Gemini_API_Entity_Extraction
1.0.0
Dans ce cahier, en utilisant l'API Gemini (Gemini 1.5 Flash), je vais extraire certaines informations du texte de description de travail que j'ai gratté et collecté sur le site de recherche d'emploi dans le passé
Dans mon projet passé, j'ai gratté et collecté des postes d'ingénieurs logiciels annoncés sur un site de recherche d'emploi, pour plus de détails, veuillez visiter - https://github.com/morikaglobal/jobsite_selenium
À l'aide de mon code de grattage, les données sont grattées, le traitement des données nécessaire effectué et les données sont stockées dans le fichier CSV comme ceci: Résultat de la recherche de chantier (fichier CSV)
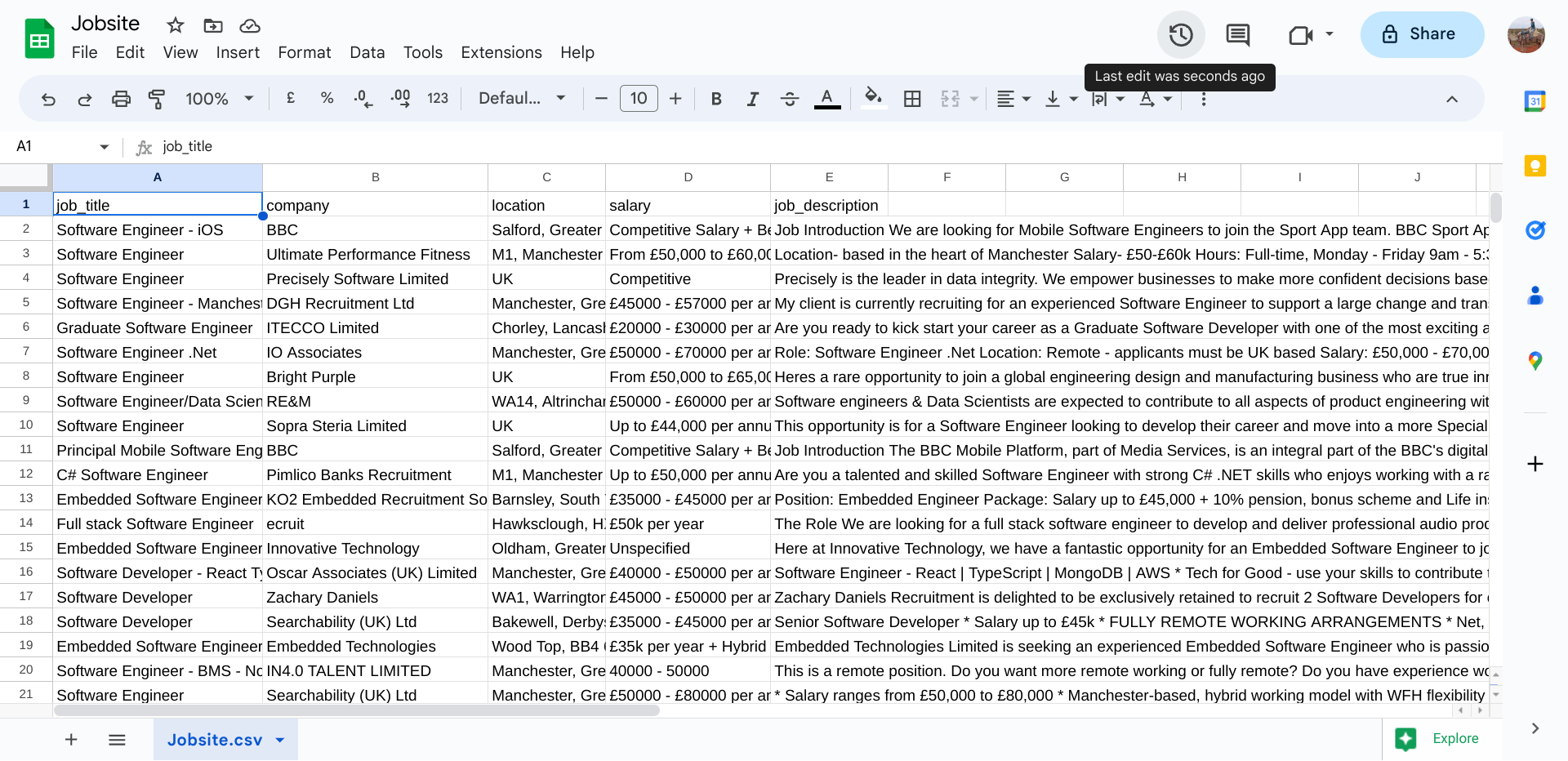
Cependant, j'ai remarqué que certains postes semblent ne pas être liés aux postes d'ingénieur logiciel, bien que les titres d'emploi incluent la phrase «ingénieur logiciel» et les langages de programmation spécifiques et les compétences requis pour chaque emploi ne peuvent être trouvés que lorsque les descriptions de l'emploi sont lus manuellement.
À l'aide de Gemini 1.5 Flash, je tiens à identifier si la position est liée à l'ingénieur logiciel ou non, de sorte que sinon, je peux supprimer les positions de la liste / dataframe. En même temps, je veux utiliser l'extraction d'entité de l'API Gemini afin que je puisse extraire certaines informations - la position réelle que les employeurs recherchent des candidats, ainsi que l'expérience et les compétences requises
J'importerai et utiliserai les données collectées à partir du projet ci-dessus disponible sur - https://github.com/morikaglobal/jobsite_selenium/blob/master/jobsite.csv


