LLaMA Omni
1.0.0
Auteurs: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaolei Zhang, Yang Feng *
Llama-OMNI est un modèle en langage vocal construit sur LLAMA-3.1-8B-INSTRUCT. Il prend en charge les interactions de parole de faible latence et de haute qualité, générant simultanément des réponses en texte et parole basées sur les instructions de la parole.
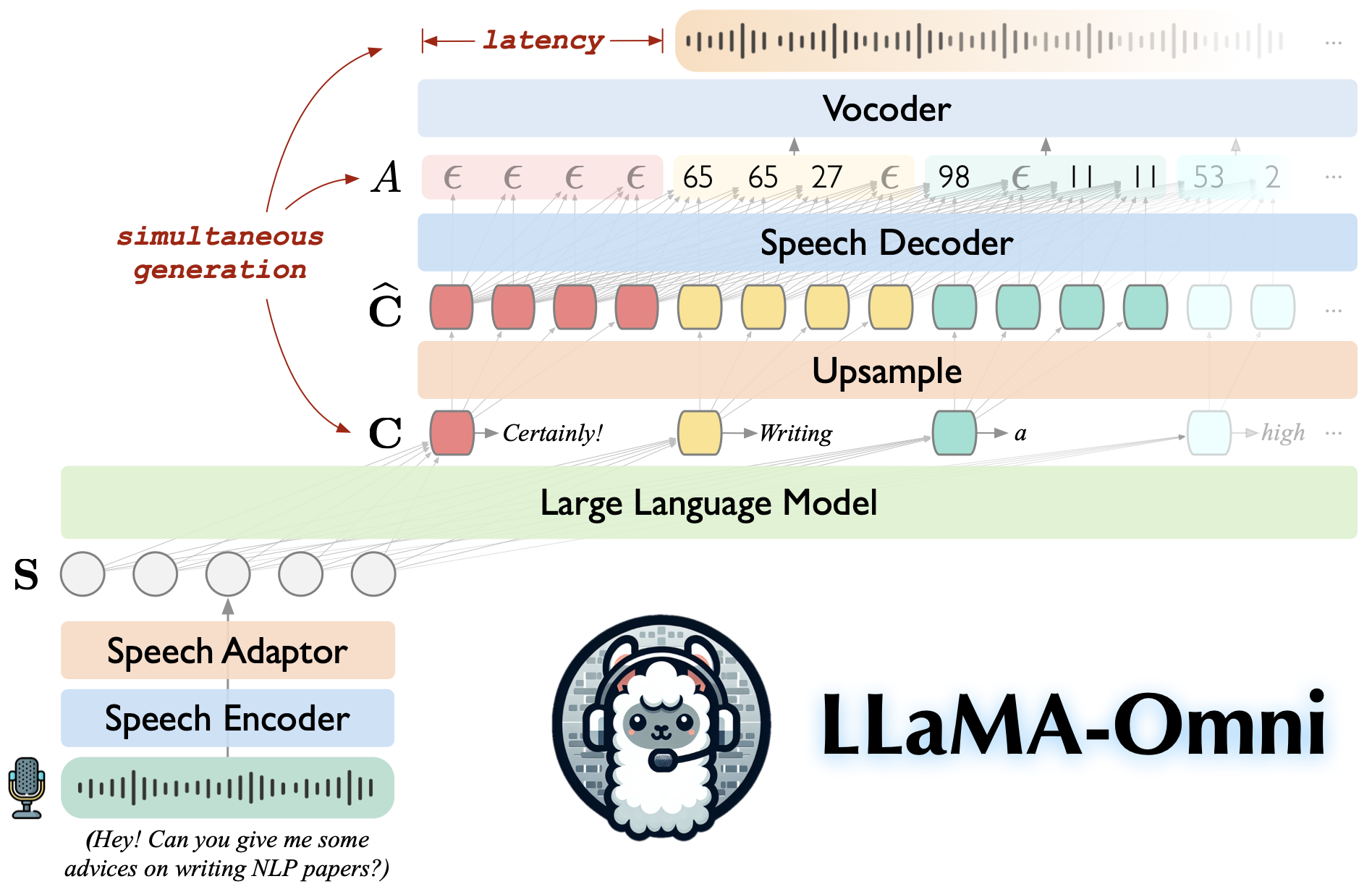
Construit sur LLAMA-3.1-8B-INSTRUCT, garantissant des réponses de haute qualité.
Interaction de la parole à faible latence avec une latence aussi faible que 226 ms.
Génération simultanée à la fois de réponses en texte et parole.
♻️ Formé en moins de 3 jours en utilisant seulement 4 GPU.
Cloner ce référentiel.
git clone https://github.com/icTnlp/Lama-omnicd llama-omni
Installer des packages.
conda crée -n llama-omni python = 3,10 conda activer lama-omni pip install pip == 24.0 pip install -e.
Installez fairseq .
git clone https://github.com/pytorch/fairseqcd Fairseq pip install -e. - NO-BUILD-ISOLATION
Installez flash-attention .
PIP Installer Flash-Attn - No-Build-Isolation
Téléchargez le modèle Llama-3.1-8B-Omni depuis? Huggingface.
Téléchargez le modèle Whisper-large-v3 .
chuchotement d'importation
modèle = whisper.load_model ("grand-v3", téléchargement_root = "modèles / speech_encoder /")Téléchargez le Vocoder Hifi-Gan basé sur l'unité.
wget https://dl.fbaipublicfiles.com/fairseq/spech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -p voccoder / wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -p Vpiderer /
Lancez un contrôleur.
Python -m omni_speech.serve.Controller - Host 0.0.0.0 --port 10000
Lancez un serveur Web Gradio.
python -m omni_speech.serve.gradio_web_server --Controller http: // localhost: 10000 --port 8000 --model-list-mode reload --vocoder vocoder / g_00500000 --vocoder-cfg vocoder / config.json
Lancez un travailleur modèle.
Python -M omni_speech.serve.Model_Worker - Host 0.0.0.0 - Controller http: // localhost: 10000 --port 40000 --worker http: // localhost: 40000 --model-path llama-3.1-8b-omni --model-name lama-3.1-8b-omni --s2s
Visitez http: // localhost: 8000 / et interagissez avec Llama-3.1-8b-Omni!
Remarque: En raison de l'instabilité de la lecture audio en streaming dans Gradio, nous n'avons implémenté que la synthèse audio en streaming sans activer la place automatique. Si vous avez une bonne solution, n'hésitez pas à soumettre un PR. Merci!
Pour exécuter l'inférence localement, veuillez organiser les fichiers d'instructions de la parole en fonction du format dans le répertoire omni_speech/infer/examples , puis reportez-vous au script suivant.
bash omni_speech / inférieur / run.sh omni_speech / inférieur / exemples
Notre code est publié sous la licence Apache-2.0. Notre modèle est destiné à des fins de recherche académique uniquement et ne peut pas être utilisé à des fins commerciales.
Vous êtes libre d'utiliser, de modifier et de distribuer ce modèle dans des contextes académiques, à condition que les conditions suivantes soient remplies:
Utilisation non commerciale : le modèle ne peut être utilisé à des fins commerciales.
Citation : Si vous utilisez ce modèle dans votre recherche, veuillez citer l'œuvre originale.
Pour toute demande d'utilisation commerciale ou pour obtenir une licence commerciale, veuillez contacter [email protected] .
Llava: la base de code sur laquelle nous avons construit.
SLAM-LLM: Nous empruntons un code sur le codeur de la parole et l'adaptateur de la parole.
Si vous avez des questions, n'hésitez pas à soumettre un problème ou à contacter [email protected] .
Si notre travail vous est utile, veuillez citer comme:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

