vision_transformer
1.0.0
Dans ce référentiel, nous publions des modèles à partir des articles
Les modèles ont été formés sur les ensembles de données ImageNet et ImageNet-21k. Nous fournissons le code pour affiner les modèles publiés dans Jax / Flax.
Les modèles de cette base de code ont été initialement formés à https://github.com/google-research/big_vision/ où vous pouvez trouver un code plus avancé (par exemple, une formation multi-host), ainsi que certains des scripts de formation originaux (par exemple configs /vit_i21k.py pour la pré-formation d'un VIT, ou configs / transfert.py pour le transfert d'un modèle).
Table des matières:
Sous les colabs fonctionnent à la fois avec les GPU et les TPU (8 cœurs, parallélisme des données).
Le premier colab montre le code JAX des transformateurs de vision et les mélangeurs MLP. Ce Colab vous permet de modifier les fichiers du référentiel directement dans l'interface utilisateur Colab et a des cellules Colab annotées qui vous guident à travers le code étape par étape, et vous permet d'interagir avec les données.
https://colab.research.google.com/github/google-research/vision_transformrer/blob/main/vit_jax.ipynb
Le deuxième colab vous permet d'explorer le transformateur de vision> 50k et les points de contrôle hybrides qui ont été utilisés pour générer les données du troisième article "Comment former votre VIT? ...". Le Colab comprend du code pour explorer et sélectionner les points de contrôle, et faire l'inférence à la fois en utilisant le code JAX à partir de ce référentiel, et également en utilisant la populaire bibliothèque timm Pytorch qui peut également charger directement ces points de contrôle. Notez qu'une poignée de modèles sont également disponibles directement auprès de TF-HUB: Sayakpaul / Collections / Vision_Transformrer (contribution externe de Sayak Paul).
Le deuxième Colab vous permet également d'adapter les points de contrôle sur n'importe quel ensemble de données TFDS et votre propre ensemble de données avec des exemples dans des fichiers JPEG individuels (éventuellement en lisant directement à partir de Google Drive).
https://colab.research.google.com/github/google-research/vision_transformrer/blob/main/vit_jax_augreg.ipynb
Remarque : pour l'instant (6/20/21) Google Colab ne prend en charge qu'un seul GPU (NVIDIA Tesla T4), et les TPU (actuellement TPUV2-8) sont attachés indirectement à la machine virtuelle Colab et communiquent sur un réseau lent, ce qui conduit à Jolie Mauvaise vitesse d'entraînement. Vous souhaitez généralement configurer une machine dédiée si vous avez une quantité non triviale de données à affiner. Pour plus de détails, consultez la section Running on Cloud.
Assurez-vous que Python>=3.10 est installé sur votre machine.
Installez les dépendances JAX et Python en fonctionnant:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
Pour les versions plus récentes de JAX, suivez les instructions fournies dans le référentiel correspondant lié ici. Notez que les instructions d'installation pour CPU, GPU et TPU diffèrent légèrement.
Installez Flaxformer, suivez les instructions fournies dans le référentiel correspondant lié ici.
Pour plus de détails, reportez-vous à la section exécutée sur le cloud ci-dessous.
Vous pouvez exécuter le réglage fin du modèle téléchargé sur votre ensemble de données d'intérêt. Tous les modèles partagent la même interface de ligne de commande.
Par exemple pour le réglage fin d'un VIT-B / 16 (pré-formé sur ImageNet21k) sur CIFAR10 (notez comment nous spécifions b16,cifar10 comme arguments à la configuration, et comment nous demandons au code d'accéder aux modèles directement à partir d'un seau GCS Au lieu de les télécharger d'abord dans le répertoire local):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'Afin de affiner un mélangeur-b / 16 (pré-formé sur ImageNet21k) sur CIFAR10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' Le papier "Comment former votre VIT? ..." Ajout> points de contrôle 50k que vous pouvez affiner avec la configuration configs/augreg.py . Lorsque vous spécifiez uniquement le nom du modèle (la valeur config.name à partir de configs/model.py ), le meilleur point de contrôle I21K par précision de validation en amont (point de contrôle "recommandé", voir la section 4.5 du document) est choisi. Pour décider du modèle que vous souhaitez utiliser, consultez la figure 3 dans le papier. Il est également possible de choisir un point de contrôle différent (voir colab vit_jax_augreg.ipynb ), puis spécifier la valeur de la colonne filename ou adapt_filename , qui correspondent aux noms de fichiers sans .npz du répertoire gs://vit_models/augreg .
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 Actuellement, le code télécharge automatiquement les ensembles de données CIFAR-10 et CIFAR-100. D'autres ensembles de données publics ou personnalisés peuvent être facilement intégrés, à l'aide de la bibliothèque de jeux de données TensorFlow. Notez que vous devrez également mettre à jour vit_jax/input_pipeline.py pour spécifier certains paramètres sur tout ensemble de données ajouté.
Notez que notre code utilise tous les GPU / TPU disponibles pour le réglage fin.
Pour voir une liste détaillée de tous les drapeaux disponibles, exécutez python3 -m vit_jax.train --help .
Remarques sur la mémoire:
--config.accum_steps=8 - Alternativement, vous pouvez également diminuer le --config.batch=512 (et diminuer --config.base_lr en conséquence).--config.shuffle_buffer=50000 . Par Alexey Dosovitskiy * †, Lucas Beyer *, Alexander Kolesnikov *, Dirk Weissenborn *, Xiaohua Zhai *, Thomas Unterhiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit et Neil Houlsby * †.
(*) Contribution technique égale, (†) Conseil égal.
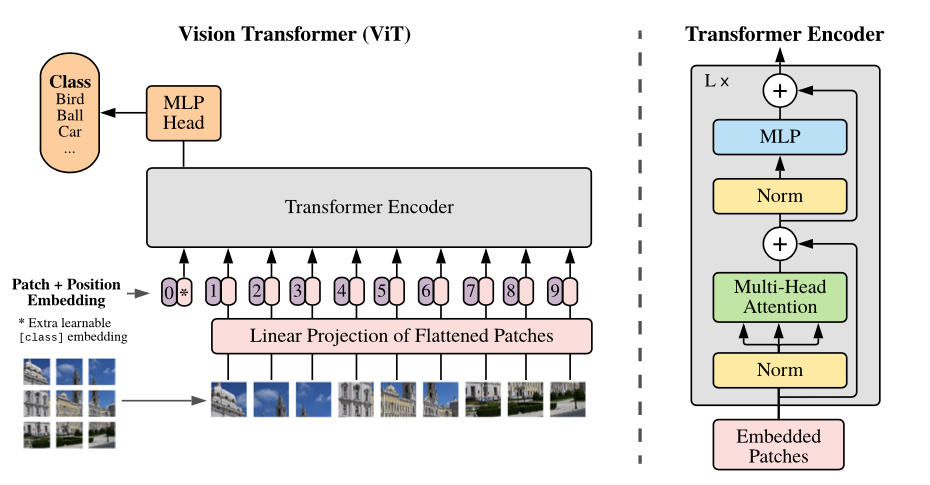
Présentation du modèle: nous divisons une image en patchs de taille fixe, intégrant linéairement chacun d'eux, ajoutez des incorporations de position et nourrissez la séquence résultante de vecteurs à un encodeur de transformateur standard. Afin d'effectuer une classification, nous utilisons l'approche standard pour ajouter un «jeton de classification» à l'apprentissage supplémentaire à la séquence.
Nous fournissons une variété de modèles VIT dans différents seaux GCS. Les modèles peuvent être téléchargés avec EG:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Les noms de fichiers du modèle (sans l'extension .npz ) correspondent à la config.model_name in vit_jax/configs/models.py
gs://vit_models/imagenet21k - Modèles pré-formés sur ImageNet-21k.gs://vit_models/imagenet21k+imagenet2012 - Modèles pré-formés sur ImageNet-21k et affinés sur ImageNet.gs://vit_models/augreg - Modèles pré-formés sur ImageNet-21K, en appliquant des quantités variables d'AuGreg. Performances améliorées.gs://vit_models/sam - Modèles pré-formés sur ImageNet avec SAM.gs://vit_models/gsam - Modèles pré-formés sur ImageNet avec GSAM.Nous vous recommandons d'utiliser les points de contrôle suivants, formés avec Augreg qui ont les meilleures mesures de pré-formation:
| Modèle | Point de contrôle pré-formé | Taille | Point de contrôle affiné | Résolution | IMG / SEC | Précision d'imaget |
|---|---|---|---|---|---|---|
| L / 16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85,59% |
| B / 16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85,49% |
| S / 16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83,73% |
| R50 + L / 32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85,99% |
| R26 + S / 32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83,85% |
| Ti / 16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78,22% |
| B / 32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83,59% |
| S / 32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79,58% |
| R + ti / 16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75,40% |
Les résultats du papier VIT d'origine (https://arxiv.org/abs/2010.11929) ont été reproduits à l'aide des modèles de gs://vit_models/imagenet21k :
| modèle | ensemble de données | abandon = 0,0 | abandon = 0,1 |
|---|---|---|---|
| R50 + Vit-B_16 | cifar10 | 98,72%, 3,9h (A100), tb.dev | 98,94%, 10.1h (v100), tb.dev |
| R50 + Vit-B_16 | CIFAR100 | 90,88%, 4.1h (A100), tb.dev | 92,30%, 10.1h (V100), TB.DEV |
| R50 + Vit-B_16 | ImageNet2012 | 83,72%, 9,9h (A100), TB.Dev | 85,08%, 24,2H (V100), TB.DEV |
| Vit-b_16 | cifar10 | 99,02%, 2.2H (A100), TB.DEV | 98,76%, 7,8h (V100), TB.Dev |
| Vit-b_16 | CIFAR100 | 92,06%, 2.2H (A100), TB.DEV | 91,92%, 7,8H (V100), TB.DEV |
| Vit-b_16 | ImageNet2012 | 84,53%, 6,5h (A100), TB.Dev | 84,12%, 19,3H (V100), tb.dev |
| Vit-b_32 | cifar10 | 98,88%, 0,8h (A100), TB.Dev | 98,75%, 1,8h (V100), TB.Dev |
| Vit-b_32 | CIFAR100 | 92,31%, 0,8h (A100), TB.Dev | 92,05%, 1,8H (V100), TB.DEV |
| Vit-b_32 | ImageNet2012 | 81,66%, 3,3H (A100), TB.DEV | 81,31%, 4,9h (V100), TB.DEV |
| Vit-l_16 | cifar10 | 99,13%, 6,9h (A100), TB.DEV | 99,14%, 24,7H (V100), TB.DEV |
| Vit-l_16 | CIFAR100 | 92,91%, 7.1h (A100), TB.DEV | 93,22%, 24,4H (V100), TB.DEV |
| Vit-l_16 | ImageNet2012 | 84,47%, 16,8H (A100), TB.DEV | 85,05%, 59,7H (V100), TB.DEV |
| Vit-l_32 | cifar10 | 99,06%, 1,9h (A100), tb.dev | 99,09%, 6.1h (V100), TB.DEV |
| Vit-l_32 | CIFAR100 | 93,29%, 1,9h (A100), tb.dev | 93,34%, 6.2H (V100), TB.DEV |
| Vit-l_32 | ImageNet2012 | 81,89%, 7,5h (A100), TB.Dev | 81,13%, 15,0h (V100), tb.dev |
Nous souhaitons également souligner que les résultats de haute qualité peuvent être obtenus avec des horaires de formation plus courts et encourager les utilisateurs de notre code à jouer avec des hyper-paramètres pour compromettre la précision et le budget de calcul. Quelques exemples pour les ensembles de données CIFAR-10/100 sont présentés dans le tableau ci-dessous.
| en amont | modèle | ensemble de données | total_steps / warmup_steps | précision | Temps mural | lien |
|---|---|---|---|---|---|---|
| Imagenet21k | Vit-b_16 | cifar10 | 500/50 | 98,59% | 17m | Tensorboard.dev |
| Imagenet21k | Vit-b_16 | cifar10 | 1000/100 | 98,86% | 39m | Tensorboard.dev |
| Imagenet21k | Vit-b_16 | CIFAR100 | 500/50 | 89,17% | 17m | Tensorboard.dev |
| Imagenet21k | Vit-b_16 | CIFAR100 | 1000/100 | 91,15% | 39m | Tensorboard.dev |
Par Ilya Tolstikhin *, Neil Houlsby *, Alexander Kolesnikov *, Lucas Beyer *, Xiaohua Zhai, Thomas Unterhiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy.
(*) Contribution égale.
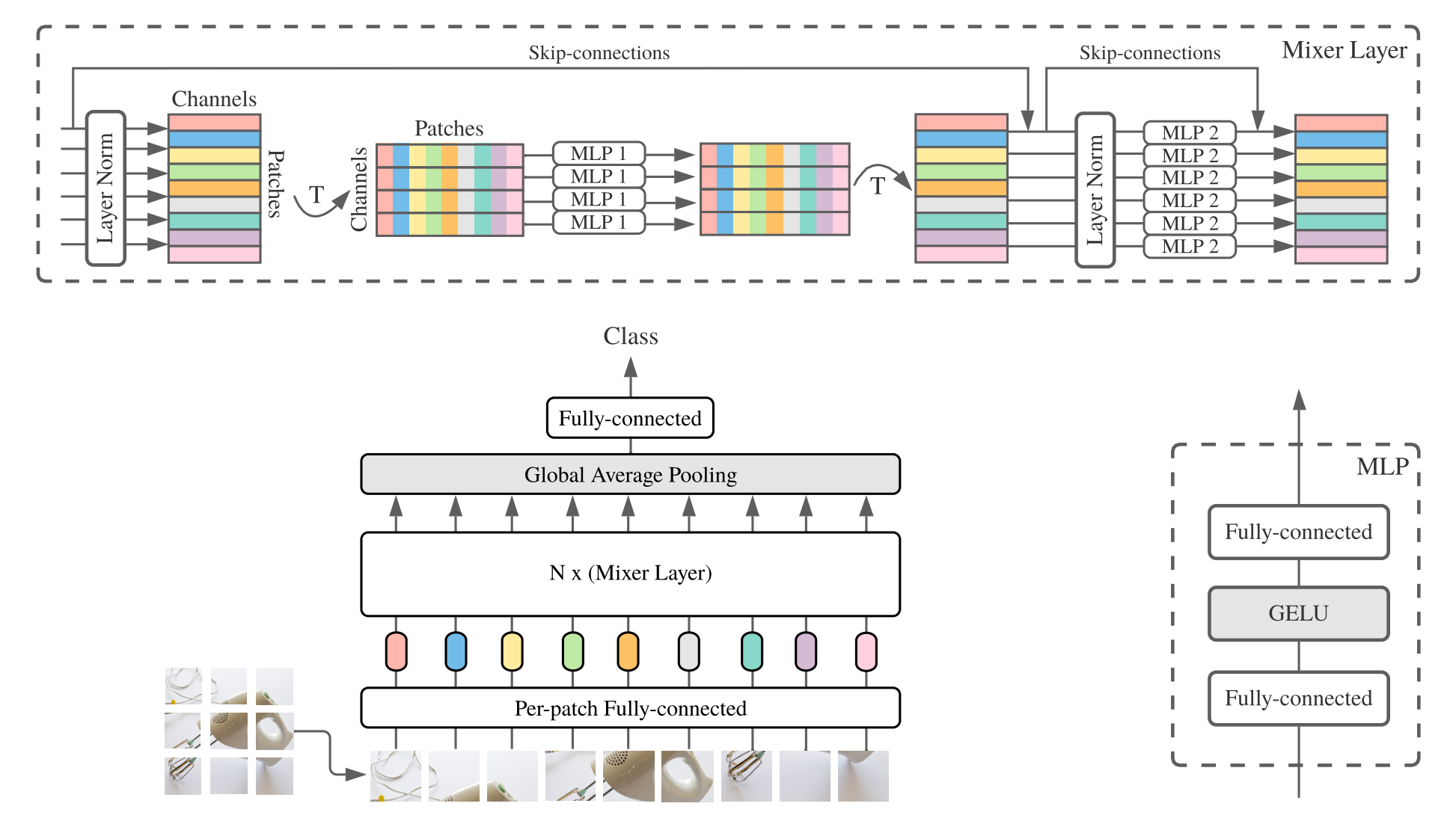
MLP-mixer ( mélangeur pour court-circuit) se compose d'incorporation linéaire par partenaire, de couches de mélangeurs et d'une tête de classificateur. Les couches de mélangeurs contiennent un MLP de mélange de jeton et un MLP de mélange de canaux, chacun composé de deux couches entièrement connectées et d'une non-linéarité Gelu. Les autres composants comprennent: les connexions à sauts, le déprochage et la tête de classificateur linéaire.
Pour l'installation, suivez les mêmes étapes que ci-dessus.
Nous fournissons les modèles mélangeurs-B / 16 et Mixer-L / 16 pré-formés sur les ensembles de données ImageNet et ImageNet-21k. Les détails peuvent être trouvés dans le tableau 3 du papier mélangeur. Tous les modèles peuvent être trouvés sur:
https://console.cloud.google.com/storage/mixer_models/
Notez que ces modèles sont également disponibles directement auprès de TF-Hub: Sayakpaul / Collections / MLP-Mixer (contribution externe de Sayak Paul).
Nous avons exécuté le code fin sur Google Cloud Machine avec quatre GPU V100 avec les paramètres d'adaptation par défaut de ce référentiel. Voici les résultats:
| en amont | modèle | ensemble de données | précision | wall_clock_time | lien |
|---|---|---|---|---|---|
| Imagenet | Mixer-B / 16 | cifar10 | 96,72% | 3.0h | Tensorboard.dev |
| Imagenet | Mixer-L / 16 | cifar10 | 96,59% | 3.0h | Tensorboard.dev |
| Imagenet-21k | Mixer-B / 16 | cifar10 | 96,82% | 9,6h | Tensorboard.dev |
| Imagenet-21k | Mixer-L / 16 | cifar10 | 98,34% | 10h0 | Tensorboard.dev |
Pour plus de détails, reportez-vous à l'article de blog Google AI Lit: Ajouter une compréhension du langage aux modèles d'image ou lire le papier CVPR "Lit: transfert de zéro-shot avec un tuning texte verrouillé" (https://arxiv.org/abs/2111.07991 ).
Nous avons publié un modèle transformateur B / 16-base avec une précision de zéroshot ImageNet de 72,1%, et un modèle L / 16 de plus avec une précision Zeroshot Imagenet de 75,7%. Pour plus de détails sur ces modèles, veuillez vous référer à la carte du modèle LIT.
Nous fournissons une démo de navigateur avec de petits encodeurs de texte pour une utilisation interactive (les plus petits modèles devraient même fonctionner sur un téléphone portable moderne):
https://google-research.github.io/Vision_transformrer/lit/
Et enfin un colab pour utiliser les modèles JAX avec des encodeurs d'image et de texte:
https://colab.research.google.com/github/google-research/vision_transformrer/blob/main/lit.ipynb
Notez qu'aucun des modèles ci-dessus ne prend en charge les entrées multilingues, mais nous travaillons sur la publication de ces modèles et mettra à jour ce référentiel une fois qu'ils seront disponibles.
Ce référentiel ne contient que du code d'évaluation pour les modèles LIT. Vous pouvez trouver le code de formation dans le référentiel big_vision :
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
Les résultats du zéroshot attendus de model_cards/lit.md (notez que l'évaluation du zéroshot est légèrement différente de l'évaluation simplifiée dans le colab):
| Modèle | B16b_2 | L16L |
|---|---|---|
| Imagenet zéro-shot | 73,9% | 75,7% |
| Imagenet v2 zéro-shot | 65,1% | 66,6% |
| Cifar100 zéro-shot | 79,0% | 80,5% |
| PETS37 ZERO-Shot | 83,3% | 83,3% |
| Resisc45 zéro-shot | 25,3% | 25,6% |
| Cénigène MS-COCO | 51,6% | 48,5% |
| Ségendes MS-COCO | 31,8% | 31,1% |
Bien que les Colabs soient assez utiles pour commencer, vous voudriez généralement vous entraîner sur une machine plus grande avec des accélérateurs plus puissants.
Vous pouvez utiliser les commandes suivantes pour configurer une machine virtuelle avec des GPU sur Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEAlternativement, vous pouvez utiliser les commandes similaires suivantes pour configurer une machine virtuelle Cloud avec TPUS qui leur est attachée (Commandes ci-dessous copiées à partir du tutoriel TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME Puis récupérer le référentiel et les dépendances d'installation (y compris jaxlib avec le support TPU) comme d'habitude:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateSi vous êtes connecté à une machine virtuelle avec des GPU attachés, installez JAX et d'autres dépendances avec la commande suivante:
pip install -r vit_jax/requirements.txtSi vous êtes connecté à une machine virtuelle avec TPUS attachée, installez JAX et d'autres dépendances avec la commande suivante:
pip install -r vit_jax/requirements-tpu.txtInstallez Flaxformer, suivez les instructions fournies dans le référentiel correspondant lié ici.
Pour les GPU et les TPU, vérifiez que Jax peut se connecter aux accélérateurs connectés avec la commande:
python -c ' import jax; print(jax.devices()) 'Et enfin exécuter l'une des commandes mentionnées dans la section Fonctionner un modèle.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
Dans l'ordre chronologique inverse:
2022-08-18: Ajout du modèle LIT-B16B_2 qui a été formé pour 60k étapes (LIT_B16B: 30K) sans tête linéaire du côté de l'image (LIT_B16B: 768) et a de meilleures performances.
2022-06-09: Ajout des modèles Vit et Mixer entraînés à partir de zéro en utilisant GSAM sur ImageNet sans augmentation de données fortes. Les vites résultantes surpassent celles de tailles similaires formées à l'aide d'ADAMW Optimizer ou de l'algorithme SAM d'origine, ou avec de fortes augmentations de données.
2022-04-14: Modèles ajoutés et Colab pour les modèles LIT.
2021-07-29: Ajout de modèles Vit-B / 8 Augreg (3 points de contrôle en amont et adaptations avec résolution = 224).
2021-07-02: Ajout du papier "Lorsque Vision Transformers surpasserait les ressonnets ..."
2021-07-02: Ajout de points de contrôle SAM (minimisation de la netteté) VIT et MLP-Mixer.
2021-06-20: Ajout du papier "Comment former votre VIT? ..." et un nouveau colab pour explorer les points de contrôle pré-formés et affinés de 50k mentionnés dans le journal.
2021-06-18: Ce référentiel a été réécrit pour utiliser l'API de lin de lin et ml_collections.ConfigDict pour la configuration.
2021-05-19: Avec la publication du papier "Comment former votre VIT? ...", nous avons ajouté plus de 50 000 modèles VIT et hybrides pré-formés sur ImageNet et ImageNet-21k avec divers degrés d'augmentation des données et de régularisation du modèle , et affiné sur ImageNet, PETS37, Kitti-Distance, Cifar-100 et Resisc45. Consultez vit_jax_augreg.ipynb pour naviguer dans ce trésor de modèles! Par exemple, vous pouvez utiliser ce colab pour récupérer les noms de fichiers des points de contrôle pré-formés et affinés recommandés de la colonne i21k_300 du tableau 3 dans le papier.
2020-12-01: Ajout du modèle hybride R50 + Vit-B / 16 (Vit-B / 16 au-dessus d'une colonne vertébrale RESNET-50). Lorsqu'il est pré-entraîné sur IMAMENET21K, ce modèle atteint presque les performances du modèle L / 16 avec moins de la moitié du coût de financement de calcul. Notez que "R50" est quelque peu modifié pour la variante B / 16: le RESNET-50 d'origine a des blocs [3,4,6,3], chacun réduisant la résolution de l'image par un facteur de deux. En combinaison avec la tige Resnet, cela entraînerait une réduction de 32x, donc même avec une taille de patch de (1,1), la variante Vit-B / 16 ne peut plus être réalisée. Pour cette raison, nous utilisons à la place [3,4,9] blocs pour la variante R50 + B / 16.
2020-11-09: Ajout du modèle Vit-L / 16.
2020-10-29: Ajout de modèles Vit-B / 16 et Vit-L / 16 pré-entraînés sur ImageNet-21k puis affinés sur ImageNet à une résolution 224x224 (au lieu de par défaut 384x384). Ces modèles ont le suffixe "-224" en leur nom. On s'attend à ce qu'ils atteignent respectivement 81,2% et 82,7% des précisions top-1.
Libération open source préparée par Andreas Steiner.
Remarque: Ce référentiel a été fourchu et modifié à partir de Google-Research / Big_Transfer.
Ce n'est pas un produit Google officiel.


