ainovelprompter
1.0.0
L'IA Nouveau Prompter peut générer des invites d'écriture pour des romans en fonction des caractéristiques spécifiées par l'utilisateur.
Le roman de l'IA est une application de bureau conçue pour aider les écrivains à créer des invites cohérentes et bien structurées pour des assistants d'écriture d'IA comme Chatgpt et Claude. L'outil aide à gérer les éléments de l'histoire, les détails des personnages et génère des invites correctement formatées pour poursuivre votre roman.
L'exécutable est sur l'exécutable Build / Bin
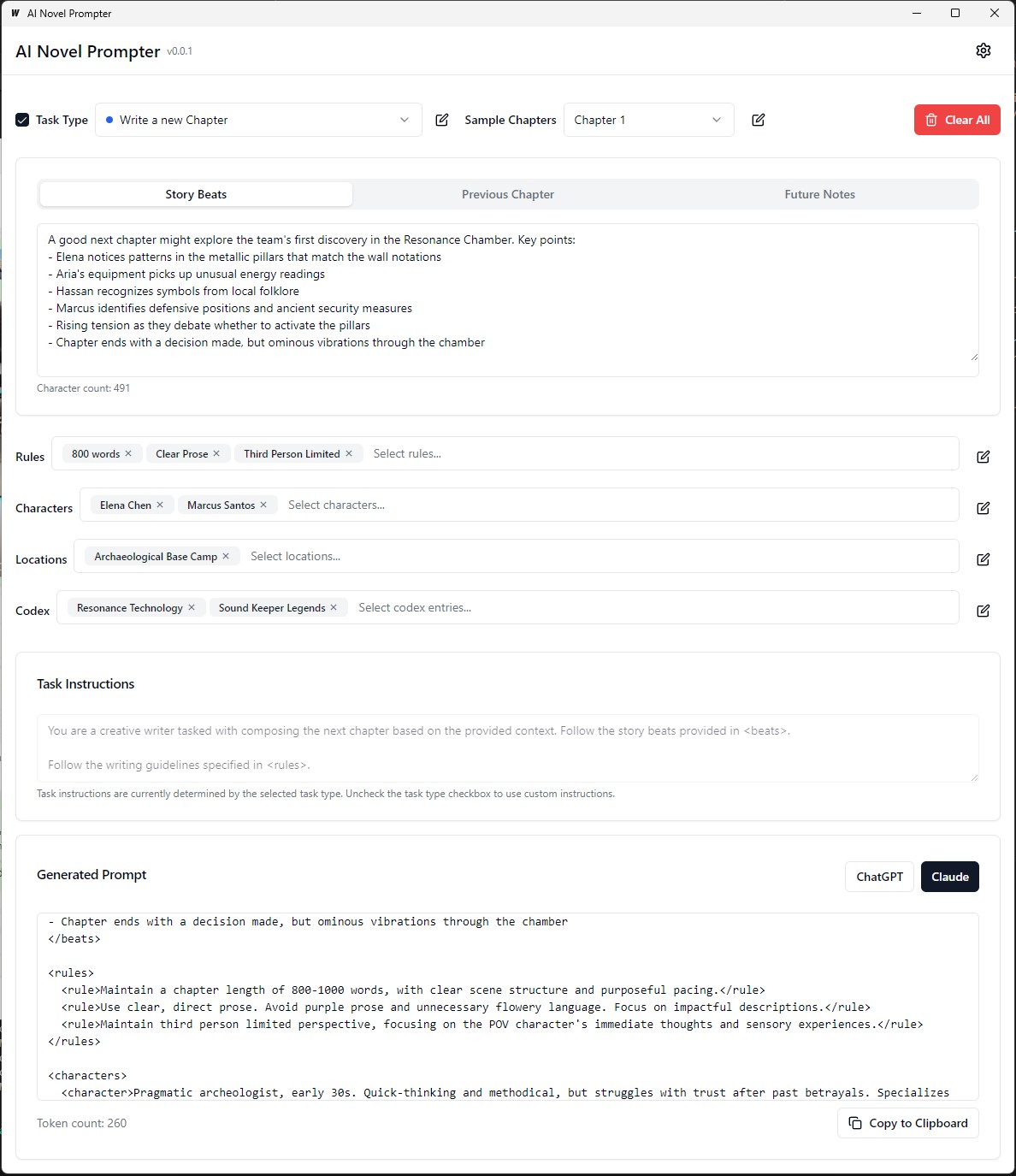
Chaque catégorie peut être modifiée, enregistrée et réutilisée sur différentes invites:
L'extrémité avant :
Backend :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev Pour construire un package de mode de production redistribuable, utilisez wails build .
wails buildL'exécutable est sur l'exécutable Build / Bin
Ou générez-le avec:
wails build -nsisCela peut être fait pour Mac et voir la dernière partie de ce guide
L'application construite sera disponible dans le répertoire build .
Configuration initiale :
Création d'une invite :
Génération de sortie :
Avant d'exécuter l'application, assurez-vous que vous avez installé les suivants:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Accédez au répertoire server :
cd server
Installez les dépendances GO:
go mod download
Mettez à jour le fichier config.yaml avec votre configuration de base de données.
Exécutez les migrations de la base de données:
go run cmd/main.go migrate
Démarrez le serveur backend:
go run cmd/main.go
Accédez au répertoire client :
cd ../client
Installez les dépendances du frontend:
npm install
Démarrez le serveur de développement Frontend:
npm start
http://localhost:3000 pour accéder à l'application. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Mettez à jour le fichier docker-compose.yml avec votre configuration de base de données.
Démarrez l'application à l'aide de Docker Compose:
docker-compose up -d
http://localhost:3000 pour accéder à l'application. server/config.yaml .client/src/config.ts . Pour construire le frontend pour la production, exécutez la commande suivante dans le répertoire client :
npm run build
Les fichiers prêts pour la production seront générés dans le répertoire client/build .
Ce petit guide fournit des instructions sur la façon d'installer PostgreSQL sur le sous-système Windows pour Linux (WSL), ainsi que des étapes pour gérer les autorisations des utilisateurs et résoudre les problèmes communs.
Terminal WSL ouvert : lancez votre distribution WSL (Ubuntu recommandé).
Mettre à jour les packages :
sudo apt updateInstallez PostgreSQL :
sudo apt install postgresql postgresql-contribVérifiez l'installation :
psql --versionDéfinir le mot de passe utilisateur PostgreSQL :
sudo passwd postgresCréer une base de données :
createdb mydbBase de données d'accès :
psql mydbImporter des tables à partir du fichier SQL :
psql -U postgres -q mydb < /path/to/file.sqlListe des bases de données et des tables :
l # List databases
dt # List tables in the current databaseBase de données de commutation :
c dbnameCréer un nouvel utilisateur :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;Privilèges de concession :
ALTER USER your_db_user CREATEDB;Le rôle n'existe pas d'erreur : passer à l'utilisateur «Postgres»:
sudo -i -u postgres
createdb your_db_nameAutorisation refusée de créer une extension : Connexion comme «Postgres» et exécuter:
CREATE EXTENSION IF NOT EXISTS pg_trgm; Erreur de l'utilisateur inconnu : assurez-vous que vous utilisez un utilisateur système reconnu ou référez-vous correctement à un utilisateur PostgreSQL dans l'environnement SQL, et non via sudo .
Pour générer des données de formation personnalisées pour affiner un modèle de langue pour imiter le style d'écriture de George Macdonald, le processus commence par obtenir le texte intégral de l'un de ses romans, "La princesse et le gobelin", du projet Gutenberg. Le texte est ensuite décomposé en battements d'histoire individuels ou moments clés en utilisant une invite qui demande à l'IA de générer un objet JSON pour chaque battement, capturant l'auteur, le ton émotionnel, le type d'écriture et l'extrait de texte réel.
Ensuite, GPT-4 est utilisé pour réécrire chacun de ces battements d'histoire dans ses propres mots, générant un ensemble parallèle de données JSON avec des identificateurs uniques reliant chaque battement réécrit à son homologue d'origine. Pour simplifier les données et les rendre plus utiles pour la formation, la grande variété de tons émotionnels est cartographiée à un ensemble plus petit de tons de base à l'aide d'une fonction Python. Les deux fichiers JSON (battements originaux et réécrits) sont ensuite utilisés pour générer des invites de formation, où le modèle est invité à reformuler le texte généré GPT-4 dans le style de l'auteur d'origine. Enfin, ces invites et leurs sorties cibles sont formatées en fichiers JSONL et JSON, prêts à être utilisés pour affiner le modèle de langue pour capturer le style d'écriture distinctif de MacDonald.
Dans l'exemple précédent, le processus de génération de texte paraphrasé à l'aide d'un modèle de langue impliquait des tâches manuelles. L'utilisateur a dû fournir manuellement le texte d'entrée, exécuter le script, puis examiner la sortie générée pour garantir sa qualité. Si la sortie ne répondait pas aux critères souhaités, l'utilisateur devrait réessayer manuellement le processus de génération avec différents paramètres ou effectuer des ajustements au texte d'entrée.
Cependant, avec la version mise à jour de la fonction process_text_file , l'ensemble du processus a été entièrement automatisé. La fonction s'occupe de lire le fichier texte d'entrée, de le diviser en paragraphes et d'envoyer automatiquement chaque paragraphe au modèle de langue pour paraphraser. Il intègre divers contrôles et mécanismes de réessayer pour gérer les cas où la sortie générée ne répond pas aux critères spécifiés, tels que contenant des phrases indésirables, étant trop courts ou trop longs, ou comprenant plusieurs paragraphes.
Le processus d'automatisation comprend plusieurs caractéristiques clés:
Resum à partir du dernier paragraphe traité: si le script est interrompu ou doit être exécuté plusieurs fois, il vérifie automatiquement le fichier de sortie et reprend le traitement à partir du dernier paragraphe paraphrasé avec succès. Cela garantit que les progrès ne sont pas perdus et que le script peut reprendre là où il s'était arrêté.
Retry Mécanisme avec des semences et une température aléatoires: si une paraphrase générée ne répond pas aux critères spécifiés, le script rétracte automatiquement le processus de génération jusqu'à un nombre spécifié de fois. À chaque réessayer, il modifie au hasard les valeurs de graines et de température pour introduire une variation des réponses générées, augmentant les chances d'obtenir une sortie satisfaisante.
Économie de progrès: le script enregistre les progrès vers le fichier de sortie chaque nombre spécifié de paragraphes (par exemple, tous les 500 paragraphes). Cela garantit une perte de données en cas d'interruptions ou d'erreurs pendant le traitement d'un grand fichier texte.
Journalisation détaillée et résumé: Le script fournit des informations de journalisation détaillées, y compris le paragraphe d'entrée, la sortie générée, les tentatives de réessayer et les raisons de l'échec. Il génère également un résumé à la fin, affichant le nombre total de paragraphes, les paragraphes paraphrasés avec succès, les paragraphes sautés et le nombre total de tentatives.
Pour générer des données de formation personnalisées ORPO pour affiner un modèle de langue pour imiter le style d'écriture de George MacDonald.
Les données d'entrée doivent être au format JSONL, chaque ligne contenant un objet JSON qui inclut la réponse invite et choisie. (À partir du réglage fin précédent) Pour utiliser le script, vous devez configurer le client OpenAI avec votre touche API et spécifier les chemins de fichier d'entrée et de sortie. L'exécution du script traitera le fichier JSONL et générera un fichier CSV avec des colonnes pour l'invite, la réponse choisie et une réponse rejetée générée. Le script économise des progrès toutes les 100 lignes et peut reprendre de l'endroit où il s'était arrêté s'il est interrompu. Une fois terminé, il fournit un résumé des lignes totales traitées, des lignes écrites, des lignes sautées et des détails de réessayer.
La qualité de l'ensemble de données est question: 95% des résultats dépendent de la qualité de l'ensemble de données. Un ensemble de données propre est essentiel car même un peu de mauvaises données peuvent nuire au modèle.
Revue des données manuelles: le nettoyage et l'évaluation de l'ensemble de données peuvent considérablement améliorer le modèle. Il s'agit d'une étape longue mais nécessaire car aucun ajustement des paramètres ne peut corriger un ensemble de données défectueux.
Les paramètres de formation ne doivent pas s'améliorer mais empêcher la dégradation du modèle. Dans les ensembles de données robustes, l'objectif devrait être d'éviter les répercussions négatives tout en dirigeant le modèle. Il n'y a pas de taux d'apprentissage optimal.
Échelle du modèle et limitations matérielles: les modèles plus grands (paramètres 33b) peuvent permettre une meilleure affinage, mais nécessitent au moins 48 Go de VRAM, ce qui les rend impraticables pour la majorité des configurations de maisons.
Accumulation de gradient et taille des lots: l'accumulation de gradient permet de réduire le sur-ajustement en améliorant la généralisation entre différents ensembles de données, mais il peut être plus faible après quelques lots.
La taille de l'ensemble de données est plus importante pour affiner un modèle de base qu'un modèle bien réglé. La surcharge d'un modèle bien réglé avec des données excessives pourrait dégrader son réglage fin précédent.
Un calendrier de taux d'apprentissage idéal commence par une phase d'échauffement, est stable pour une époque, puis diminue progressivement en utilisant un calendrier de cosinus.
Rang et généralisation du modèle: la quantité de paramètres formables affecte les détails et la généralisation du modèle. Les modèles de rang inférieur se généralisent mieux mais perdent les détails.
L'applicabilité de Lora: le réglage fin et économe en paramètres (PEFT) est applicable aux modèles de grande langue (LLM) et aux systèmes comme la diffusion stable (SD), démontrant sa polyvalence.
La communauté peu insuffisante a contribué à résoudre plusieurs problèmes avec Finetuning Llama3. Voici quelques points clés à garder à l'esprit:
Tokens BOS double : les jetons BOS doubles pendant les finetuning peuvent casser les choses. Unsil résout automatiquement ce problème.
Conversion GGUF : La conversion GGUF est brisée. Faites attention au double BOS et utilisez le CPU au lieu du GPU pour la conversion. UNSLOTH a des conversions GGUF automatiques intégrées.
Poids de base de buggy : certains des poids de base de Llama 3 (non instruites) sont "buggy" (non formé): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . Cela peut provoquer des résultats NANS et Buggy. Unsloth corrige automatiquement cela.
Invite du système : Selon la communauté peu inscrite, l'ajout d'une invite de système rend bien mieux la version instruct (et peut-être la version de base).
Problèmes de quantification : les problèmes de quantification sont courants. Voir cette comparaison qui montre que vous pouvez obtenir de bonnes performances avec LLAMA3, mais l'utilisation de la mauvaise quantification peut nuire aux performances. Pour la fin du Finetuning, utilisez BitsandBytes NF4 pour augmenter la précision. Pour GGUF, utilisez les versions I autant que possible.
Modèles de contexte long : les modèles de contexte longs sont mal formés. Ils étendent simplement la corde thêta, parfois sans aucune formation, puis s'entraînent sur un ensemble de données concaténé étrange pour en faire un long jeu de données. Cette approche ne fonctionne pas bien. Une mise à l'échelle du contexte long et continu aurait été bien meilleure si la mise à l'échelle de 8k à 1 m de longueur de contexte.
Pour résoudre certains de ces problèmes, utilisez des insuffisants pour Finetuning Llama3.
Lors de la fin de la paraphrase d'un modèle linguistique dans le style d'un auteur, il est important d'évaluer la qualité et l'efficacité des paraphrases générées.
Les mesures d'évaluation suivantes peuvent être utilisées pour évaluer les performances du modèle:
BLEU (Bilingual Evaluation Montsudy):
sacrebleu à Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (sous-étude orientée rappel pour l'évaluation de l'essentiel):
rouge en Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Perplexité:
perplexity = model.perplexity(generated_paraphrases)Mesures stylométriques:
stylometry en Python.from stylometry import extract_features; features = extract_features(generated_paraphrases)Pour intégrer ces mesures d'évaluation dans votre pipeline axolotl, suivez ces étapes:
Préparez vos données de formation en créant un ensemble de données de paragraphes des travaux de l'auteur cible et en les divisant en ensembles de formation et de validation.
Affinez votre modèle de langue à l'aide de l'ensemble de formation, en suivant l'approche discutée précédemment.
Générez des paraphrases pour les paragraphes dans l'ensemble de validation à l'aide du modèle affiné.
Mettez en œuvre les mesures d'évaluation à l'aide des bibliothèques respectives ( sacrebleu , rouge , stylometry ) et calculez les scores pour chaque paraphrase générée.
Effectuer une évaluation humaine en collectant les cotes et les commentaires des évaluateurs humains.
Analysez les résultats de l'évaluation pour évaluer la qualité et le style des paraphrases générées et prendre des décisions éclairées pour améliorer votre processus de réglage fin.
Voici un exemple de la façon dont vous pouvez intégrer ces mesures dans votre pipeline:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )N'oubliez pas d'installer les bibliothèques nécessaires (Sacrebleu, Rouge, Stylométrie) et adaptez le code pour s'adapter à votre implémentation dans Axolotl ou similaire.
Dans cette expérience, j'ai exploré les capacités et les différences entre divers modèles d'IA dans la génération d'un texte de 1500 mots basé sur une invite détaillée. J'ai testé des modèles à partir de https://chat.lmsys.org/, Chatgpt4, Claude 3 Opus et certains modèles locaux dans LM Studio. Chaque modèle a généré le texte trois fois pour observer la variabilité de leurs sorties. J'ai également créé une invite distincte pour évaluer l'écriture de la première itération de chaque modèle et demandé à Chatgpt 4 et à Claude Opus 3 de fournir des commentaires.
Grâce à ce processus, j'ai observé que certains modèles présentent une variabilité plus élevée entre les exécutions, tandis que d'autres ont tendance à utiliser un libellé similaire. Il y avait également des différences significatives dans le nombre de mots générés et la quantité de dialogue, descriptions et des paragraphes produits par chaque modèle. Les commentaires de l'évaluation ont révélé que le chatppt suggère une prose plus "raffinée", tandis que Claude recommande moins de prose violette. Sur la base de ces résultats, j'ai compilé une liste de plats à emporter à intégrer dans l'invite suivante, en me concentrant sur la précision, des structures de phrases variées, des verbes forts, des rebondissements uniques sur les motifs fantastiques, un ton cohérent, une voix de narrateur distincte et un rythme engageant. Une autre technique à considérer est de demander des commentaires, puis de réécrire le texte en fonction de ces commentaires.
Je suis ouvert à collaborer avec d'autres pour affiner les invites pour chaque modèle et explorer leurs capacités dans les tâches d'écriture créative.
Les modèles ont des biais de formatage inhérent. Certains modèles préfèrent les traits de traits pour les listes, d'autres astérisques. Lorsque vous utilisez ces modèles, il est utile de refléter leurs préférences pour des sorties cohérentes.
Formatage des tendances:
Llama 3 préfère les listes avec des rubriques en gras et des astérisques.
Exemple: Cas de titre en gras
Énumérez les éléments avec des astérisques après deux nouvelles lignes
Liste des éléments séparés par une nouvelle ligne
Liste suivante
Plus d'éléments de liste
Etc...
Exemples à quelques coups:
Adhésion à l'invite du système:
Fenêtre de contexte:
Censure:
Intelligence:
Cohérence:
Listes et formatage:
Paramètres de chat:
Paramètres du pipeline:
Llama 3 est flexible et intelligent mais a du contexte et des limitations de citation. Ajustez les méthodes d'incitation en conséquence.
Tous les commentaires sont les bienvenus. Ouvrez un problème ou envoyez une demande de traction si vous trouvez des bogues ou si vous avez des recommandations d'amélioration.
Ce projet est licencié sous: Licence Attribution-Noncommercial-Noderivatives (BY-NC-ND) Voir: https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en


