GroundingDINO
Grounding DINO SwinB

IDEA-CVR, IDEA-RESSEARCH
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang ? .
[ Paper ] [ Demo ] [ BibTex ]
Implémentation de Pytorch et modèles pré-entraînés pour la mise à la terre Dino. For details, see the paper Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection .
2023/07/18 : Nous libérons Semantis-SAM, un modèle de segmentation d'image universel pour activer le segment et reconnaître quoi que ce soit à toute granularité souhaitée. Code and checkpoint are available!2023/06/17 : We provide an example to evaluate Grounding DINO on COCO zero-shot performance.2023/04/15 : Refer to CV in the Wild Readings for those who are interested in open-set recognition!2023/04/08 : We release demos to combine Grounding DINO with GLIGEN for more controllable image editings.2023/04/08 : We release demos to combine Grounding DINO with Stable Diffusion for image editings.2023/04/06 : We build a new demo by marrying GroundingDINO with Segment-Anything named Grounded-Segment-Anything aims to support segmentation in GroundingDINO.2023/03/28 : A YouTube video about Grounding DINO and basic object detection prompt engineering. [Skalskip]2023/03/28 : Add a demo on Hugging Face Space!2023/03/27 : Support CPU-only mode. Maintenant, le modèle peut fonctionner sur des machines sans GPU.2023/03/25 : Une démo pour la mise à la terre Dino est disponible chez Colab. [Skalskip]2023/03/22 : Code is available Now! Épouser la mise à la terre dino et gligen
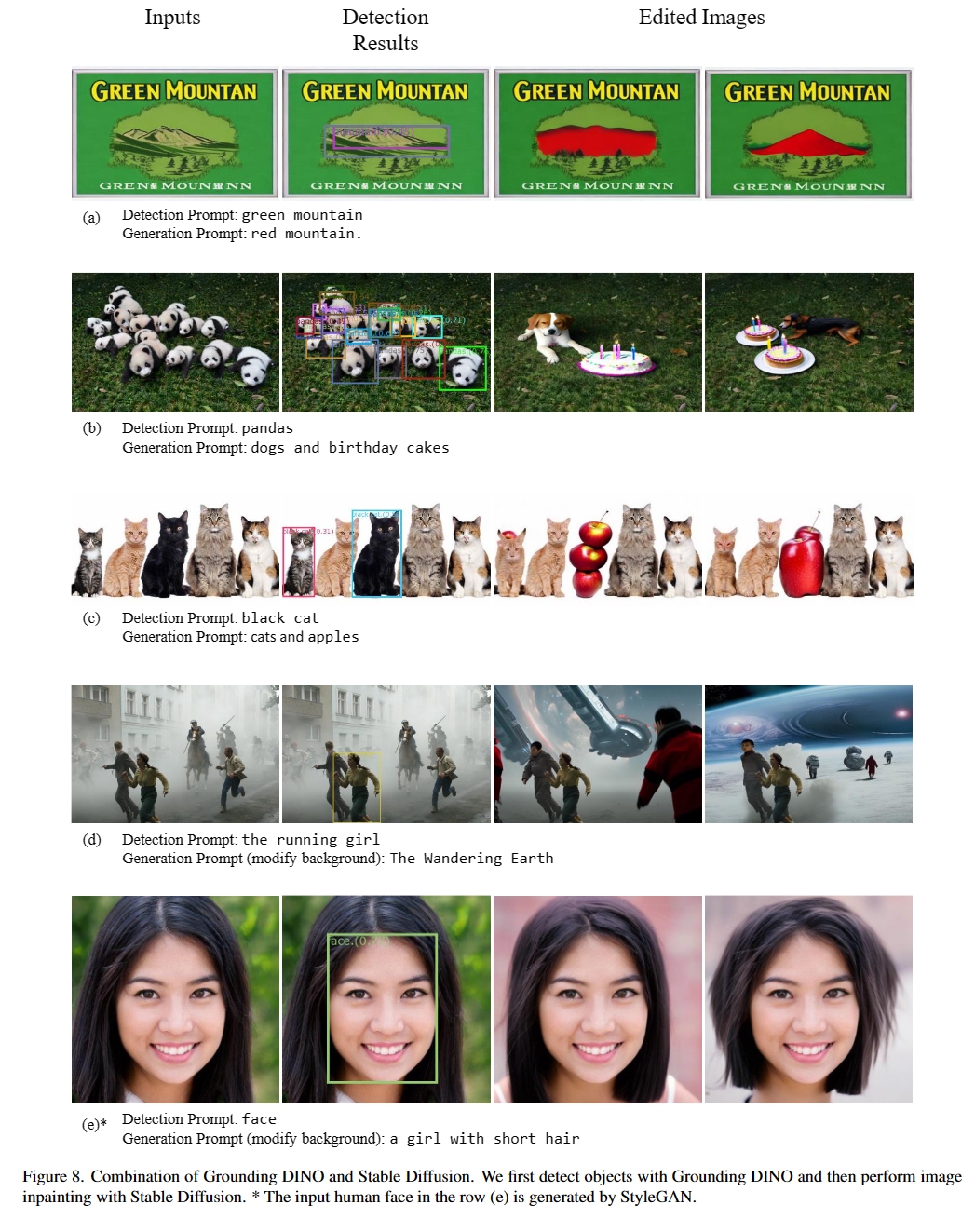
Épouser la mise à la terre dino et gligen (image, text) pair as inputs.900 (by default) object boxes. Chaque boîte a des scores de similitude sur tous les mots d'entrée. (comme le montrent les figures ci-dessous.)box_threshold .text_threshold as predicted labels.dogs in the sentence two dogs with a stick. , vous pouvez sélectionner les cases avec des similitudes de texte les plus élevées avec dogs comme sorties finales.. Pour la mise à la terre Dino. 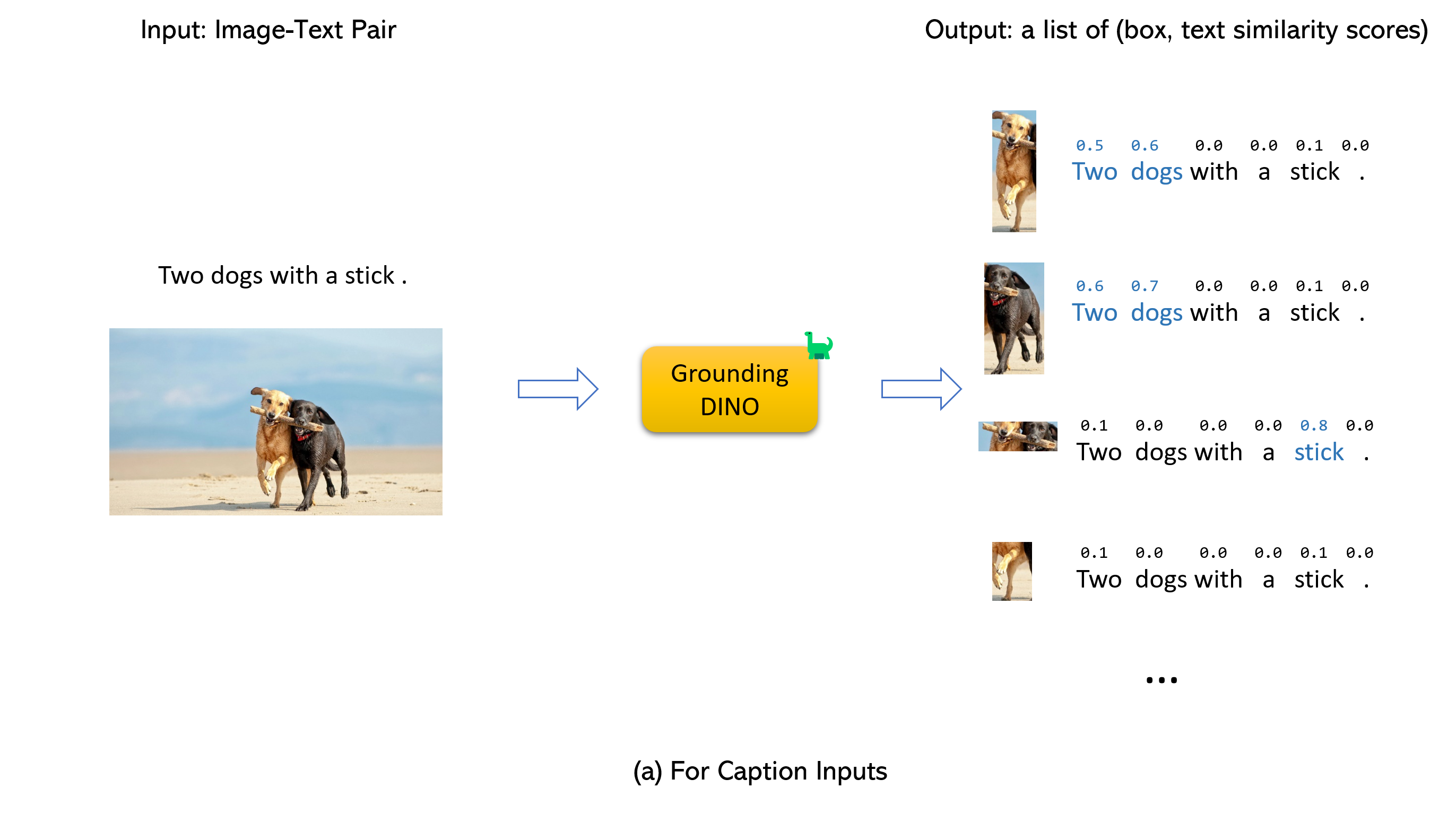
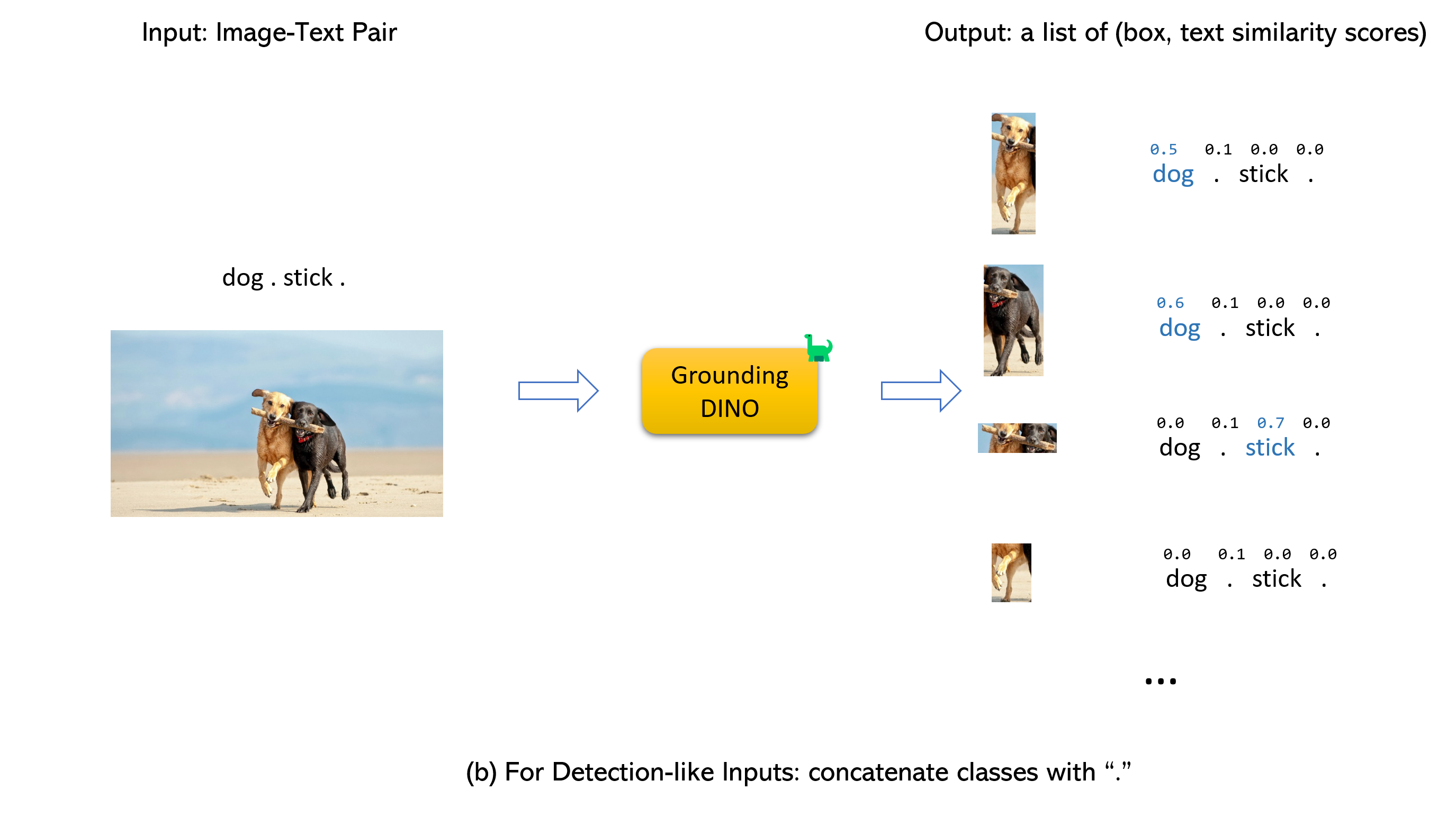
Note:
CUDA_HOME est définie. Il sera compilé en mode CPU uniquement si aucun CUDA disponible.Veuillez vous assurer que la suite des étapes d'installation strictement, sinon le programme peut produire:
NameError: name ' _C ' is not definedSi cela se produisait, veuillez réinstaller le Groundingdino en rendant le git et refaire toutes les étapes d'installation.
echo $CUDA_HOMES'il n'imprime rien, cela signifie que vous n'avez pas configuré le chemin /
Exécutez-le pour que la variable d'environnement soit définie sous le shell actuel.
export CUDA_HOME=/path/to/cuda-11.3Remarquez que la version de CUDA doit être alignée sur votre runtime CUDA, car il pourrait exister plusieurs Cuda en même temps.
Si vous souhaitez définir le CUDA_HOME en permanence, stockez-le en utilisant:
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrcAprès cela, achetez le fichier bashrc et vérifiez CUDA_HOME:
source ~ /.bashrc
echo $CUDA_HOMEDans cet exemple, /path/to/cuda-11.3 doit être remplacé par le chemin où votre boîte à outils CUDA est installée. You can find this by typing which nvcc in your terminal:
Par exemple, si la sortie est / usr / local / cuda / bin / nvcc, alors:
export CUDA_HOME=/usr/local/cudaInstallation:
1.Clone le référentiel de base de GroundingDino de GitHub.
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..Vérifiez votre identifiant GPU (seulement si vous utilisez un GPU)
nvidia-smi Replace {GPU ID} , image_you_want_to_detect.jpg , and "dir you want to save the output" with appropriate values in the following command
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu modeSi vous souhaitez spécifier les phrases à détecter, voici une démo:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode Le token_spans spécifie les positions de début et de fin d'une phrase. For example, the first phrase is [[9, 10], [11, 14]] . "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' . Hence it refers to the phrase a cat . Similarly, the [[19, 20], [21, 24]] refers to the phrase a dog .
See the demo/inference_on_a_image.py for more details.
Courir avec Python:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )Ui Web
Nous fournissons également un code de démonstration pour intégrer la mise à la terre Dino avec une interface utilisateur Web Gradio. See the file demo/gradio_app.py for more details.
Cahiers
Nous fournissons un exemple pour évaluer les performances de la mise à la terre de Dino Zero sur Coco. The results should be 48.5 .
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
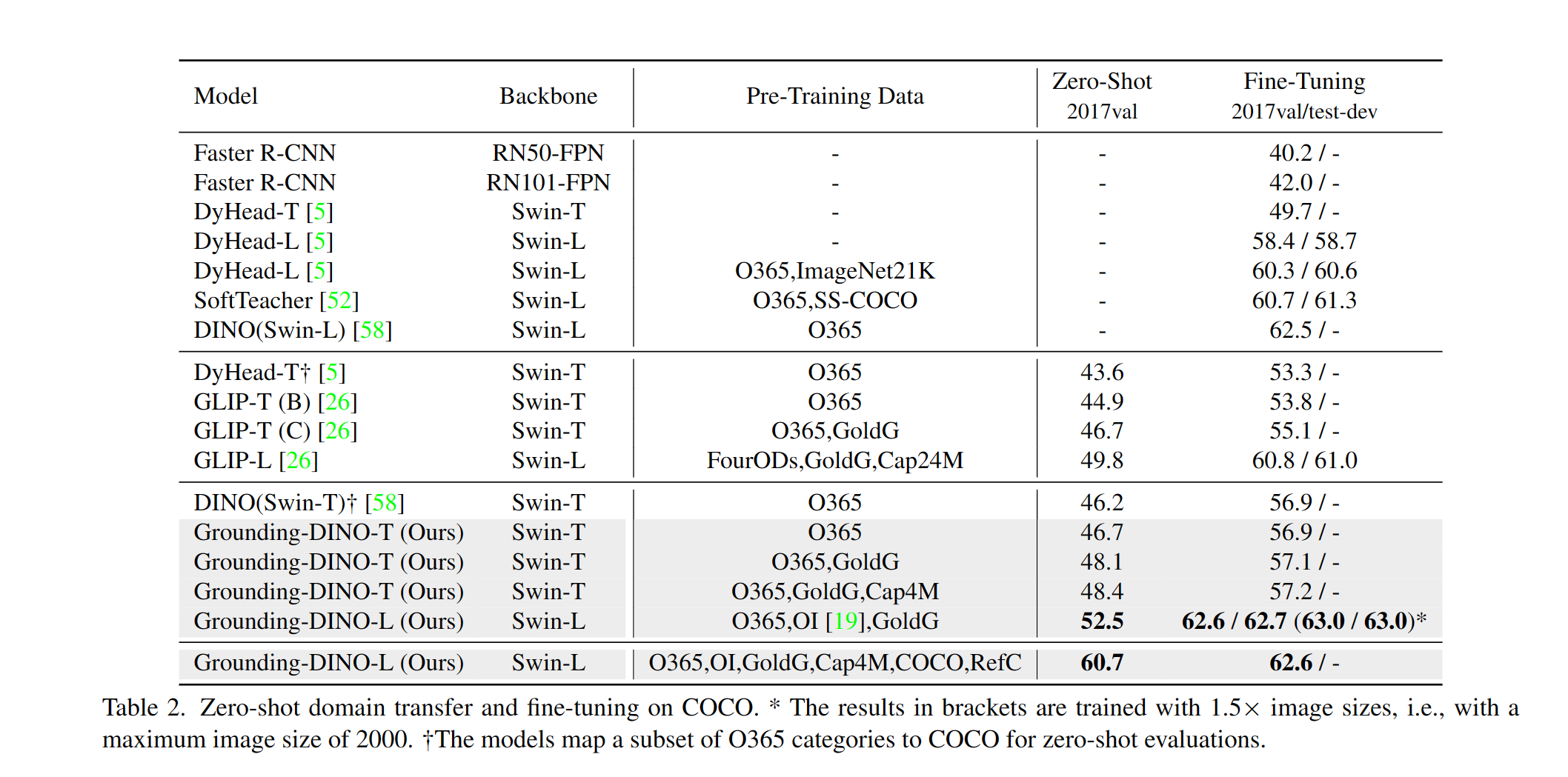
--image_dir /path/to/imagedir/ie/val2017| nom | colonne vertébrale | Données | Box AP sur Coco | Point de contrôle | Configurer | |
|---|---|---|---|---|---|---|
| 1 | GroundingDino-T | Swin-t | O365, GOLDG, CAP4M | 48.4 (zéro-shot) / 57.2 (affineur) | Lien github | Lien hf | lien |
| 2 | GroundingDino-B | Swin-b | Coco, O365, Goldg, Cap4M, OpenImage, Odinw-35, Refcoco | 56.7 | Lien github | Lien hf | lien |
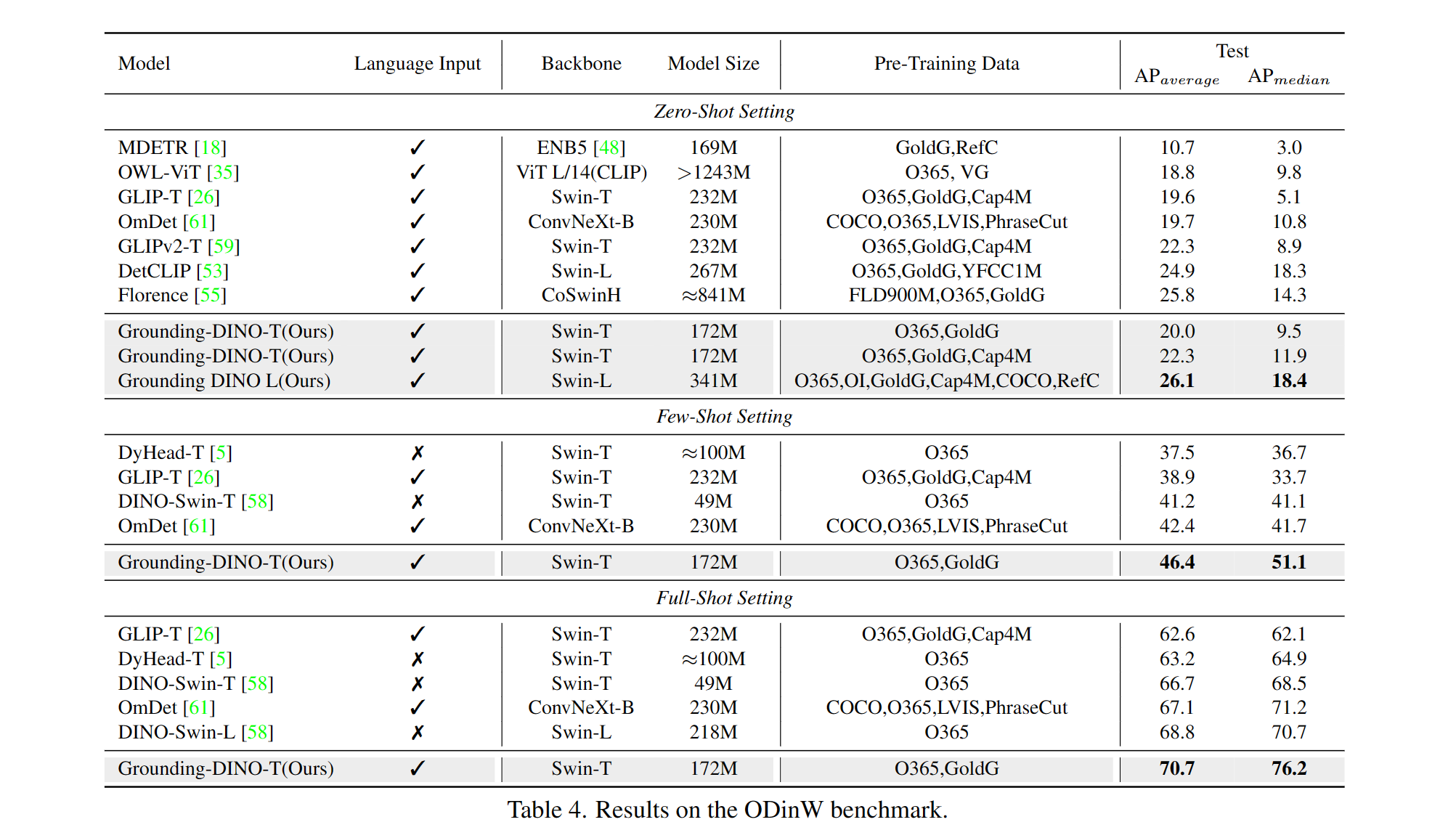

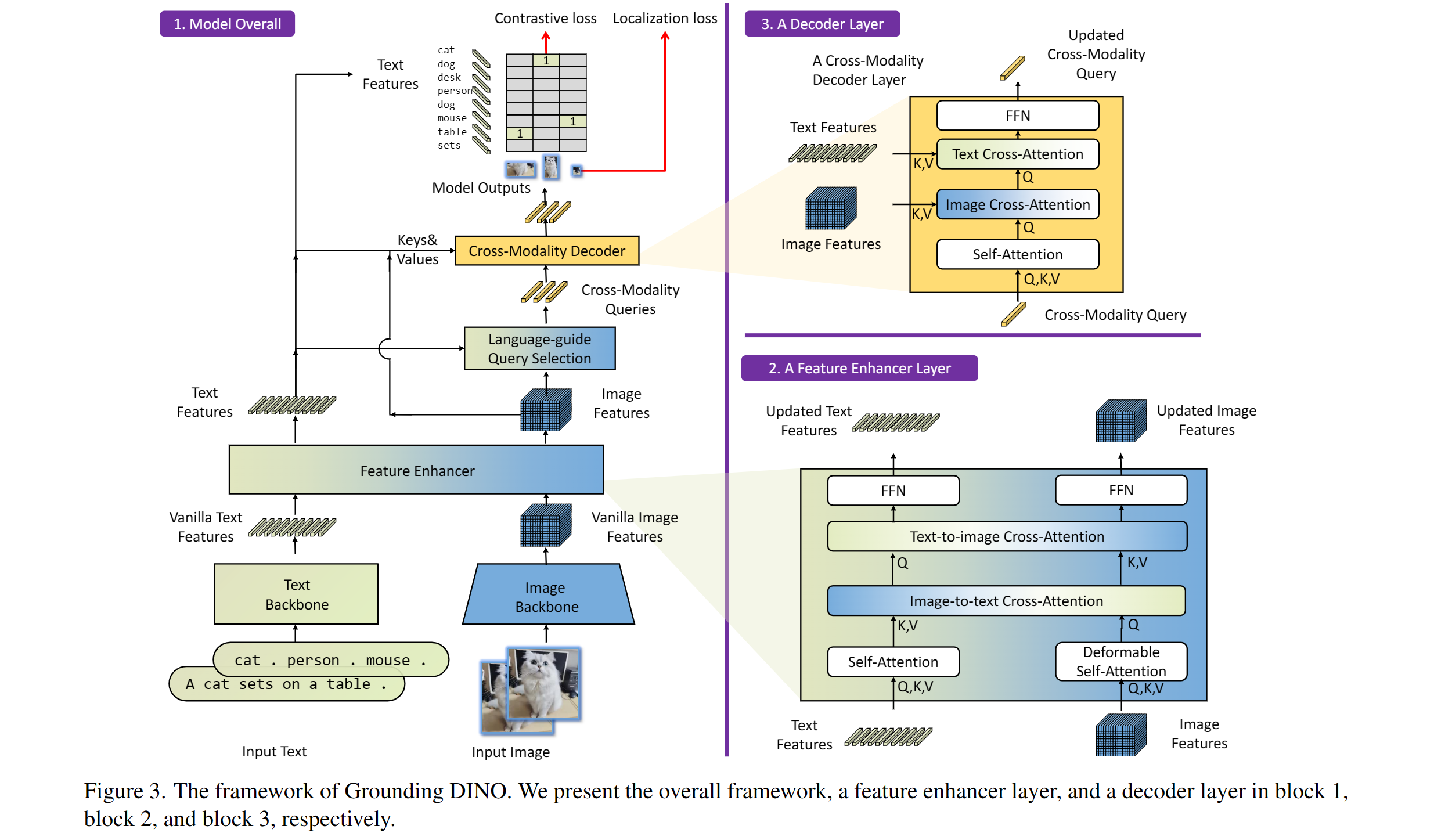
Comprend: une épine dorsale de texte, une épine dorsale d'image, un amplificateur de fonctionnalité, une sélection de requête guidée par le langage et un décodeur croisé.
Notre modèle est lié à Dino et Glip. Merci pour leur excellent travail!
Nous remercions également de grands travaux antérieurs, notamment Detr, Detr déformable, SMCA, DETR conditionnel, Anchor Detr, Dynamic Detr, Dab-Det, DN-Det, etc. Des travaux plus liés sont disponibles dans un transformateur de détection impressionnant. Une nouvelle boîte à outils Detrex est également disponible.
Merci de diffusion stable et de Gligen pour leurs modèles impressionnants.
Si vous trouvez notre travail utile pour vos recherches, veuillez envisager de citer l'entrée Bibtex suivante.
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

