paper2slides
1.0.0
Transformez tous les papiers ARXIV en diapositives en utilisant de grands modèles de langage (LLMS)! Cet outil est utile pour saisir rapidement les principales idées des articles de recherche.
Certains exemples de lames générées sont: Word2Vec, Gan, Transformer, Vit, chaîne de pensées, étoile, DPO et scientifique AI. Voir de nombreux autres exemples de lames générées dans la démo.
Le script téléchargera des fichiers depuis Internet (ARXIV), envoie des informations à l'API OpenAI et compile localement. Veuillez être prudent quant au contenu partagé et aux risques potentiels. Si vous avez un ID ARXIV spécifique qui vous intéresse et que vous ne souhaitez pas exécuter le code vous-même, faites-le moi savoir dans les "discussions" et je serais heureux d'ajouter les diapositives à la liste de démonstration.
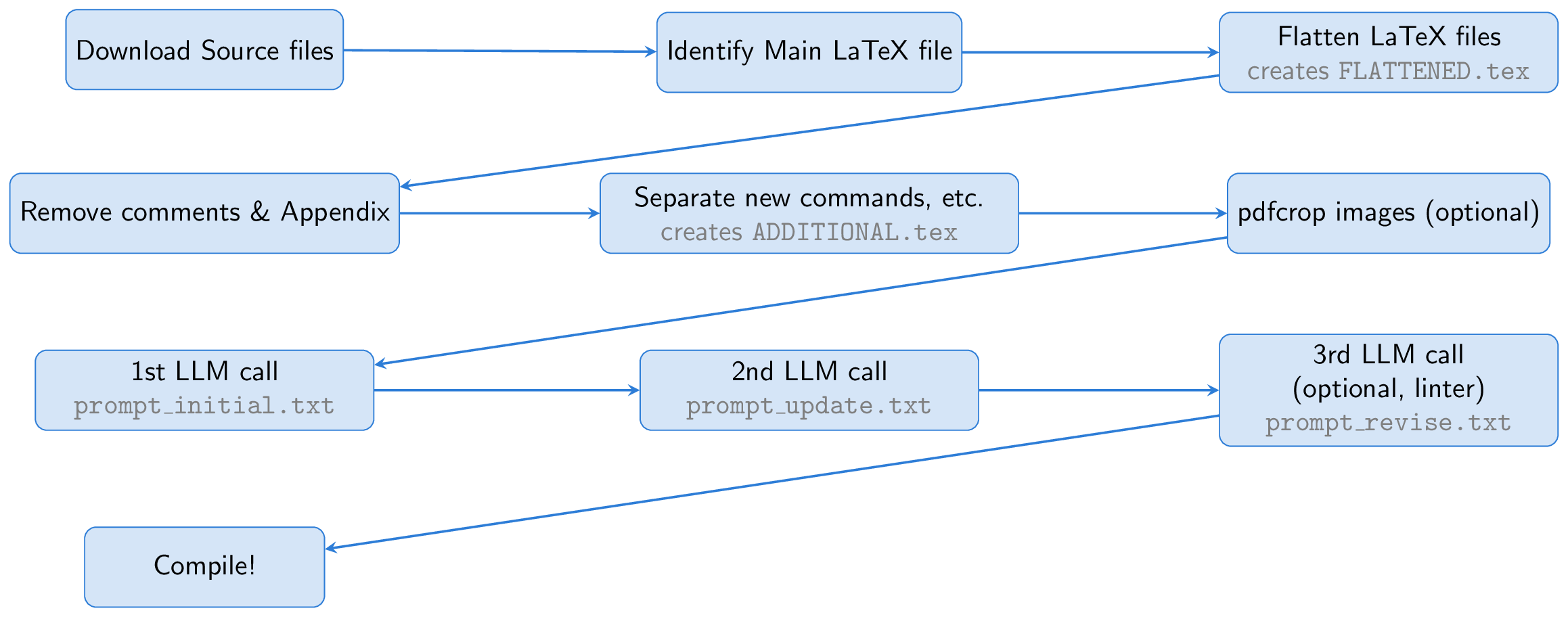
Le processus commence par télécharger les fichiers source d'un papier arxiv. Le fichier de latex principal est identifié et aplati, fusionnant tous les fichiers d'entrée dans un seul document ( FLATTENED.tex ). Nous avons prétraité ce fichier fusionné en supprimant les commentaires et l'annexe. Ce fichier prétraité, ainsi que des instructions pour créer de bonnes diapositives, constituent la base de notre invite.
Une idée clé est d'utiliser Beamer pour la création de diapositives, ce qui nous permet de rester entièrement dans l'écosystème de latex. Cette approche transforme essentiellement la tâche en exercice de résumé: convertir un long papier en latex en latex de Beamer concis. Le LLM peut déduire le contenu des chiffres de leurs légendes et les inclure dans les diapositives, éliminant le besoin de capacités de vision.
Pour aider le LLM, nous créons un fichier appelé ADDITIONAL.tex , qui contient tous les packages nécessaires, les définitions newCommand et les autres paramètres de latex utilisés dans l'article. Y compris ce fichier avec input{ADDITIONAL.tex} dans l'invite le raccourcit et rend les diapositives de génération plus fiables, en particulier pour les articles théoriques avec de nombreuses commandes personnalisées.
Le LLM génère du code Beamer à partir de la source de latex, mais comme la première exécution peut avoir des problèmes, nous demandons au LLM de s'inspecter et d'affiner la sortie. Facultativement, une troisième étape consiste à utiliser un linter pour vérifier le code généré, les résultats renvoyés au LLM pour d'autres corrections (cette étape de linter a été inspirée par le scientifique de l'IA). Enfin, le code Beamer est compilé dans une présentation PDF à l'aide de PDFlatex.
Le script all.zsh automatise l'intégralité du processus, terminant généralement en moins de quelques minutes avec GPT-4O pour un seul papier.
Les exigences sont:
requestsarxivopenaiarxiv-latex-cleanerpdflatexÉtapes pour l'installation:
Cloner ce référentiel:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesInstallez les packages Python requis:
pip install requests arxiv openai arxiv-latex-cleaner Assurez-vous que pdflatex est installé et disponible dans le chemin de votre système. Vérifiez éventuellement si vous pouvez compiler l'échantillon test.tex par pdflatex test.tex . Vérifiez si test.pdf est généré correctement. Vérifier éventuellement chktex et pdfcrop fonctionnent.
Configurez votre clé API OpenAI:
export OPENAI_API_KEY= ' your-api-key ' all.shCe script automatise le processus de téléchargement d'un papier arxiv, de le traiter et de le convertir en présentation Beamer.
bash all.sh < arxiv_id > Remplacez <arxiv_id> par l'ID de papier ArXIV souhaité. L'ID peut être identifié à partir de l'URL: l'ID pour https://arxiv.org/abs/xxxx.xxxx est xxxx.xxxx .
Vous pouvez également exécuter les scripts Python individuellement pour plus de contrôle.
Télécharger et traiter les fichiers source arxiv
python arxiv2tex.py < arxiv_id > Ce script télécharge les fichiers source du papier Arxiv spécifié, les extrait et traite le fichier de latex principal. Les résultats seront enregistrés dans source/<arxiv_id>/FLATTENED.tex et source/<arxiv_id>/ADDITIONAL.tex .
Convertir le latex en Beamer
python tex2beamer.py --arxiv_id < arxiv_id > Ce script lit les fichiers en latex traités et prépare les diapositives Beamer. C'est là que nous utilisons l'API OpenAI. Nous appelons deux fois, d'abord pour générer le code Beamer, puis pour inspecter le code Beamer. Utilisez éventuellement les indicateurs suivants: --use_linter et --use_pdfcrop . Les invites envoyées au LLM et la réponse du LLM seront enregistrées dans tex2beamer.log . Le journal Linter sera enregistré dans source/<arxiv_id>/linter.log .
Convertir Beamer en PDF
python beamer2pdf.py < arxiv_id >Ce script compile le fichier Beamer dans une présentation PDF.
Les invites sont enregistrées dans prompt_initial.txt , prompt_update.txt et prompt_revise.txt mais n'hésitez pas à les ajuster à vos besoins. Ils contiennent un espace réservé appelé PLACEHOLDER_FOR_FIGURE_PATHS . Ceci sera remplacé par les chemins de figure utilisés dans le papier. Nous voulons nous assurer que les chemins sont correctement utilisés dans le code Beamer. Le LLM fait souvent des erreurs, nous incluons donc explicitement cela dans l'invite.
Le taux de réussite est d'environ 90% dans mon expérience (la compilation peut échouer ou le chemin d'image peut être faux dans certains cas). Si vous rencontrez des problèmes ou si vous avez des suggestions d'amélioration, n'hésitez pas à me le faire savoir!


