guidewire
1.0.0
Interprétation de Guidewire CDA comme Delta Table: En tant qu'entreprise technologique, Guidewire propose une plate-forme industrielle pour les compagnies d'assurance de propriété et de blessures dans le monde. Grâce à différents produits et services dans le cadre de leur suite d'assurance, ils fournissent aux utilisateurs les capacités de fonctionnement requises pour acquérir, traiter et régler les réclamations, maintient des politiques, le soutien des processus de souscription et d'ajustement. Databricks, en revanche, fournit aux utilisateurs des capacités analytiques (des rapports de base aux solutions ML complexes) via leur lac Lake pour l'assurance. En combinant les deux plates-formes ensemble, les compagnies d'assurance P&C ont désormais la possibilité de commencer à intégrer les capacités d'analyse avancées (IA / ML) dans leurs principaux processus métier, enrichissant les informations clients avec des données alternatives (par exemple, les données météorologiques), mais la réconciliation et la déclaration des informations critiques chez Enterprise échelle.
Guidewire prend en charge l'accès aux données à l'environnement analytique via leur offre de données cloud (CDA). Le stockage de fichiers en tant que fichiers de parquet individuels sous différents horodatages et évolution de schéma rend malheureusement difficile le traitement pour les utilisateurs finaux. Au lieu de traiter les fichiers individuellement, pourquoi ne générerions-nous pas les fichiers delta log pour lire uniquement les informations dont nous avons besoin, lorsque nous en avons besoin, sans avoir à télécharger, traiter et concilier des informations complexes? C'est le principe de cette initiative. La table Delta générée ne se matérialisera pas (les données ne seront pas physiquement déplacées) mais agiront comme un clone peu profond pour guider les données de filon.
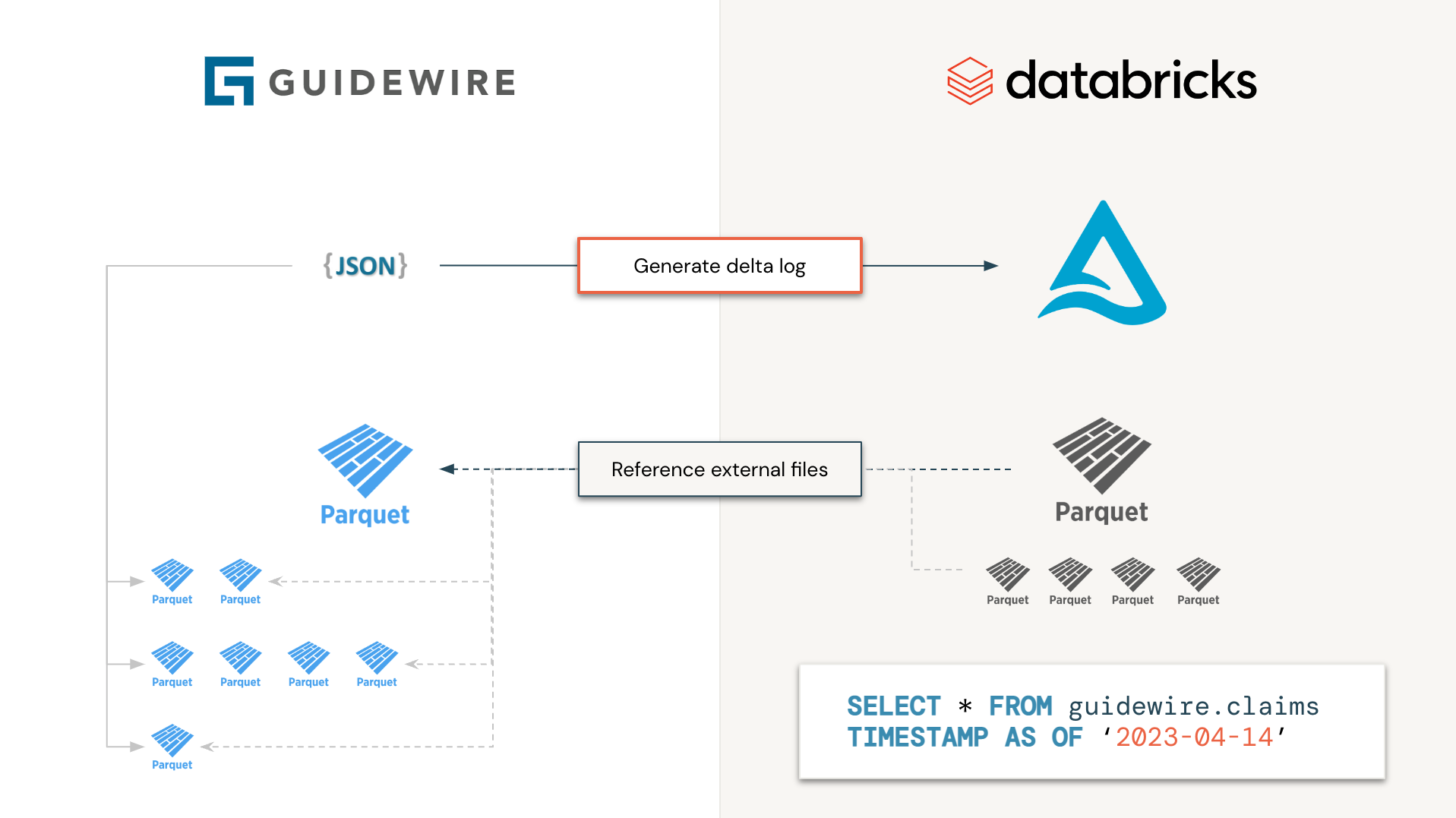
Plus précisément, nous traiterons toutes les tables de guidage de guide indépendamment, en parallèle (c'est-à-dire en tant que travail d'étincelles), où chaque tâche consistera uniquement à répertorier les fichiers et dossiers de parquet et la génération de Delta Conned en conséquence. Du point de vue de l'utilisateur final, Guidewire ressemblera à une table delta et sera traité en tant que tel, réduisant le temps de traitement de jours à secondes (car nous n'avons pas à télécharger et à traiter chaque fichier via de nombreux travaux d'étincelle).

Comme les données se trouvent maintenant sur le lac Delta (matérialisé physiquement ou non), on peut bénéficier de toutes les capacités en aval du lac Delta, "s'abonner" à des modifications via des capacités de chargeur automatique, du Delta Live Table (DLT) ou même du partage de Delta, de l'accélération Il est temps de savoir des jours à quelques minutes.
Comme ce modèle suit une approche de clone peu profond, il est recommandé d'accorder la permission de lecture de lecture uniquement pour l'utilisateur, car une opération VACCUM sur le Delta généré entraînerait éventuellement une perte de données sur le seau Guidewire S3. Nous recommandons fortement à l'organisation de ne pas exposer cet ensemble de données bruts aux utilisateurs finaux, mais plutôt de créer une version argentée avec des données matérialisées pour la consommation. Notez qu'une commande OPTIMIZE entraînera la matérialisation du dernier instantané delta avec des fichiers parquet optimisés. Seuls les fichiers pertinents seront téléchargés physiquement de S3 d'origine vers la table de destination.
import com . databricks . labs . guidewire . Guidewire
val manifestUri = " s3://bucket/key/manifest.json "
val databasePath = " /path/to/delta/database "
Guidewire .index(manifestUri, databasePath) Cette commande s'exécutera sur un incrément de données par défaut, chargeant nos points de contrôle précédents stockés en tant que table delta sous ${databasePath}/_checkpoints . Si vous devez réindexer l'ensemble des données Guidewire, veuillez fournir un paramètre savemode facultatif comme suit
import org . apache . spark . sql . SaveMode
Guidewire .index(manifestUri, databasePath, saveMode = SaveMode . Overwrite )À la suite d'un modèle de «clone peu profond», les fichiers de fil de guidage ne seront pas stockés mais référencés à partir d'un emplacement delta qui peut être défini comme une table externe.
CREATE DATABASE IF NOT EXISTS guidewire;
CREATE EXTERNAL TABLE IF NOT EXISTS guidewire . policy_holders LOCATION ' /path/to/delta/database/policy_holders ' ;Enfin, nous pouvons interroger les données Guidewire et accéder à toutes ses différentes versions à différents horodatages.
SELECT * FROM guidewire . policy_holders
VERSION AS OF 2 mvn clean package -Pshaded En suivant la norme Maven, ajoutez un profil shaded pour générer un fichier JAR autonome avec toutes les dépendances incluses. Ce pot peut être installé sur un environnement de données en conséquence.


