Awesome LLM 3D
1.0.0
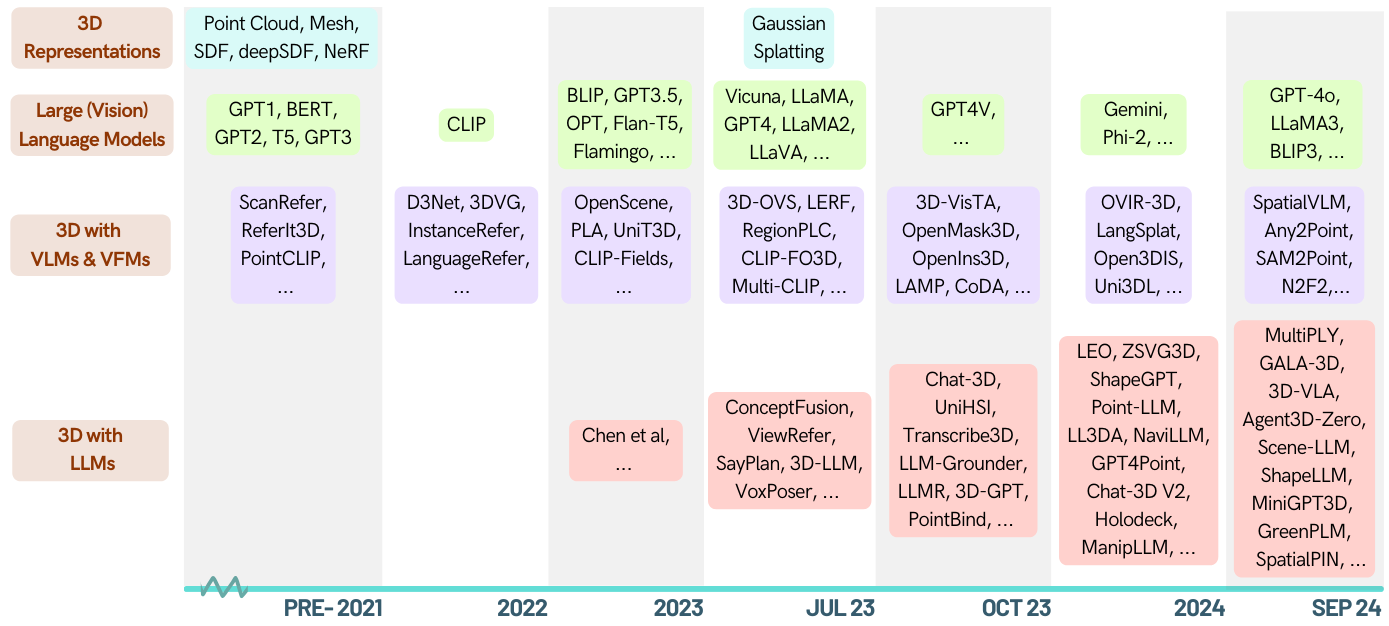
Voici une liste organisée d'articles sur des tâches liées à la 3D habilitées par les modèles de grande langue (LLM). Il contient diverses tâches, notamment la compréhension 3D, le raisonnement, la génération et les agents incarnés. De plus, nous incluons d'autres modèles de fondation (Clip, SAM) pour l'ensemble de l'image de ce domaine.
Il s'agit d'un référentiel actif, vous pouvez surveiller pour suivre les dernières avancées. Si vous le trouvez utile, veuillez jouer ce repo et citer le papier.
[2024-05-16]? Découvrez le premier document d'enquête dans le domaine 3D-LLM: lorsque les LLM entrent dans le monde 3D: une enquête et une méta-analyse des tâches 3D via des modèles de langage multimodal
[2024-01-06] Runsen Xu a ajouté des informations chronologiques et Xianzheng MA l'a réorganisée dans l'ordre ZA pour mieux après les dernières avancées.
[2023-12-16] Xianzheng MA et Yash Bhalgat ont organisé cette liste et publié la première version;
Génial-llm-3d
Compréhension 3D (LLM)
Compréhension 3D (autres modèles de fondation)
Raisonnement 3D
Génération 3D
Agent incarné 3D
Benchmarks 3D
Contributif
| Date | Mots clés | Institut (premier) | Papier | Publication | Autres |
|---|---|---|---|---|---|
| 2024-10-12 | Situation3d | Uiuc | La conscience de la situation est importante dans le raisonnement de la langue de la vision 3D | CVPR '24 | projet |
| 2024-09-28 | Llava-3d | HKU | LLAVA-3D: Une voie simple mais efficace pour autonomiser les LMM avec une sensibilisation 3D | Arxiv | projet |
| 2024-09-08 | MSR3D | Bigai | Raisonnement situé à plusieurs modales dans des scènes 3D | Neirips '24 | projet |
| 2024-08-28 | GreenPlm | Bousculer | Plus de texte, moins de point: vers une compréhension de la langue ponctuelle économe en 3D | Arxiv | github |
| 2024-06-17 | Llana | Unibo | LLANA: Assistant de grande langue et nerf | Neirips '24 | projet |
| 2024-06-07 | Spatialpin | Oxford | SpatialPin: Amélioration des capacités de raisonnement spatial des modèles de langue visuelle en invitant et en interagissant les priors 3D | Neirips '24 | projet |
| 2024-06-03 | Spatialrgpt | UCSD | Spatialrgpt: raisonnement spatial fondé dans les modèles de langage de vision | Neirips '24 | github |
| 2024-05-02 | Minigpt-3d | Bousculer | MINIGPT-3D: Alignant efficacement les nuages de points 3D avec de grands modèles de langue en utilisant des priors 2D | ACM MM '24 | projet |
| 2024-02-27 | Éteindre | Xjtu | Shapellm: compréhension universelle des objets 3D pour l'interaction incarnée | Arxiv | projet |
| 2024-01-22 | Spatialvlm | Google Deepmind | SpatialVLM: dominant des modèles de langue visuelle avec des capacités de raisonnement spatial | CVPR '24 | projet |
| 2023-12-21 | Lidar-llm | Pku | Lidar-llm: Explorer le potentiel des modèles de grande langue pour la compréhension du LiDAR 3D | Arxiv | projet |
| 2023-12-15 | 3dap | Shanghai Ai Lab | 3DaxiesPrompts: libérer les capacités de tâche spatiale 3D de GPT-4V | Arxiv | projet |
| 2023-12-13 | Chat de chat | Zju | Chat-Scene: Bridging 3D Scene et de grands modèles de langue avec des identifiants d'objet | Neirips '24 | github |
| 2023-12-5 | Gpt4point | HKU | GPT4Point: un cadre unifié pour la compréhension et la génération en langue ponctuelle | Arxiv | github |
| 2023-11-30 | Ll3da | Université Fudan | LL3DA: réglage de l'instruction interactive visuelle pour la compréhension, le raisonnement et la planification OMNI-3D | Arxiv | github |
| 2023-11-26 | Zsvg3d | Cuhk (SZ) | Programmation visuelle pour la mise à la terre visuelle 3D | Arxiv | projet |
| 2023-11-18 | LION | Bigai | Un agent généraliste incarné dans le monde 3D | Arxiv | github |
| 2023-10-14 | Jm3d-llm | Université de Xiamen | JM3D & JM3D-LLM: Élévation de la représentation 3D avec des signaux multimodaux conjoints | ACM MM '23 | github |
| 2023-10-10 | Uni3d | Baai | UNI3D: Explorer la représentation 3D unifiée à grande échelle | ICLR '24 | projet |
| 2023-9-27 | - | Kauste | Correspondance de forme 3D à tirs zéro | Siggraph Asia '23 | - |
| 2023-9-21 | LLM-Grouner | U-mich | LLM-Grouner: Open-Vocabulary 3D Visual Forming with Big Language Model en tant qu'agent | ICRA '24 | github |
| 2023-9-1 | Point de point | Cuhk | Point-Bind & Point-llm: Alignez le nuage de points avec multimodalité pour la compréhension, la génération et l'instruction 3D | Arxiv | github |
| 2023-8-31 | Pointllm | Cuhk | Pointllm: autonomiser les modèles de gros langues pour comprendre les nuages ponctuels | ECCV '24 | github |
| 2023-8-17 | CHAT-3D | Zju | CHAT-3D: Modélisation de la langue en éfficacité des données pour le dialogue universel des scènes 3D | Arxiv | github |
| 2023-8-8 | 3D-VISTA | Bigai | 3D-VISTA: Transformateur pré-formé pour la vision 3D et l'alignement du texte | ICCV '23 | github |
| 2023-7-24 | 3d-llm | Ucla | 3D-LLM: Injection du monde 3D dans de grands modèles de langue | Neirips '23 | github |
| 2023-3-29 | ViewRefer | Cuhk | ViewRefer: saisissez les connaissances multi-visualités pour la mise à la terre visuelle 3D | ICCV '23 | github |
| 2022-9-12 | - | Mit | Tirer parti de grands modèles de langage (visuels) pour la compréhension de la scène 3D Robot | Arxiv | github |
| IDENTIFIANT | mots clés | Institut (premier) | Papier | Publication | Autres |
|---|---|---|---|---|---|
| 2024-10-12 | Lexique3d | Uiuc | Lexicon3d: sonder des modèles de fond de base visuelle pour la compréhension de la scène 3D complexe | Neirips '24 | projet |
| 2024-10-07 | Diff2Scene | CMU | Segmentation sémantique 3D Open-Vocabulary avec des modèles de diffusion de texte à l'image | ECCV 2024 | projet |
| 2024-04-07 | Any2point | Shanghai Ai Lab | Any2point: autonomiser les grands modèles de tout modalité pour une compréhension 3D efficace | ECCV 2024 | github |
| 2024-03-16 | N2f2 | Oxford-VGG | N2F2: compréhension de la scène hiérarchique avec des champs de caractéristiques neuronales imbriquées | Arxiv | - |
| 2023-12-17 | Sai3d | Pku | SAI3D: segmenter n'importe quelle instance dans les scènes 3D | Arxiv | projet |
| 2023-12-17 | Open3dis | Vinai | Open3DIS: Segmentation des instances 3D à vocabule ouverte avec guidage du masque 2D | Arxiv | projet |
| 2023-11-6 | OVIR-3D | Université Rutgers | OVIR-3D: récupération des instances 3D à vocabulaire ouvert sans formation sur les données 3D | Corl '23 | github |
| 2023-10-29 | OpenMask3d | Eth | OpenMask3d: Segmentation des instances 3D à vocabulaire ouvert | Neirips '23 | projet |
| 2023-10-5 | Fusion ouverte | - | Fusion ouverte: cartographie 3D en temps ouvert en temps ouvert et représentation de scène interrogable | Arxiv | github |
| 2023-9-22 | OV-3DDET | Hkust | CODA: découverte de boîtes de roman collaborative et alignement intermodal pour la détection d'objets 3D à vocabulaire ouvert | Neirips '23 | github |
| 2023-9-19 | LAMPE | - | De la langue aux mondes 3D: Adapting Language Model for Point Cloud Perception | OpenReview | - |
| 2023-9-15 | Opennerf | - | Opennerf: Open Set 3D Neural Scene Segmentation avec des fonctionnalités de pixels et des vues nouvelles rendues | OpenReview | github |
| 2023-9-1 | OpenInS3d | Cambridge | OpenInInS3D: SNAP et recherche pour la segmentation des instances 3D Open-Vocabulary | Arxiv | projet |
| 2023-6-7 | Lifting contrastif | Oxford-VGG | Lift contrastif: segmentation des instances d'objet 3D par fusion contrastive lente | Neirips '23 | github |
| 2023-6-4 | Multi-piles | Eth | Multi-CLIP: pré-formation de langue de vision contrastive pour les tâches de réponse aux questions dans les scènes 3D | Arxiv | - |
| 2023-5-23 | 3D-OV | NTU | Segmentation faiblement supervisée de la vocabulerie ouverte 3D | Neirips '23 | github |
| 2023-5-21 | Champs VL | Université d'Édimbourg | Champs VL: vers des représentations spatiales implicites neuronales fondées sur la langue | ICRA '23 | projet |
| 2023-5-8 | Clip-fo3d | Université Tsinghua | Clip-Fo3d: Apprentissage des représentations de scène 3D Open World gratuites à partir d'un clip dense 2D | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | Eth | Pré-formation en langue visuelle guidée par clip pour la réponse aux questions dans les scènes 3D | CVPRW '23 | github |
| 2023-4-3 | RegionPlc | HKU | RegionPlc: Apprentissage contrastif régional en langage ponctuel pour la compréhension de la scène 3D en monde ouvert | Arxiv | projet |
| 2023-3-20 | Cg3d | Jhu | Clip Goes 3D: Tirant le réglage rapide de la reconnaissance 3D fondée sur la langue | Arxiv | github |
| 2023-3-16 | Lerf | UC Berkeley | Lerf: champs de radiance intégrés linguistiques | ICCV '23 | github |
| 2023-2-14 | Conceptfusion | Mit | Conceptfusion: cartographie 3D multimodale en scène ouverte | RSS '23 | projet |
| 2023-1-12 | Clip2Scene | HKU | Clip2Scene: Vers la compréhension de la scène 3D économe en étiquette par Clip | CVPR '23 | github |
| 2022-12-1 | Unité3d | Tumeau | Unit3d: un transformateur unifié pour le sous-titrage dense 3D et la mise à la terre visuelle | ICCV '23 | github |
| 2022-11-29 | PLA | HKU | PLA: Compréhension de la scène 3D open-vocabulaire orientée linguistique | CVPR '23 | github |
| 2022-11-28 | Openscene | Ethz | OpenScene: compréhension de la scène 3D avec des vocabulaires ouverts | CVPR '23 | github |
| 2022-10-11 | Champs de clip | NYU | Champs clip: champs sémantiques faiblement supervisés pour la mémoire robotique | Arxiv | projet |
| 2022-7-23 | Abstraction sémantique | Colombie | Abstraction sémantique: compréhension de la scène 3D du monde ouvert à partir de modèles de vision 2D | Corl '22 | projet |
| 2022-4-26 | Scannet200 | Tumeau | Segmentation sémantique 3D intérieure à la langue dans la nature | ECCV '22 | projet |
| Date | mots clés | Institut (premier) | Papier | Publication | Autres |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | Ucla | Apprentissage du concept 3D et raisonnement à partir d'images multi-visualités | CVPR '23 | github |
| - | Transccrire3d | TTI, Chicago | Transcribe3d: mise à la terre LLMS en utilisant des informations transcrites pour le raisonnement référentiel 3D avec des finetuns auto-corrigées | Corl '23 | github |
| Date | mots clés | Institut | Papier | Publication | Autres |
|---|---|---|---|---|---|
| 2023-11-29 | Shapegpt | Université Fudan | ShapeGPT: génération de forme 3D avec un modèle de langue multimodale unifiée | Arxiv | github |
| 2023-11-27 | Maillot | Tumeau | MeshGPT: Génération de mailles de triangle avec transformateurs uniquement au décodeur | Arxiv | projet |
| 2023-10-19 | 3D-GPT | Anu | 3D-GPT: Modélisation 3D procédurale avec de grands modèles de langue | Arxiv | github |
| 2023-9-21 | LLMR | Mit | LLMR: Invite en temps réel des mondes interactifs en utilisant de grands modèles de langue | Arxiv | - |
| 2023-9-20 | Dreamllm | Mégvii | Dreamllm: compréhension et création synergiques | Arxiv | github |
| 2023-4-1 | Chatavatar | Deemos Tech | DreamFace: Génération progressive de visages 3D animaux sous guidage texte | ACM TOG | site web |
| Date | mots clés | Institut | Papier | Publication | Autres |
|---|---|---|---|---|---|
| 2024-01-22 | Spatialvlm | Profondeur | SpatialVLM: dominant des modèles de langue visuelle avec des capacités de raisonnement spatial | CVPR '24 | projet |
| 2023-11-27 | Dobb-e | NYU | En ramenant les robots à la maison | Arxiv | github |
| 2023-11-26 | Steve | Zju | Voir et penser: agent incarné dans un environnement virtuel | Arxiv | github |
| 2023-11-18 | LION | Bigai | Un agent généraliste incarné dans le monde 3D | Arxiv | github |
| 2023-9-14 | Unihsi | Shanghai Ai Lab | Interaction unifiée à la scène humaine via une chaîne de contact invitée | Arxiv | github |
| 2023-7-28 | Rt-2 | Google-profondeur | RT-2: Les modèles d'action visuelle-action transfèrent les connaissances Web vers un contrôle robotique | Arxiv | github |
| 2023-7-12 | Sayplan | QUT Center for Robotics | SayPlan: mise à la terre de grands modèles de langue en utilisant des graphiques de scène 3D pour la planification des tâches de robot évolutif | Corl '23 | github |
| 2023-7-12 | Voxposer | Stanford | Voxposer: cartes de valeur 3D composables pour la manipulation robotique avec des modèles de langage | Arxiv | github |
| 2022-12-13 | Rt-1 | RT-1: Transformateur robotique pour le contrôle du monde réel à grande échelle | Arxiv | github | |
| 2022-12-8 | LLM-Flanner | L'Ohio State University | LLM-Planner: Planification fondée sur quelques tirs pour les agents incarnés avec des modèles de langues importants | ICCV '23 | github |
| 2022-10-11 | Champs de clip | NYU, méta | Champs clip: champs sémantiques faiblement supervisés pour la mémoire robotique | RSS '23 | github |
| 2022-09-20 | Nlmap-saycan | Représentations de scènes interrogables à open vocabulaire pour la planification du monde réel | ICRA '23 | github |
| Date | mots clés | Institut | Papier | Publication | Autres |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | Bigai | Raisonnement situé à plusieurs modales dans des scènes 3D | Neirips '24 | projet |
| 2024-06-10 | 3D-Grand / 3D-Pope | Umich | 3D-Grand: un ensemble de données à un million de dollars pour 3D-LLM avec un meilleur sol et moins d'hallucination | Arxiv | projet |
| 2024-06-03 | Spatialrgpt-Bench | UCSD | Spatialrgpt: raisonnement spatial fondé dans les modèles de langage de vision | Neirips '24 | github |
| 2024-1-18 | Sceau | Bigai | Sceauserse: Échelle d'apprentissage en langue de vision 3D pour la compréhension de la scène ancrée | Arxiv | github |
| 2023-12-26 | Incarné | Shanghai Ai Lab | EmbodiedScan: une suite holistique de perception 3D multimodale envers l'IA incarnée | Arxiv | github |
| 2023-12-17 | M3dbench | Université Fudan | M3DBench: Instruisons les grands modèles avec des invites 3D multimodales | Arxiv | github |
| 2023-11-29 | - | Profondeur | Évaluation des VLM pour l'annotation multiprobe basée sur les scores d'objets 3D | Arxiv | github |
| 2023-09-14 | Cohérence croisée | Unibo | Regarder les mots et les points avec attention: une référence pour la cohérence du texte à la forme | ICCV '23 | github |
| 2022-10-14 | SQA3D | Bigai | SQA3D: Question située répondant dans les scènes 3D | ICLR '23 | github |
| 2021-12-20 | Scanqa | Riken AIP | ScanQA: Question 3D Répondre à la compréhension de la scène spatiale | CVPR '23 | github |
| 2020-12-3 | Scan2cap | Tumeau | Scan2Cap: sous-titrage dense au contexte dans les scans RVB-D | CVPR '21 | github |
| 2020-8-23 | Référence3d | Stanford | REFORIT3D: Écouteurs neuronaux pour l'identification d'objets 3D à grain fin dans les scènes du monde réel | ECCV '20 | github |
| 2019-12-18 | ScanRefer | Tumeau | ScanRefer: localisation d'objets 3D dans les scans RVB-D en utilisant le langage naturel | ECCV '20 | github |
Vos contributions sont toujours les bienvenues!
Je garderai des demandes de traction ouvertes si je ne sais pas si elles sont géniales pour les LLM 3D, vous pourriez voter pour eux en ajoutant? pour eux.
Si vous avez des questions sur cette liste d'opinion, veuillez nous contacter à [email protected] ou WECHAT ID: MXZ1997112.
Si vous trouvez ce référentiel utile, veuillez envisager de citer ce document:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}Ce repo est inspiré par Awesome-llm


