descript audio codec
1.0.0
Ce référentiel contient des scripts de formation et d'inférence pour le codec audio descriptions (.DAC), un codec audio général de haute fidélité, introduit dans l'article intitulé Compression audio haute fidélité avec RVQGAN amélioré .
Papier Arxiv: compression audio haute fidélité avec RVQGAN amélioré
? Site de démonstration
⚙ Poids du modèle
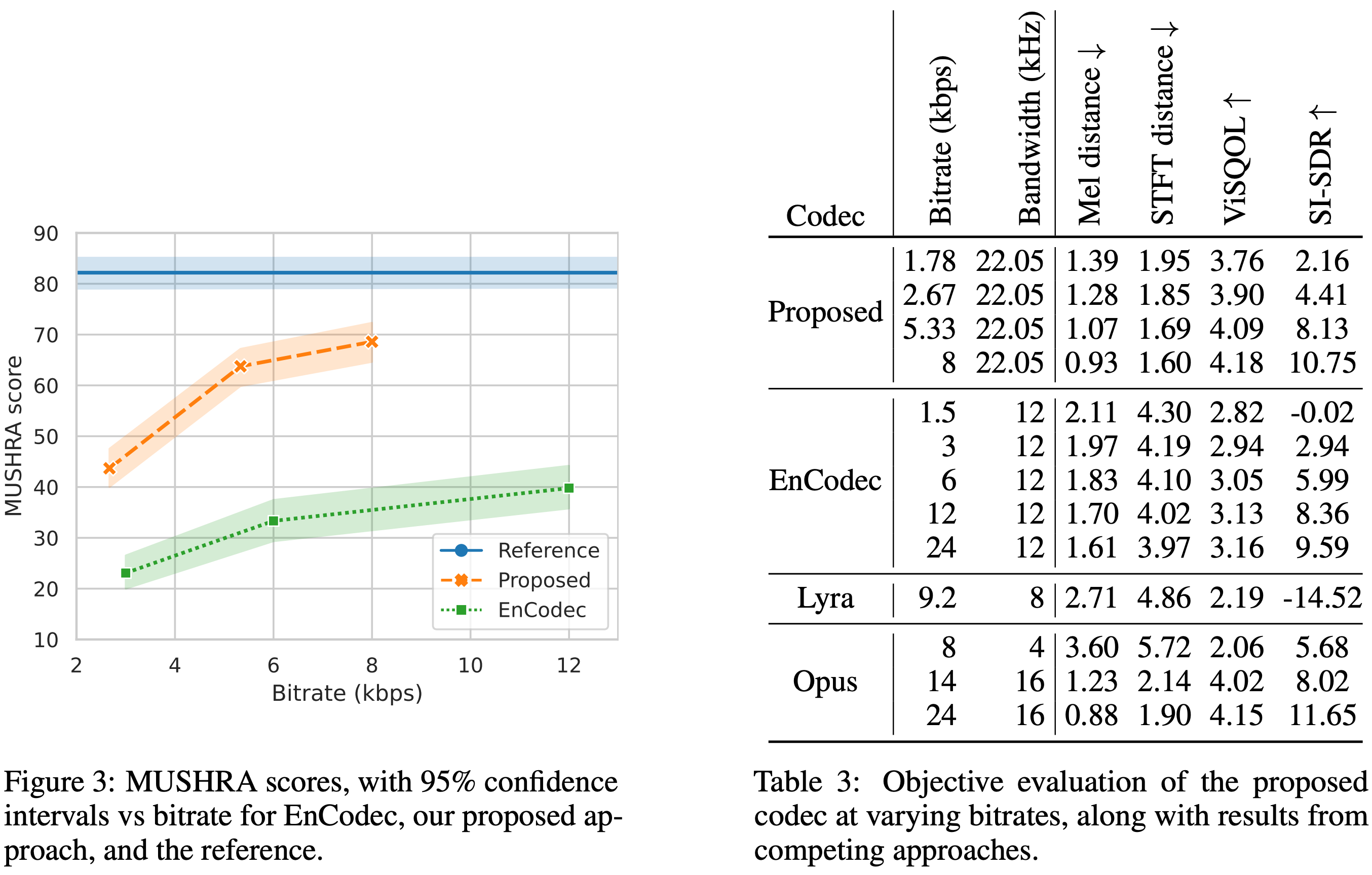
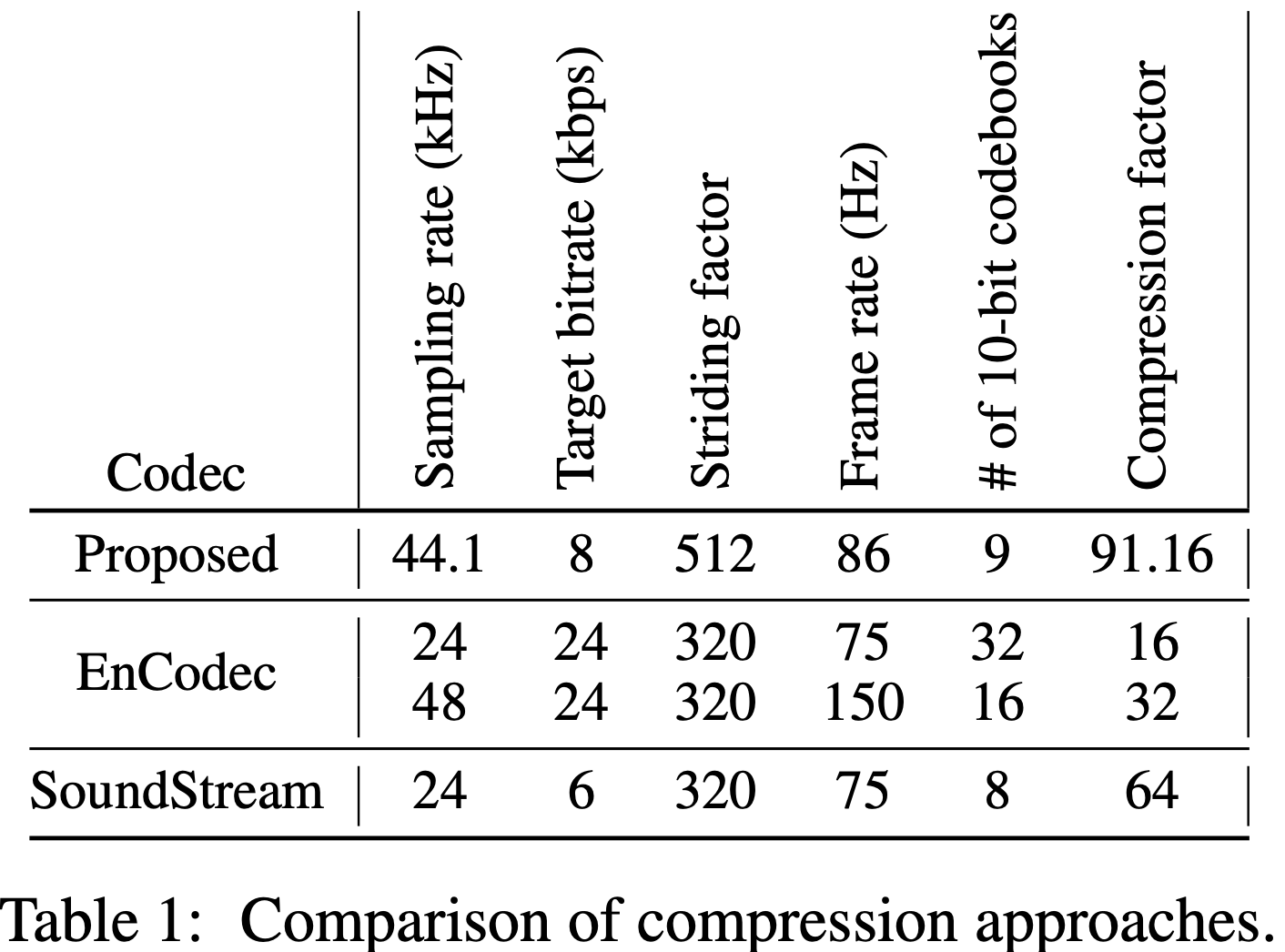
Avec le codec audio descriptions, vous pouvez compresser l'audio de 44,1 kHz en codes discrets à un débit binaire bas de 8 kbps .
? C'est une compression d'environ 90x tout en maintenant une fidélité exceptionnelle et en minimisant les artefacts.
? Notre modèle universel fonctionne sur tous les domaines (discours, environnement, musique, etc.), ce qui le rend largement applicable à la modélisation générative de tous les audio.
? Il peut être utilisé comme remplacement de rendez-vous pour Encodec pour toutes les applications de modélisation du langage audio (telles que Audiolms, Musiclms, MusicGen, etc.)
pip install descript-audio-codec
OU
pip install git+https://github.com/descriptinc/descript-audio-codec
Les poids sont publiés dans le cadre de ce dépôt sous licence MIT. Nous libérons des poids pour les modèles qui peuvent supporter nativement 16 kHz, 24 kHz et des taux d'échantillonnage de 44,1 kHz. Les poids sont automatiquement téléchargés lorsque vous exécutez la commande encode ou decode pour la première fois. Vous pouvez les mettre en cache en utilisant l'une des commandes suivantes
python3 -m dac download # downloads the default 44kHz variant
python3 -m dac download --model_type 44khz # downloads the 44kHz variant
python3 -m dac download --model_type 24khz # downloads the 24kHz variant
python3 -m dac download --model_type 16khz # downloads the 16kHz variantNous fournissons un dockerfile qui installe toutes les dépendances requises pour l'encodage et le décodage. Le processus de construction cache les poids du modèle par défaut à l'intérieur de l'image. Cela permet à l'image d'être utilisée sans connexion Internet. Veuillez vous référer aux instructions ci-dessous.
python3 -m dac encode /path/to/input --output /path/to/output/codes
Cette commande créera des fichiers .dac avec le même nom que les fichiers d'entrée. Il préservera également la structure du répertoire par rapport à la racine d'entrée et la recréera dans le répertoire de sortie. Veuillez utiliser python -m dac encode --help pour plus d'options.
python3 -m dac decode /path/to/output/codes --output /path/to/reconstructed_input
Cette commande créera des fichiers .wav avec le même nom que les fichiers d'entrée. Il préservera également la structure du répertoire par rapport à la racine d'entrée et la recréera dans le répertoire de sortie. Veuillez utiliser python -m dac decode --help pour plus d'options.
import dac
from audiotools import AudioSignal
# Download a model
model_path = dac . utils . download ( model_type = "44khz" )
model = dac . DAC . load ( model_path )
model . to ( 'cuda' )
# Load audio signal file
signal = AudioSignal ( 'input.wav' )
# Encode audio signal as one long file
# (may run out of GPU memory on long files)
signal . to ( model . device )
x = model . preprocess ( signal . audio_data , signal . sample_rate )
z , codes , latents , _ , _ = model . encode ( x )
# Decode audio signal
y = model . decode ( z )
# Alternatively, use the `compress` and `decompress` functions
# to compress long files.
signal = signal . cpu ()
x = model . compress ( signal )
# Save and load to and from disk
x . save ( "compressed.dac" )
x = dac . DACFile . load ( "compressed.dac" )
# Decompress it back to an AudioSignal
y = model . decompress ( x )
# Write to file
y . write ( 'output.wav' )Nous fournissons un DockerFile pour construire une image Docker avec toutes les dépendances nécessaires.
Construire l'image.
docker build -t dac .
En utilisant l'image.
Utilisation sur CPU:
docker run dac <command>
Utilisation sur GPU:
docker run --gpus=all dac <command>
<command> peut être l'une des commandes de compression et de reconstruction répertoriées ci-dessus. Par exemple, si vous souhaitez exécuter la compression,
docker run --gpus=all dac python3 -m dac encode ...
La configuration du modèle de base peut être formée à l'aide des commandes suivantes.
Veuillez installer les dépendances correctes
pip install -e ".[dev]"
Nous avons fourni une configuration DockerFile et Docker Compose qui facilite les expériences de course.
Pour construire l'image docker, faites:
docker compose build
Ensuite, pour lancer un conteneur, faites:
docker compose run -p 8888:8888 -p 6006:6006 dev
Les arguments portuaires ( -p ) sont facultatifs, mais utiles si vous souhaitez lancer un jupyter et des instances de tensorboard dans le conteneur. Le mot de passe par défaut pour Jupyter est password , et le répertoire actuel est monté sur /u/home/src , qui devient également le répertoire de travail.
Ensuite, exécutez votre commande de formation.
export CUDA_VISIBLE_DEVICES=0
python scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
export CUDA_VISIBLE_DEVICES=0,1
torchrun --nproc_per_node gpu scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
Nous fournissons deux scripts de test pour tester la fonctionnalité de formation CLI +. Veuillez vous assurer que les pré-réquisites Trainig sont satisfaites avant de lancer ces tests. Pour lancer ces tests, veuillez exécuter
python -m pytest tests