinois, a optimisé le Q&A chinois et le dialogue. Après une formation bilingue d'environ 1T identifiant, complétée par des technologies telles que la supervision du tas fin, la rétroaction et les commentaires de la rétroaction humaine pour renforcer l'apprentissage
Chatglm2-6b
Adresse: https://github.com/thudm/chatglm2-6b
INTRODUCTION: Sur la base de la version de deuxième génération du modèle de dialogue chinois et anglais Open Source ChatGLM-6B, il a introduit la fonction cible hybride du GLM sur la base du dialogue du modèle préservé et des seuils de déploiement faibles, qui ont été conservés. -Tour des symboles d'identification britanniques dans le T et l'alignement des préférences humaines; Utilisation commerciale.
Chatglm3-6b
Adresse: https://github.com/thudm/chatglm3
INTRODUCTION: CHATGLM3-6B est le modèle open source de la série ChatGLM3. : CHATGLM3- Le modèle de base du 6B, ChatGlm3-6B, utilise plus de données de formation, des étapes de formation plus complètes et des stratégies de formation plus raisonnables; un support fonctionnel plus complet: ChatGLM3-6B utilise un format rapide nouvellement conçu, à l'exception de plusieurs cycles de dialogue normaux.同时原生支持工具调用 (Call de fonction) 、代码执行 (Interpréteur de code) 和 Agent 任务等复杂场景;更全面的开源序列 : 除了对话模型 chatGlm3-6b 外 , 还开源了基础模型 CHATGLM3-6B-base 、长文本Modèle de dialogue CHATGLM3-6B-32K. Le poids ci-dessus est complètement ouvert à la recherche universitaire, et une utilisation commerciale gratuite est également autorisée après avoir rempli le questionnaire.
GLM-4
Adresse: https://github.com/thudm/glm-4
Brève introduction: GLM-4-9B est la version open source du modèle de pré-formation de dernière génération lancé par le Smart Spectrum AI. Dans l'évaluation des ensembles de données tels que la sémantique, les mathématiques, le raisonnement, le code et les connaissances, le GLM-4-9B et sa version de préférence humaine de GLM-4-9B-CHAT montrent toutes d'excellentes performances au-delà de LLAMA-3-8B Essence En plus de plusieurs cycles de dialogue, GLM-4-9B-CHAT a également des fonctions avancées telles que la navigation Web, l'exécution de code, les appels d'outils personnalisés (appel de fonction) et le raisonnement de texte long (support pour le contexte maximal 128K). Cette génération a ajouté un support multi-langue, soutenant 26 langues, notamment le japonais, le coréen et l'allemand. Nous avons également lancé des modèles GLM-4-9B-CHAT-1M qui prennent en charge la longueur contextuelle 1M (environ 2 millions de caractères chinois) et le modèle multimode GLM-4V-9B basé sur GLM-4-9B. GLM-4V-9B a une capacité de dialogue multilingue multilingue multilingue en vertu de la haute résolution de 1120 * 1120. Dans de nombreux aspects de l'évaluation multimodale tels que la capacité complète complète chinoise et l'anglais, le raisonnement de perception, la reconnaissance de texte, la compréhension des graphiques, GLM-4V -9b exprime les excellentes performances du dépassement GPT-4-Turbo-2024-04-09, Gemini 1.0 Pro, Qwen-VL-Max et Claude 3 Opus.
Qwen / qwen1.5 / qwen2 / qwen2.5
Adresse: https://github.com/qwenlm
Introduction: Tongyi Qianwen est une série de modèles de modèle de Tongyi Qianwen développé par Alibaba Cloud, y compris l'échelle de paramètre de 1,8 milliard (1,8b), 7 milliards (7b), 14 milliards (14b), 72 milliards (72b), 1100 et 1100 100 millions (110b). Les modèles de chaque échelle incluent le modèle de base QWEN et le modèle de dialogue. Les ensembles de données incluent une variété de types de données tels que le texte et le code. Appelez efficacement la prise et la mise à niveau vers l'agent Essence
Introduction: Shangtang Technology, Shanghai AI Laboratory et l'Université chinoise de Hong Kong, Fudan University et Shanghai Jiaotong University ont publié la "bourse" de 100 milliards de paramètres de paramètre de niveau de niveau. Il est rapporté que "Scholar PU" possède 104 milliards de paramètres et est formé sur "un ensemble de données à haute qualité multidangue contenant 1,6 billion de jetons".
Internet
Adresse: https://github.com/internlm/internlm
Introduction: Shangtang Technology, Shanghai AI Laboratory et l'Université chinoise de Hong Kong, Fudan University et Shanghai Jiaotong University ont publié le modèle de grande langue de 100 milliards de paramètres de niveau "Internlm2". Internlm2 a fait de grands progrès dans le numérique, le code, le dialogue et la création, et les performances complètes ont atteint le niveau principal du modèle open source. Internlm2 contient deux modèles: 7b et 20b. 7b fournit un modèle léger mais unique pour la recherche et l'application de poids léger.
Introduction: un modèle de langue pré-formation à grande échelle développé par le développement intelligent de Baichuan. Sur la base de la structure du transformateur, le modèle de paramètres de 7 milliards formé sur environ 1,2 billion de jetons prend en charge le bilingue chinois et anglais, et la longueur de la fenêtre de contexte est 4096. La référence standard de l'autorité chinoise et de l'autorité anglaise (C-Eval / MMLU) a le meilleur effet de la même taille.
Introduction: Baichuan-13b est un modèle de langue à grande échelle contenant 13 milliards de paramètres après Baichuan-7b après Baichuan-7b. Le projet publie deux versions: Baichuan-13B-Base et Baichuan-13b-chat.
INTRODUCTION: La nouvelle génération du modèle de grande langue open source lancé par Baichuan Intelligence utilise 2,6 billions de jetons pour s'entraîner avec un corpus de haute qualité. .
Xverse-7b
Adresse: https://github.com/xverse- Ai / xverse-7b
INTRODUCTION: Le modèle de grande langue soutenu par la technologie Shenzhen Yuanxiang prend en charge les modèles multi-langues, prend en charge la longueur de contexte 8K et utilise une qualité de qualité élevée et diversifiée de 2,6 billions de jetons pour former le modèle. Russie et Western. Il comprend également des modèles de versions quantitatives GGUF et GPTQ, qui prend en charge le raisonnement sur LLAMA.CPP et VLLM sur le système MacOS / Linux / Windows.
Xverse-13b
Adresse: https://github.com/xverse- Ai / xverse-13b
INTRODUCTION: Modèles de grande langue soutenus par la technologie Shenzhen Yuanxiang prenant en charge les modèles multi-langues, soutenant la longueur de contexte de 8K (longueur de contexte) et en utilisant des données de haute qualité et diversifiées de 3,2 billions de jetons pour former pleinement le modèle. comme la Grande-Bretagne, la Russie et l'Ouest. Y compris le modèle de dialogue de séquence longs xverse-13b-256k. Il comprend également des modèles de versions quantitatives GGUF et GPTQ, qui prend en charge le raisonnement sur LLAMA.CPP et VLLM sur le système MacOS / Linux / Windows.
Xverse-65b
Adresse: https://github.com/xverse- Ai / xverse-65b
INTRODUCTION: Un modèle grand langage soutenu par Shenzhen Yuanxiang Technology prend en charge le modèle multi-language, soutient la durée du contexte de 16k et utilise une qualité de qualité élevée et diversifiée de plus de 2,6 billions de jetons pour former le modèle pour former complètement le modèle. des langues comme la Grande-Bretagne, la Russie et l'Ouest. Y compris un modèle xverse-65b-2 incrémental pré-entraînement avec une pré-formation incrémentielle. Il comprend également des modèles de versions quantitatives GGUF et GPTQ, qui prend en charge le raisonnement sur LLAMA.CPP et VLLM sur le système MacOS / Linux / Windows.
Xverse-mie-a4.2b
Adresse: https://github.com/xverse- Ai / Xverse-Moe-A4.2b
INTRODUCTION: Modèle de grande langue, qui prend en charge le multi-langus développé indépendamment par la technologie Shenzhen Yuanxiang. Soutenir plus de 40 langues telles que la Chine, la Grande-Bretagne, la Russie et l'Ouest.
Ciel
Adresse: https://github.com/skyworkai/skywork
Introduction: Le projet est ouvert aux modèles de la série Tiangong. Modèle Skywork-13B spécifique, modèle Skywork-13B-CHAT, modèle Skywork-13B-Math, modèle Skywork-13B-MM et modèles de versions quantitatives de chaque modèle pour prendre en charge les utilisateurs à déployer et raisonnez au déploiement de la carte graphique de consommation et Raisier l'essence
Yi
Adresse: https://github.com/01- Ai / Yi
Brève introduction: ce projet est ouvert à des modèles tels que YI-6B et YI-34B. Documents avec plus de 1000 pages.
INTRODUCTION: Le projet est basé sur le LLAMA-2 Commercial pour le deuxième développement. -Tune plusieurs tours pour s'adapter à divers scénarios d'application et aux interactions de dialogue multi-rondes. Dans le même temps, nous considérons également une solution d'adaptation chinoise plus rapide: Chinese-Llama2-Sft-V0: Utilisez les instructions chinoises open source existantes ou les données de dialogue pour affiner directement Llama-2 (sera récemment open source).
INTRODUCTION: Sur la base de LLAMA-7B, une grande base de modèle de langue générée par la formation préalable à la formation incrémentale de données chinoises, par rapport au lama d'origine, ce modèle s'est considérablement amélioré en termes de compréhension chinoise et de capacité de génération. .
Belle:
Adresse: https://github.com/lianjiaatech/belle
Introduction: open source pour une série de modèles basés sur l'optimisation Bloomz et LLAMA. Algorithmes de formation sur les performances du modèle.
Introduction: Open Source est basé sur LLAMA -7B, -13B, -33B, -65B pour les modèles de langue pré-formation continus dans le domaine chinois, et utilise près de 15 m de données pour la pré-formation secondaire.
Robin (Robin):
Adresse: https://github.com/optimalscale/lmflow
Brève introduction: Robin (Robin) est un modèle bilingue chinois-anglais développé par l'équipe LMFlow de l'Université des sciences et de la technologie de Chine. Seul le modèle de génération Robin Second-Génération obtenu par seulement 180 000 données de données était bien réglé, atteignant la première place sur la liste des étreintes. LMFlow aide les utilisateurs à former rapidement des modèles personnalisés.
INTRODUCTION: Fengshenbang-LM (Big Model of God) est un grand système open source dominé par le Idea Research Institute Cognitive Computing and Natural Language Research Models. , Copywriting, Common Sense Quiz et Mathematical Computing. En plus des modèles de la série Jiangziya, le projet est également ouvert aux modèles tels que Taiyi et Erlang God Series.
Billa:
Adresse: https://github.com/Neutralzz/billa
Brève introduction: Le projet est open source du modèle de Llama bilingue anglaise avec des capacités de raisonnement améliorées. Les principales caractéristiques du modèle sont les suivantes: améliorer considérablement la capacité de compréhension chinoise du lama et minimiser autant que possible la capacité anglaise du LLAMA d'origine; La tâche de compréhension du modèle pour résoudre la logique de la tâche; mise à jour de paramètres de quantité complète, poursuivre des résultats de génération de meilleurs.
MOUSSE:
Adresse: https://github.com/openlmlab/moss
INTRODUCTION: Soutenez le modèle de langue de dialogue open source des plugins bilingues chinois et anglais. Formation en préférence, il a les instructions de dialogue, l'apprentissage en fiche et la formation des préférences humaines.
Introduction: Il comprend une série de projets open source de grands modèles de langue chinoise, qui contient une série de modèles de langue basés sur les modèles open source existants (Moss, Llama), des instructions pour les ensembles de données fins.
Linly:
Adresse: https://github.com/cvi-szu/linly
Introduction: Fournir un modèle de dialogue chinois Linly-Chatflow, le modèle de base chinois Linly-Chinese-Llama et ses données de formation. Le modèle de base chinois est basé sur le lama, utilisant une formation incrémentielle parallèle chinoise et chinoise et britannique. Le projet résume les données d'instructions multi-langues actuelles, effectue des instructions à grande échelle pour suivre le modèle chinois pour suivre la formation et réaliser le modèle de dialogue Linly-Chatflow.
Luciole:
Adresse: https://github.com/yangjianxin1/firefly
Introduction: Firefly est un grand projet de modèle chinois open source. comme Baichuan Baichuan, Ziya, Bloom, Llama, etc. Tenir le modèle LORA et la base pour fusionner le poids, ce qui est plus pratique pour la raison.
Chatyuan
Adresse: https://github.com/clue- Ai / Chatyuan
Introduction: Une série de modèles de langage de dialogue fonctionnel soutenus par Yuanyu Intelligent, qui prend en charge le dialogue bilingue sino-britannique, optimisé dans des données financières, un apprentissage amélioré humain, une chaîne de pensée, etc.
Chatrwkv:
Adresse: https://github.com/blinkdl/chatrwkv
Introduction: Open source Une série de modèles de chat (y compris l'anglais et le chinois) basé sur l'architecture RWKV, des modèles publiés, notamment Raven, Novel-Chneng, Novel-ch et Novel-Chneng-Chnpro, peuvent discuter directement et jouer de la poésie, des romans et d'autres Créations.
Cpm-bee
Adresse: https://github.com/openbmbmbmb/cpm-bee
Brève introduction: une utilisation commerciale complète de l'open source, autorisée de 10 milliards de paramètres de modèles de base chinois et anglais. Il adopte l'architecture d'auto-régression de Transformer pour effectuer une pré-formation sur le corpus de haute qualité en milliards de billions et a de fortes capacités de base. Les développeurs et les chercheurs peuvent s'adapter à divers scénarios sur la base du modèle de base CPM-BEE pour créer des modèles d'applications dans des domaines spécifiques.
Introduction: un modèle de langue à grande échelle (LLM) avec un multi-langues et multi-tâches (LLM), Open Source comprend des modèles: Tigerbot-7b, Tigerbot-7B-base, Tigerbot-180b, formation de base et code de raisonnement, 100G Pré-formation de données, couvrant la finance et la loi dans le domaine de l'Encyclopédie et de l'API.
Introduction: Publié par le Zhiyuan Research Institute, le modèle de langue Aquila a hérité des avantages de la conception architecturale de GPT-3, LLAMA, etc., a remplacé un groupe d'opérateurs sous-jacents plus efficaces pour réaliser, redessinait le jeton bilingue chinois et anglais, a mis à niveau le bmtrain parallèle parallèle chinois et anglais La méthode de formation a commencé à partir de 0 sur la base du corpus chinois et anglais de haute qualité. Il s'agit également du premier modèle de langue open source à grande échelle qui prend en charge les connaissances bilingues sino-britanniques, soutient le contrat de licence commerciale et répond aux besoins de la conformité aux données nationales.
Aquila2
Adresse: https://github.com/flagai-open/aquila2
Introduction: Publié par Zhiyuan Research Institute, Aquila2 Series, y compris le modèle de base du langage Aquila2-7b, Aquila2-34b et Aquila2-70b-Expr, Dialogue Model Aquilachat2-7b, Aquilachat2-34b et Aquilachat2-70b-Expr, Texte long dialogue Aquilachat2 Aquilachat2 -7B-16K et Aquilachat2-34b-16.
Anima
Adresse: https://github.com/lyogavin/anima
INTRODUCTION: Un modèle de langue chinoise 33B basé sur QLORA développé par la technologie AI Ten. Basé sur l'évaluation du tournoi ELO est meilleure.
Knowlm
Adresse: https://github.com/zjunlp/kwowlm
Introduction: Le projet Knowlm vise à publier le cadre des grands modèles open source et des poids des modèles correspondants pour aider à réduire le problème de l'erreur des connaissances, y compris la difficulté de la connaissance des grands modèles et des erreurs et préjugés potentiels. La première phase du projet a publié l'extraction basée sur les lama de l'analyse de l'intelligence de Big Model, en utilisant le corpus chinois et anglais pour former entièrement entièrement LLAMA (13B), et optimise les tâches d'extraction de connaissances basées sur la technologie d'instruction de conversion de graphiques de connaissances.
Bayling
Adresse: https://github.com/ictnlp/bayling
INTRODUCTION: Un modèle universel à grande échelle avec un alignement croisé de la langue croisée a été développé par l'équipe de traitement du langage naturel de l'Institut de technologie informatique de l'Académie chinoise des sciences. Bayling utilise Llama comme modèle de base, explorant la méthode des instructions financières avec des tâches de traduction interactives comme le noyau. . Dans l'évaluation de la traduction multi-langue, de la traduction interactive, des tâches universelles et des examens standardisés, Bai Ling a montré de meilleures performances en chinois / anglais. Bai Ling fournit une version en ligne de Demo à tout le monde.
Yulan-chaat
Adresse: https://github.com/ruc-gsai/yulan- chat
INTRODUCTION: Yulan-Chat est un modèle en grande langue développé par les chercheurs de la Renmin University of China GSAI. Il est développé bien torré sur la base de LLAMA et a des instructions en anglais et en chinois de haute qualité. Yulan-Chat peut discuter avec les utilisateurs, suivre bien les instructions anglais ou chinois et peut être déployée sur le GPU (A800-80G ou RTX3090) après quantification.
Polylme
Adresse: https://github.com/damo-nlp-mt/polylm
Brève introduction: un modèle multi-langue formé à partir du début de 640 milliards de mots, y compris la taille de deux modèles (1,7b et 13b). Polylm couvre la Chine, la Grande-Bretagne, la Russie, l'Ouest, la France, les Portugais, l'Allemagne, l'Italie, lui, Bo, Bobo, Ashi, Hébreux, Japon, Corée du Sud, Thaïlande, Vietnam, Indonésie et d'autres types, en particulier plus amicaux avec la langue asiatique.
huozi
Adresse: https://github.com/hit-scir/huozi
INTRODUCTION: Un modèle de langue pré-formation à grande échelle d'un modèle de langue pré-formation à grande échelle qui est développé par le Harbin Institute of Nature Language Treatment Research Institute. Ce modèle est basé sur le modèle de paramètres de 7 milliards de la structure de la floraison, qui prend en charge le bilingue chinois et anglais. ensemble de données.
Yayi
Adresse: https://github.com/weenge-research/yayi
INTRODUCTION: Le modèle élégant est fini dans les données sur le terrain de haute qualité du domaine de haute qualité de millions de structures artificielles. et la gouvernance urbaine. À partir de l'itération de l'initialisation pré-formation de la pré-formation, nous avons progressivement amélioré sa capacité chinoise de base et ses capacités d'analyse sur le terrain, et augmenté plusieurs cycles de dialogue et certaines capacités de plug -in. Dans le même temps, après des centaines de tests internes des utilisateurs, l'optimisation continue de rétroaction artificielle a été continuellement améliorée, ce qui améliore encore les performances et la sécurité du modèle. Open source de modèle d'optimisation chinoise basé sur LLAMA 2, explore les dernières pratiques adaptées aux missions chinoises dans de nombreux domaines chinois.
Yayi2
Adresse: https://github.com/weenge-research/yayi2
INTRODUCTION: Yayi 2 est une nouvelle génération de modèles de grande langue open source développés par Zhongke Wenge, y compris les versions de base et de chat avec une échelle de paramètre de 30b. Yayi2-30b est un modèle de langue large basé sur le transformateur, en utilisant un corpus de haute qualité et multicangue de plus de 2 billions de jetons pour la pré-formation. En réponse aux scénarios d'application dans les domaines généraux et spécifiques, nous avons utilisé des millions d'instructions pour une taune fine, et en même temps, nous utilisons la rétroaction humaine pour renforcer les méthodes d'apprentissage pour mieux aligner le modèle et les valeurs humaines. Ce modèle open source est le modèle de base Yayi2-30b.
Yuan-2.0
Adresse: https://github.com/ieit-yuan/yuan-2.0
INTRODUCTION: Le projet est ouvert à une nouvelle génération de modèle de langue de base publié par Inspur Information. Et fournir des scripts pertinents pour les services de pré-formation, de fin de réduction et de raisonnement. La source 2.0 est basée sur la source 1.0, en utilisant des données de pré-formation plus élevées et des ensembles de données fins pour faire en sorte que le modèle ait une compréhension plus approfondie de la sémantique, des mathématiques, du raisonnement, du code et des connaissances.
INTRODUCTION: Le projet effectue des tables d'expansion chinoises pré-formation basées sur le modèle d'experts hybrides clairsemé Mixtral-8x7b. L'efficacité du codage chinois de ce modèle est considérablement améliorée que le modèle d'origine. Dans le même temps, grâce à la pré-formation incrémentielle sur le corpus open source à grande échelle, ce modèle a une forte génération chinoise et une capacité de compréhension.
Se balancer
Adresse: https: //github.com/vivo-jlab/blualm
INTRODUCTION: BLUELM est un modèle de langue préalable à la grande échelle développé indépendamment par le Vivo AI Global Research Institute. (CHAT) Modèle.
INTRODUCTION: Orionstar-yi-34b-chat est le modèle YI-34B basé sur le ciel Starry basé sur l'open source de 10 000 choses. Expériences interactives pour les grands utilisateurs de la communauté des modèles.
Minimicpm
Ajouter
INTRODUCTION: MINICPM est une série de modèles latéraux couramment ouverts par les nouilles Wall Intelligence et Tsinghua University Natural Language Laboratory. des paramètres.
Mengzi3
Adresse: https://github.com/langboat/Mengzi3
Introduction: le modèle Mengzi3 8b / 13b est basé sur l'architecture lame, avec la sélection de corpus à partir de pages Web, d'encyclopédie, de sociaux, de médias, d'actualités et d'ensembles de données open source de haute qualité. En continuant une formation de corpus multi-langues sur des milliards de jetons, la capacité chinoise du modèle est exceptionnelle et prend en compte la capacité multi-langue.
1.2 Modèle Multifamily LLM
VisualGlm-6b
Adresse: https://github.com/thudm/visualglm-6b
INTRODUCTION: Un modèle de dialogue open source et multimode soutenant les images, chinois et anglais. S'appuyant sur la paire graphique chinoise de 30 m de haute qualité à partir de l'ensemble de données COGVIEW, pré-formation avec le graphique anglais critiqué avec 300 m.
Cogvlm
Adresse: https://github.com/thudm/cogvlm
Brève introduction: un puissant modèle de langage visuel open source (VLM). COGVLM-17B a 10 milliards de paramètres visuels et 7 milliards de paramètres de langue. Le COGVLM-17B a atteint des performances SOTA dans 10 tests de référence intermodulaires classiques. Le COGVLM peut décrire avec précision les images et presque aucune hallucination n'apparaît.
INTRODUCTION: modèles chinois multi-modes développés sur la base du projet de modèle de lama et d'alpaca chinois. VisualCla ajoute des modules d'encodage d'image au modèle chinois LLAMA / ALPACA, afin que le modèle de lama puisse recevoir des informations visuelles. Sur cette base, le graphique chinois a été utilisé pour la pré-formation multimodale sur les données. Les instructions de mode sont actuellement open source VisualCla-7B-V0.1.
Llasme
Adresse: https://github.com/linksoul- Ai / llasm
Brève introduction: le premier modèle de dialogue open source et commercial qui soutient le dialogue multimodal à double voix chinois et anglais. L'entrée vocale pratique améliorera considérablement l'expérience du grand modèle avec le texte comme entrée, tout en évitant les processus fastidieux en fonction des solutions ASR et des erreurs possibles qui peuvent être introduites. Actuellement, Llasm-Chinese-Llama-2-7b, llasm-baichuan-7b et autres modèles et ensembles de données et ensembles de données.
Viscpm
Ajouter
INTRODUCTION: Une série Open Source Multi-Mode et Grand Modèles, prend en charge le dialogue multimode bilingue chinois et anglais (modèles VISCPM-CHAT) et les capacités de génération de texte (Modèle ViscPM-Paint). VISCPM est basé sur des dizaines de milliards de paramètres, une formation CPM-BEE (10b) de modèle à grande échelle et intègre le codeur visuel (Q-Former) et le décodeur visuel (diffusion-unne) pour prendre en charge l'entrée et la sortie de le signal visuel.得益于CPM-Bee基座优秀的双语能力,VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
Introduction: The project is open to the field of Chinese long text instructions with a multi-scale psychological counseling field with a multi-round dialogue data combined instruction to fine-tune the psychological health model (Soulchat). Fully tune the full number of parameters .
Introduction: WingPT is a large model based on the GPT-based medical vertical field. Based on the Qwen-7B1 as the basic pre-training model, it has continued pre-training in this technology, instructions fine-tuning. -7B-Chat modèle.
简介:LazyLLM是一款低代码构建多Agent大模型应用的开发工具,协助开发者用极低的成本构建复杂的AI应用,并可以持续的迭代优化效果。 Lazyllm provides a more flexible application function customization method, and realizes a set of lightweight network management mechanisms to support one -click multi -Agent application, support streaming output, compatible with multiple IaaS platforms, and support the model in the application model Continue fine - réglage.
MemFree
地址:https://github.com/memfreeme/memfree
简介:MemFree 是一个开源的Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
Data set description: The scholar · Wanjuan 1.0 is the first open source version of the scholar · Wanjuan multi -modal language library, including three parts: text data set, graphic data set, and video data set. The total amount of data exceeds 2TB . 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
Data set description: Unified rich IFT data (such as COT data, still expands continuously), multiple training efficiency methods (such as Lora, P-Tuning), and multiple LLMS, three interfaces on three levels to create convenient researchers LLM-IFT research plate-forme.
Data set description: Data sets are renovated with the true psychological mutual assistance QA for multiple rounds of psychological health support through ChatGPT. Dialogue themes, vocabulary and chapters are more rich and diverse, and are more in line with the application scenarios of multi -round dialogue.
偏好数据集
CValues
地址:https://github.com/X-PLUG/CValues
数据集说明:该项目开源了数据规模为145k的价值对齐数据集,该数据集对于每个prompt包括了拒绝&正向建议(safe and reponsibility) > 拒绝为主(safe) > 风险回复(unsafe)三种类型,可用于增强SFT模型的安全性或用于训练reward模型。
简介:一个中文版的大模型入门教程,围绕吴恩达老师的大模型系列课程展开,主要包括:吴恩达《ChatGPT Prompt Engineering for Developers》课程中文版,吴恩达《Building Systems with the ChatGPT API》课程中文版,吴恩达《LangChain for LLM Application Development》课程中文版等。
Introduction: ChatGPT burst into fire, which has opened a key step leading to AGI. This project aims to summarize the open source calories of those ChatGPTs, including large text models, multi -mode and large models, etc., providing some convenience for everyone .
Introduction: This Repo aims at recording Open Source Chatgpt, and Providing An Overview of How to get involved, Including: Base Models, TechNologies, DOMAIN MODELS , Training Pipelines, Speed Up Techniques, Multi-Language, Multi-Modal, and more Aller.
简介:This repo record a list of totally open alternatives to ChatGPT.
Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM
简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs.