multi model server
v1.1.11 - Extra error logging and new timeout config
| Ubuntu / Python-2.7 | Ubuntu / Python-3.6 |
|---|---|
Multi Model Server (MMS) est un outil flexible et facile à utiliser pour servir des modèles d'apprentissage en profondeur formés à l'aide de n'importe quel cadre ML / DL.
Utilisez le MMS Server CLI, ou les images Docker préconfigurées, pour démarrer un service qui configure les points de terminaison HTTP pour gérer les demandes d'inférence du modèle.
Un aperçu rapide et des exemples de service et d'emballage sont fournis ci-dessous. Des documents détaillés et des exemples sont fournis dans le dossier DOCS.
Rejoignez notre Slack Channel pour entrer en contact avec l'équipe de développement, poser des questions, découvrir ce que la cuisine et plus encore!
Slack Channel pour entrer en contact avec l'équipe de développement, poser des questions, découvrir ce que la cuisine et plus encore!
Avant de poursuivre ce document, assurez-vous d'avoir les conditions suivantes.
Ubuntu, Centos ou MacOS. Le support Windows est expérimental. Les instructions suivantes se concentreront uniquement sur Linux et MacOS.
Python - Multi Mode Model Server nécessite Python pour exécuter les travailleurs.
PIP - PIP est un système de gestion des packages Python.
Java 8 - Multi Mode Model Server nécessite que Java 8 commence. Vous avez les options suivantes pour installer Java 8:
Pour Ubuntu:
sudo apt-get install openjdk-8-jre-headlessPour Centos:
sudo yum install java-1.8.0-openjdkPour macOS:
brew tap homebrew/cask-versions
brew update
brew cask install adoptopenjdk8Étape 1: Configurer un environnement virtuel
Nous vous recommandons d'installer et d'exécuter un serveur multi-modèles dans un environnement virtuel. C'est une bonne pratique pour exécuter et installer toutes les dépendances Python dans des environnements virtuels. Cela fournira l'isolement des dépendances et facilitera la gestion des dépendances.
Une option consiste à utiliser VirtualEnv. Ceci est utilisé pour créer des environnements Python virtuels. Vous pouvez installer et activer un VirtualEnv pour Python 2.7 comme suit:
pip install virtualenvCréez ensuite un environnement virtuel:
# Assuming we want to run python2.7 in /usr/local/bin/python2.7
virtualenv -p /usr/local/bin/python2.7 /tmp/pyenv2
# Enter this virtual environment as follows
source /tmp/pyenv2/bin/activateReportez-vous à la documentation VirtualEnv pour plus d'informations.
Étape 2: installer MXNET MMS n'installe pas le moteur MXNET par défaut. S'il n'est pas déjà installé dans votre environnement virtuel, vous devez installer l'un des packages MXNET PIP.
Pour l'inférence du CPU, mxnet-mkl est recommandé. Installez-le comme suit:
# Recommended for running Multi Model Server on CPU hosts
pip install mxnet-mkl Pour l'inférence GPU, mxnet-cu92mkl est recommandé. Installez-le comme suit:
# Recommended for running Multi Model Server on GPU hosts
pip install mxnet-cu92mklÉtape 3: installer ou mettre à niveau les MM comme suit:
# Install latest released version of multi-model-server
pip install multi-model-server Pour passer à partir d'une version précédente de multi-model-server , veuillez référer le document de référence de migration.
Notes:
model-archiver sera installée avec MMS comme dépendance. Voir Model-Archiver pour plus d'options et de détails. Une fois installé, vous pouvez faire fonctionner MMS Model Server très rapidement. Essayez --help pour voir toutes les options CLI disponibles.
multi-model-server --helpPour ce démarrage rapide, nous sauterons la plupart des fonctionnalités, mais assurez-vous de jeter un œil aux documents du serveur complet lorsque vous êtes prêt.
Voici un exemple facile pour servir un modèle de classification d'objet:
multi-model-server --start --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.marAvec la commande ci-dessus exécutée, vous avez des mms exécutés sur votre hôte, en écoutant les demandes d'inférence. Veuillez noter que si vous spécifiez les modèles (s) pendant le démarrage de MMS - il mettra automatiquement à l'échelle des travailleurs backend au nombre de VCPU disponibles (si vous exécutez sur l'instance CPU) ou au nombre de GPU disponibles (si vous exécutez sur l'instance GPU ). En cas d'hôtes puissants avec de nombreuses ressources de calcul (VCPU ou GPU), ce processus de démarrage et d'autoscalités pourrait prendre un temps considérable. Si vous souhaitez minimiser le temps de démarrage du MMS, vous pouvez essayer d'éviter de vous inscrire et d'intensifier le modèle pendant le temps de démarrage et de passer à un point ultérieur en utilisant des appels API de gestion correspondants (cela permet un contrôle des grains plus fin à la quantité de ressources allouées pour tout modèle particulier).
Pour le tester, vous pouvez ouvrir une nouvelle fenêtre de terminal à côté de celle qui exécute MMS. Ensuite, vous pouvez utiliser curl pour télécharger l'une de ces jolies photos d'un chaton de chaton et -o Curl, le nommera kitten.jpg pour vous. Ensuite, vous curl un POST sur le point de terminaison de prédire MMS avec l'image du chaton.

Dans l'exemple ci-dessous, nous fournissons un raccourci pour ces étapes.
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpgLe point de terminaison de prédire renverra une réponse de prédiction dans JSON. Cela ressemblera à le résultat suivant:
[
{
"probability" : 0.8582232594490051 ,
"class" : " n02124075 Egyptian cat "
},
{
"probability" : 0.09159987419843674 ,
"class" : " n02123045 tabby, tabby cat "
},
{
"probability" : 0.0374876894056797 ,
"class" : " n02123159 tiger cat "
},
{
"probability" : 0.006165083032101393 ,
"class" : " n02128385 leopard, Panthera pardus "
},
{
"probability" : 0.0031716004014015198 ,
"class" : " n02127052 lynx, catamount "
}
] Vous verrez ce résultat dans la réponse à votre appel curl au point de terminaison de prédire et dans les journaux du serveur dans la fenêtre de terminal exécutant MMS. Il est également enregistré localement avec des mesures.
D'autres modèles peuvent être téléchargés à partir du Zoo du modèle, alors essayez également certains d'entre eux.
Maintenant, vous avez vu à quel point il peut être facile de servir un modèle d'apprentissage en profondeur avec MMS! Souhaitez-vous en savoir plus?
Pour arrêter l'instance Model-Server en cours d'exécution, exécutez la commande suivante:
$ multi-model-server --stopVous verriez la sortie spécifiant que le serveur multimodel s'est arrêté.
MMS vous permet d'emballer tous vos artefacts de modèle en une seule archive de modèle. Cela facilite le partage et le déploiement de vos modèles. Pour emballer un modèle, consultez la documentation du modèle Archiver
Poursuivez le DOCS Readme pour l'indice complet de la documentation. Cela comprend plus d'exemples, comment personnaliser le service API, les détails des points de terminaison API, etc.
Voici quelques exemples de démos d'applications d'apprentissage en profondeur, alimentées par MMS:
Classification d'examen des produits 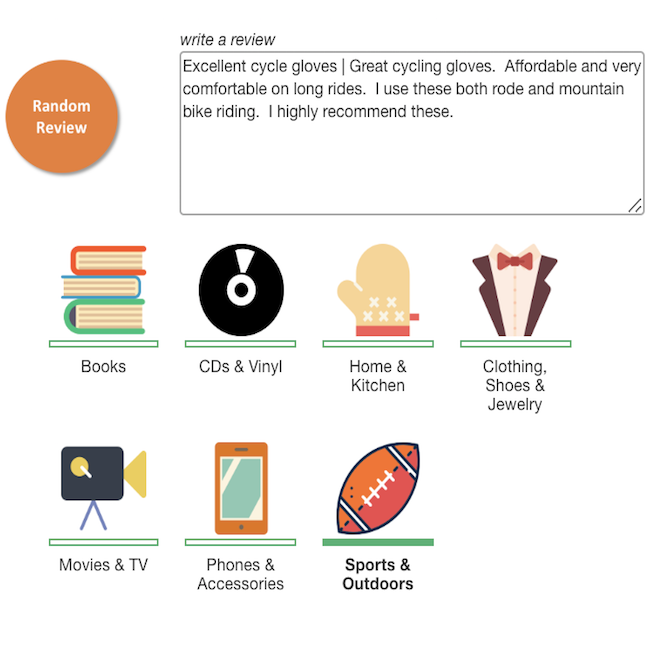 | Recherche visuelle 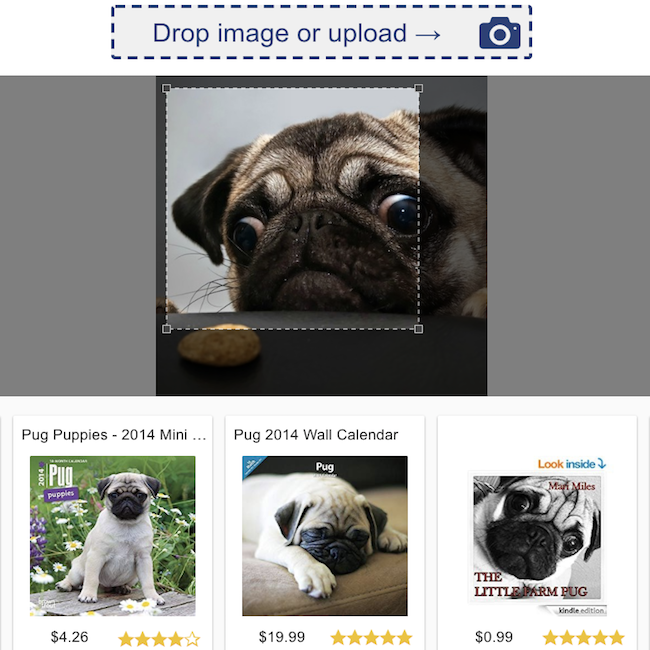 |
Reconnaissance des émotions faciales  | Transfert de style neuronal  |
Nous accueillons toutes les contributions!
Pour déposer un bogue ou demander une fonctionnalité, veuillez déposer un problème GitHub. Les demandes de traction sont les bienvenues.


