rlcard
RLCard 1.0.7
中文文档
RLCard est une boîte à outils pour le renforcement d'apprentissage (RL) dans les jeux de cartes. Il prend en charge plusieurs environnements de carte avec des interfaces faciles à utiliser pour implémenter divers algorithmes d'apprentissage et de recherche de renforcement. L'objectif de RLCard est de combler les jeux d'information sur l'apprentissage par renforcement et les informations imparfaites. RLCARD est développé par Data Lab de Rice and Texas A&M University et des contributeurs communautaires.
Communauté:
Nouvelles:
Les jeux suivants sont principalement développés et maintenus par des contributeurs communautaires. Merci!
Merci à tous les contributeurs!




























Si vous trouvez ce dépôt utile, vous pouvez citer:
Zha, Daochen et al. "RLCard: une plate-forme pour l'apprentissage du renforcement dans les jeux de cartes." Ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Assurez-vous que Python 3.6+ et PIP sont installés. Nous vous recommandons d'installer la version stable de rlcard avec pip :
pip3 install rlcard
L'installation par défaut n'inclura que les environnements de carte. Pour utiliser la mise en œuvre pytorch des algorithmes de formation, exécutez
pip3 install rlcard[torch]
Si vous êtes en Chine et que la commande ci-dessus est trop lente, vous pouvez utiliser le miroir fourni par l'Université Tsinghua:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
Alternativement, vous pouvez cloner la dernière version (si vous êtes en Chine et que GitHub est lent, vous pouvez utiliser le miroir en gitee):
git clone https://github.com/datamllab/rlcard.git
Ou seulement cloner une branche pour le rendre plus rapide:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
Puis installer avec
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
Nous fournissons également la méthode d'installation de conda :
conda install -c toubun rlcard
L'installation de Conda fournit uniquement les environnements de carte, vous devez installer manuellement Pytorch sur vos demandes.
Un court exemple est comme ci-dessous.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCard peut être connecté de manière flexible à divers algorithmes. Voir les exemples suivants:
Exécutez examples/human/leduc_holdem_human.py pour jouer avec le modèle LEDUC Hold'em pré-formé. LeDuc Hold'em est une version simplifiée du Texas Hold'em. Les règles peuvent être trouvées ici.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
Nous fournissons également une interface graphique pour un débogage facile. Veuillez vérifier ici. Quelques démos:
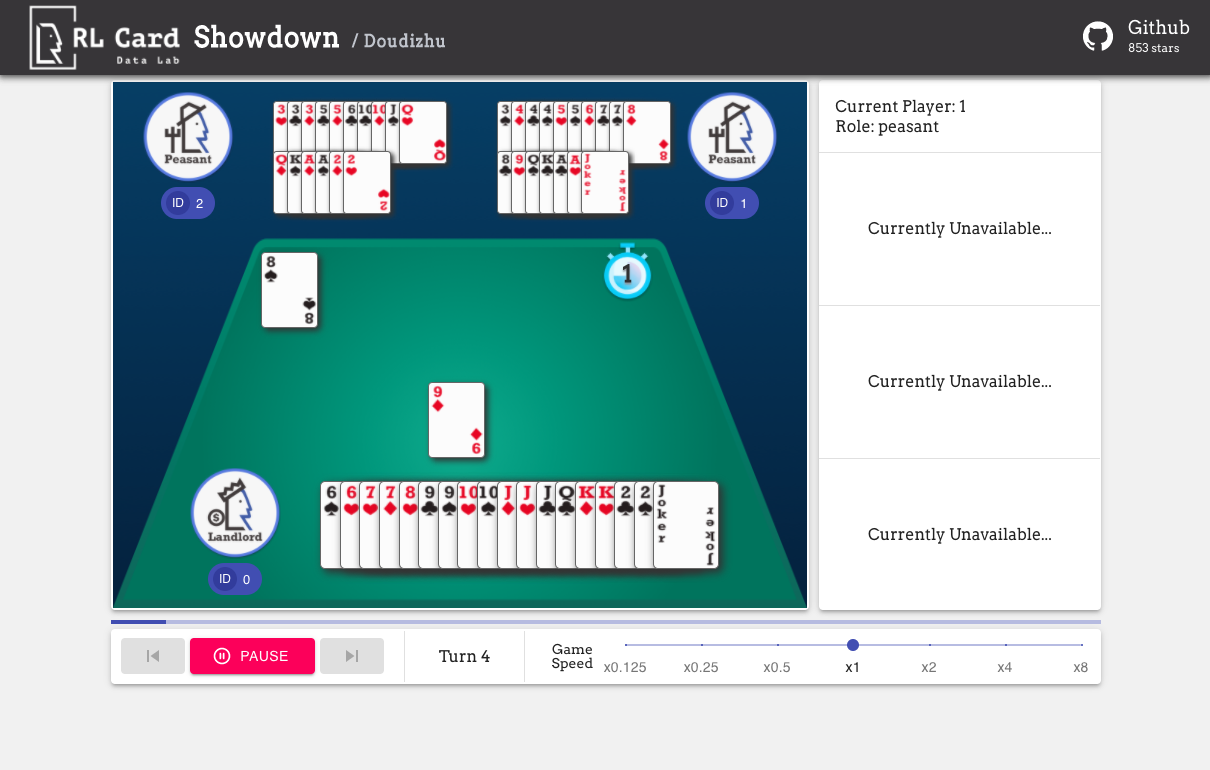
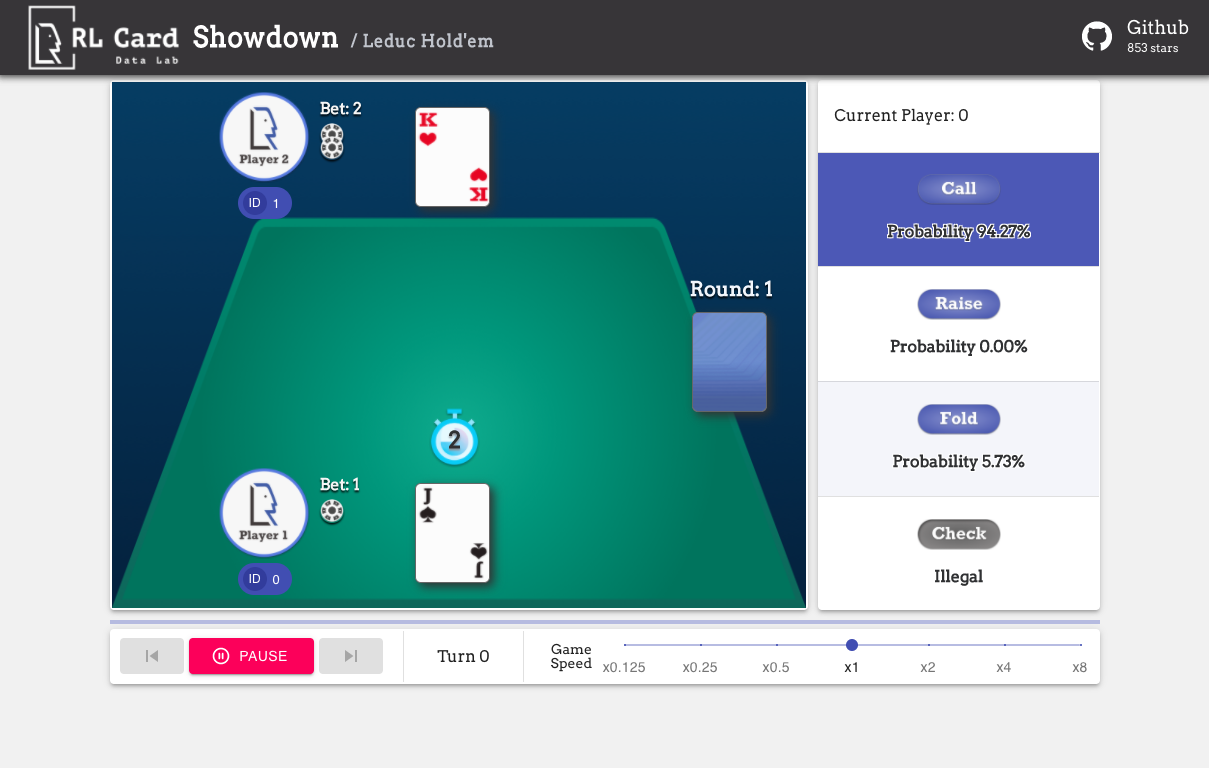
Nous fournissons une estimation de complexité pour les jeux sur plusieurs aspects. Numéro InfoSet: le nombre d'ensembles d'informations; Taille de l'infoset: le nombre moyen d'états dans un seul ensemble d'informations; Taille de l'action: la taille de l'espace d'action. Nom: le nom qui doit être transmis à rlcard.make pour créer l'environnement de jeu. Nous fournissons également le lien vers la documentation et l'exemple aléatoire.
| Jeu | Numéro entre Infoset | Taille de l'enfilage | Taille d'action | Nom | Usage |
|---|---|---|---|---|---|
| Blackjack (wiki, baike) | 10 ^ 3 | 10 ^ 1 | 10 ^ 0 | blackjack | Doc, exemple |
| Leduc Hold'em (papier) | 10 ^ 2 | 10 ^ 2 | 10 ^ 0 | leduc-holdem | Doc, exemple |
| Limiter le Texas Hold'em (Wiki, Baike) | 10 ^ 14 | 10 ^ 3 | 10 ^ 0 | limite | Doc, exemple |
| Dou Dizhu (Wiki, Baike) | 10 ^ 53 ~ 10 ^ 83 | 10 ^ 23 | 10 ^ 4 | Doudizhu | Doc, exemple |
| Mahjong (wiki, baike) | 10 ^ 121 | 10 ^ 48 | 10 ^ 2 | mahjong | Doc, exemple |
| No-limit texas hold'em (wiki, baike) | 10 ^ 162 | 10 ^ 3 | 10 ^ 4 | sans limite | Doc, exemple |
| Uno (wiki, baike) | 10 ^ 163 | 10 ^ 10 | 10 ^ 1 | uno | Doc, exemple |
| Gin rami (wiki, baike) | 10 ^ 52 | - | - | gin-rimy | Doc, exemple |
| Bridge (wiki, baike) | - | - | pont | Doc, exemple |
| Algorithme | exemple | référence |
|---|---|---|
| Deep Monte-Carlo (DMC) | Exemples / run_dmc.py | [papier] |
| Learning Q-Learning (DQN) | Exemples / run_rl.py | [papier] |
| Auto-play fictive neurale (NFSP) | Exemples / run_rl.py | [papier] |
| Minimisation des regrets contrefactuels (CFR) | Exemples / run_cfr.py | [papier] |
Nous fournissons un zoo modèle pour servir de lignes de base.
| Modèle | Explication |
|---|---|
| Leduc-Holdem-Cfr | Modèle CFR pré-formé (échantillonnage de hasard) sur LeDuc Hold'em |
| Leduc-Holdem-Rule-V1 | Modèle basé sur des règles pour LeCUc Hold'em, V1 |
| leduc-Holdem-Rule-V2 | Modèle basé sur des règles pour LeCUc Hold'em, V2 |
| Uno-Rule-V1 | Modèle basé sur les règles pour l'UNO, V1 |
| limite-holdem-rule-v1 | Modèle basé sur des règles pour Limit Texas Hold'em, V1 |
| Doudizhu-Rule-V1 | Modèle basé sur des règles pour Dou Dizhu, V1 |
| gin-rummy-novice-Rule | Modèle de règle novice du rami |
Vous pouvez utiliser l'interface suivante pour créer un environnement. Vous pouvez éventuellement spécifier certaines configurations avec un dictionnaire.
env_id est une chaîne d'un environnement; config est un dictionnaire qui spécifie certaines configurations d'environnement, qui sont les suivantes.seed : par défaut None . Définissez une graine aléatoire locale de l'environnement pour reproduire les résultats.allow_step_back : par défaut False . True si vous permettant à la fonction step_back de traverser vers l'arrière dans l'arbre.game_ . Actuellement, nous ne soutenons que game_num_players dans Blackjack ,.Une fois l'environnement réalisé, nous pouvons accéder à certaines informations du jeu.
L'état est un dictionnaire Python. Il se compose d' state['obs'] , state['legal_actions'] , state['raw_obs'] et state['raw_legal_actions'] .
Les interfaces suivantes fournissent une utilisation de base. Il est facile à utiliser, mais il a des suppositions sur l'agent. L'agent doit suivre le modèle d'agent.
agents est une liste d'objets Agent . La durée de la liste doit être égale au nombre de joueurs du jeu.set_agents . Si is_training est True , il utilisera la fonction step dans l'agent pour jouer au jeu. Si is_training est False , eval_step sera appelé à la place.Pour une utilisation avancée, les interfaces suivantes permettent des opérations flexibles sur l'arbre de jeu. Ces interfaces ne font aucune supposition sur l'agent.
action peut être une action brute ou un entier; raw_action doit être True si l'action est une action brute (chaîne).allow_step_back est True . Faites un pas en arrière. Cela peut être utilisé pour les algorithmes qui fonctionnent sur l'arborescence du jeu, comme CFR (échantillonnage de hasard).True si le jeu actuel est terminé. Autrement, retournez False .player_id .Les objectifs des modules principaux sont répertoriés comme ci-dessous:
Pour plus de documentation, veuillez vous référer aux documents pour les introductions générales. Les documents API sont disponibles sur notre site Web.
La contribution à ce projet est grandement appréciée! Veuillez créer un problème pour les commentaires / bogues. Si vous souhaitez contribuer des codes, veuillez vous référer au guide contributeur. Si vous avez des questions, veuillez contacter Daochen Zha avec [email protected].
Nous tenons à remercier JJ World Network Technology Co., Ltd pour le généreux soutien et toutes les contributions des contributeurs communautaires.


