streaming
v0.9.1
Nous avons construit StreamingDataset pour faire une formation sur de grands ensembles de données à partir de stockage cloud aussi rapide, bon marché et évolutif que possible.
Il est spécialement conçu pour une formation distribuée multi-nœuds pour les grands modèles - la réactivité des garanties, les performances et la facilité d'utilisation. Maintenant, vous pouvez vous entraîner efficacement n'importe où, indépendamment de votre emplacement de données de formation. Il suffit de diffuser les données dont vous avez besoin, lorsque vous en avez besoin. Pour en savoir plus sur les raisons pour lesquelles nous avons construit StreamingDataset, lisez notre blog d'annonce.
StreamingDataset est compatible avec tout type de données, y compris les images, le texte, la vidéo et les données multimodales .
Avec la prise en charge des principaux fournisseurs de stockage cloud (AWS, OCI, GCS, Azure, Databricks et tout magasin d'objets compatibles S3 tels que CloudFlare R2, Coreweave, Backblaze B2, etc.) et conçu en remplacement de la classe d'accueil Pytorch IterabledataSet , StreamingDataset s'intègre parfaitement à vos flux de travail de formation existants.

Le streaming peut être installé avec pip :
pip install mosaicml-streaming
Convertissez votre ensemble de données bruts en l'un de nos formats de streaming pris en charge:
Format MDS (Mosaic Data Shard) qui peut coder et décoder n'importe quel objet Python
CSV / TSV
Jsonl
Importer Numpy en tant que NPFROM PIL Import ImageFrom Streaming Importer mdswriter # répertoire local ou distant dans lequel stocker les fichiers de sortie compressésData_dir = 'path-to-dataset' # un dictionnaire mappant des champs d'entrée à leurs données TypeSColumns = {'image': 'jPeg' , 'class': 'int'} # compression des rayons, si anycompression = 'zstd' # Enregistrez les échantillons sous forme de fragments à l'aide de mdswriterwith mdswriter (out = data_dir, colonnes = colonnes, compression = compression) comme out: pour i dans la plage (10000 ): Sample = {'image': image.fromArray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'class': np.random.randint (10),
} out.write (échantillon)Téléchargez votre ensemble de données de streaming sur le stockage cloud de votre choix (AWS, OCI ou GCP). Vous trouverez ci-dessous un exemple de téléchargement d'un répertoire sur un seau S3 à l'aide du CLI AWS.
$ AWS S3 CP - Recursif Path-to-Dataset S3: // My-Bucket / Path-to-Dataset
De Torch.utils.data Import DataloAderFrom Streaming Import StreamingDataset # chemin distant où l'ensemble de données complet est constamment stockée / path-to-dataset '# Créer un streaming dataSetDataset = streamingDataset (local = local, éloigné = télécommande, shuffle = true) # voyons ce qui est dans son exemple # 1337 ... sampe = jeu de données [1337] img = exemple [' image '] CLS = Sample [' Class '] # Créer Pytorch DatalOaderDatalOader = DatalOader (ensemble de données)
Les guides de démarrage, les exemples, les références API et d'autres informations utiles peuvent être trouvés dans nos documents.
Nous avons des tutoriels de bout en bout pour la formation d'un modèle sur:
Cifar-10
Facesynthétique
Synthéticnlp
Nous avons également du code de démarrage pour les ensembles de données populaires suivants, qui peuvent être trouvés dans le répertoire streaming :
| Ensemble de données | Tâche | Lire | Écrire |
|---|---|---|---|
| Laion-400m | Texte et image | Lire | Écrire |
| Webvid | Texte et vidéo | Lire | Écrire |
| C4 | Texte | Lire | Écrire |
| Enwiki | Texte | Lire | Écrire |
| Pile | Texte | Lire | Écrire |
| ADE20K | Segmentation d'image | Lire | Écrire |
| Cifar10 | Classification d'image | Lire | Écrire |
| Coco | Classification d'image | Lire | Écrire |
| Imagenet | Classification d'image | Lire | Écrire |
Pour commencer la formation sur ces ensembles de données:
Convertir les données brutes en format .mds à l'aide du script correspondant du répertoire convert .
Par exemple:
$ python -m streaming.multimodal.convert.webvid - in <CSV Fichier> --out <MDS Directory de sortie>
Importez une classe d'ensemble de données pour commencer à former le modèle.
De streaming.Multimodal Import StreamingInSideWebvidDataset = streamingInsideWebvid (local = local, télécommande = télécommande, shuffle = true)
Expérimentez facilement avec des mélanges de données avec Stream . L'échantillonnage de l'ensemble de données peut être contrôlé en termes relatifs (proportion) ou absolus (répéter ou échantillons). Pendant le streaming, les différents ensembles de données sont diffusés, mélangés et mélangés parfaitement juste à temps.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
Une caractéristique unique de notre solution: les échantillons sont dans le même ordre, quel que soit le nombre de GPU, de nœuds ou de travailleurs CPU. Cela rend plus facile à:
Reproduire et déboguer les courses et les pics de perte
Chargez un point de contrôle formé sur 64 GPU et déboguez sur 8 GPU avec reproductibilité
Voir la figure ci-dessous - Formation d'un modèle sur 1, 8, 16, 32 ou 64 GPUS donne exactement la même courbe de perte (jusqu'à les limites des mathématiques à point flottante!)
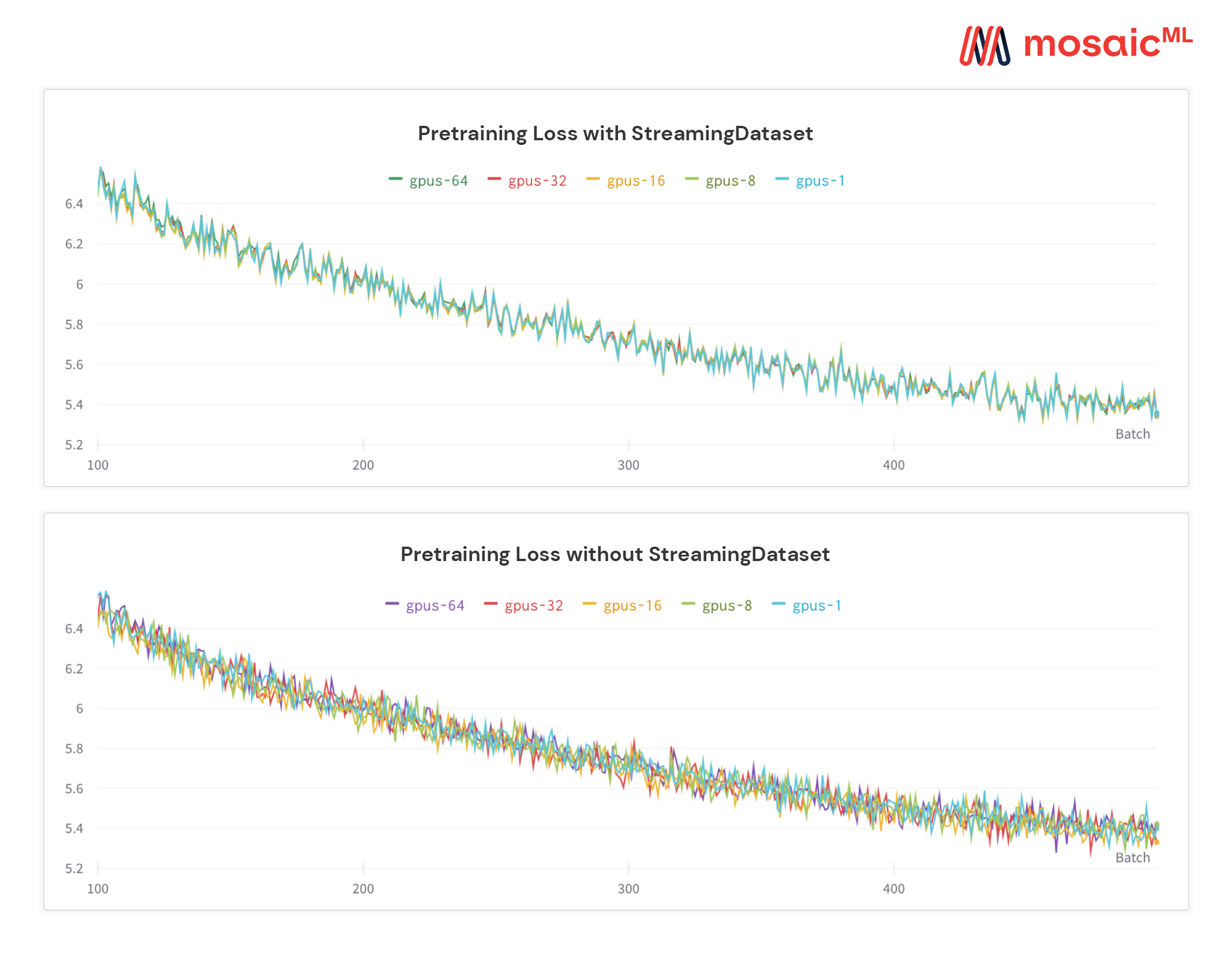
Il peut être coûteux - et ennuyeux - d'attendre que votre travail reprenne pendant que votre obstacle de données tourne après une défaillance matérielle ou une pic de perte. Grâce à notre ordre déterministe des échantillons, StreamingDataset vous permet de reprendre une formation en secondes, pas des heures, au milieu d'une longue course d'entraînement.
La minimisation de la latence de reprise peut économiser des milliers de dollars de frais de sortie et de temps de calcul du GPU inactif par rapport aux solutions existantes.
Notre format MDS réduit les travaux étrangers de l'os, ce qui entraîne une latence d'échantillons ultra-low et un débit plus élevé par rapport aux alternatives pour les charges de travail goulottes d'étranglement par le dataloader.
| Outil | Déborder |
|---|---|
| StreamingDataset | ~ 19000 IMG / SEC |
| Image | ~ 18000 IMG / SEC |
| Webdataset | ~ 16000 IMG / SEC |
Les résultats indiqués proviennent de la formation ImageNet + RESNET-50, collectés sur 5 répétitions après la mise en cache des données après la première époque.
La convergence du modèle de l'utilisation de StreamingDataset est tout aussi bonne que l'utilisation du disque local, grâce à notre algorithme de mélange.
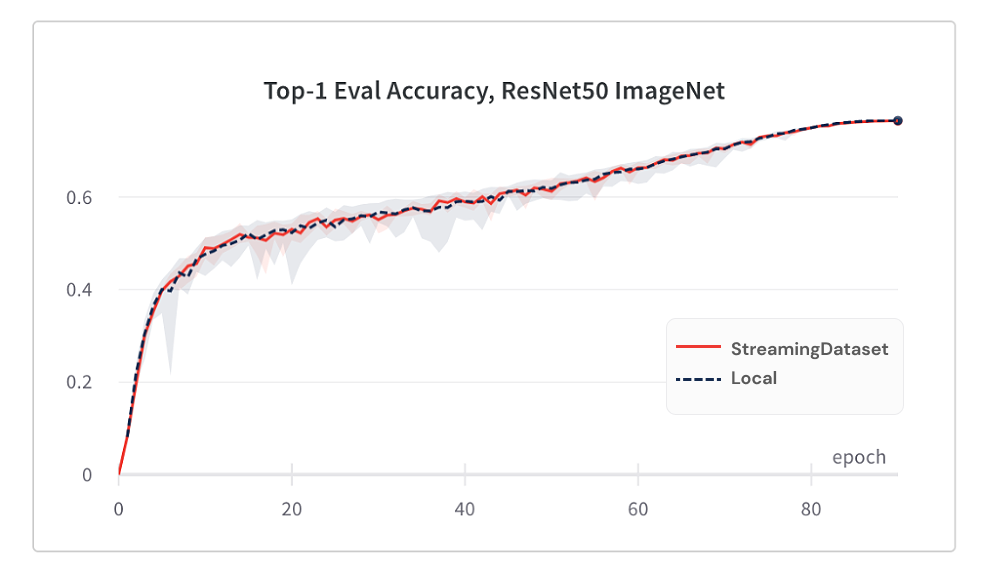
Vous trouverez ci-dessous les résultats de la formation ImageNet + RESNET-50, collectés sur 5 répétitions.
| Outil | Précision top-1 |
|---|---|
| StreamingDataset | 76,51% +/- 0,09 |
| Image | 76,57% +/- 0,10 |
| Webdataset | 76,23% +/- 0,17 |
StreamingDataSet mélange tous les échantillons attribués à un nœud, tandis que des solutions alternatives mélangent uniquement des échantillons dans un pool plus petit (dans un seul processus). Le mélange sur une piscine plus large répandait davantage les échantillons adjacents. De plus, notre algorithme de mélange minimise les échantillons abandonnés. Nous avons trouvé ces deux caractéristiques de mélange avantageuses pour la convergence du modèle.
Accédez aux données dont vous avez besoin lorsque vous en avez besoin.
Même si un échantillon n'est pas encore téléchargé, vous pouvez accéder à dataset[i] pour obtenir un exemple i . Le téléchargement débutera immédiatement et le résultat sera renvoyé lorsqu'il sera fait - similaire à un ensemble de données Pytorch de style carte avec des échantillons numérotés séquentiellement et accessibles dans n'importe quel ordre.
DataSet = streamingDataset (...) Sample = ensemble de données [19543]
StreamingDataset irara avec plaisir sur un certain nombre d'échantillons. Vous n'avez pas à supprimer à jamais des échantillons afin que l'ensemble de données soit divisible sur un nombre de périphériques au four. Au lieu de cela, chaque époque une sélection différente d'échantillons est répétée (aucune n'a été abandonnée) de sorte que chaque périphérique traite le même nombre.
DataSet = streamingDataset (...) dl = dataloader (ensemble de données, num_workers = ...)
Supprimer dynamiquement les fragments les moins récemment utilisés afin de maintenir l'utilisation du disque sous une limite spécifiée. Ceci est activé en définissant l'argument StreamingDataset cache_limit . Voir le guide de mélange pour plus de détails.
dataset = StreamingDataset( cache_limit='100gb', ... )
Voici quelques projets et expériences qui ont utilisé StreamingDataset. Vous avez quelque chose à ajouter? Envoyez un courriel à [email protected] ou rejoignez notre délai de communauté.
BioMedlm: un modèle de grande langue spécifique au domaine pour la biomédecine par Mosaicml et Stanford CRFM
Modèles de diffusion en mosaïque: formation stable de diffusion à partir des coûts de zéro <160k $
MOSAIC LLMS: qualité GPT-3 pour <500k $
Mosaic Resnet: formation de vision informatique rapide et flamboyante avec le Mosaic Resnet and Composer
Mosaic DeepLabv3: 5x Formation de segmentation d'image plus rapide avec des recettes MOSAICML
… Plus à venir! Restez à l'écoute!
Nous accueillons toutes les contributions, les demandes de traction ou les problèmes.
Pour commencer à contribuer, consultez notre page contributive.
PS: Nous embauchons!
Si vous aimez ce projet, donnez-nous une star et consultez nos autres projets:
Compositeur - Une bibliothèque Pytorch moderne qui facilite la formation de réseau neuronal évolutif et efficace
Exemples MOSAICML - Exemples de référence pour la formation des modèles ML rapidement et à haute précision - avec un code de démarrage pour les modèles GPT / Large Language, une diffusion stable, Bert, Resnet-50 et DeepLabv3
MOSAICML Cloud - Notre plateforme de formation construite pour minimiser les coûts de formation pour les LLM, les modèles de diffusion et autres grands modèles - avec une orchestration multi-cloud, une mise à l'échelle multi-nœuds sans effort et des optimisations sous le capuchon pour accélérer le temps de formation
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

