kubeai
helm-chart-models-0.9.0
Obtenez l'inférence en cours d'exécution sur Kubernetes: LLMS, Embeddings, Speech-to-Text.
✅️ Remplacement de rendez-vous pour OpenAI par la compatibilité de l'API
⚖️ Échelle à partir de zéro, à l'échelle autochtone en fonction de la charge
? Servir les modèles de génération de texte (LLMS, VLMS, etc.)
API de la parole
? API d'intégration / vecteur
Multi-plateforme: CPU uniquement, GPU, TPU
? Modèle de mise en cache avec les systèmes de fichiers partagés (EFS, FileStore, etc.)
Zéro dépendances (ne dépend pas d'Istio, du Knative, etc.)
CHAT UI inclus (OpenWebui)
? Exploite des serveurs de modèle OSS (VLLM, Olllama, plus rapide, Infinity)
✉ Inférence Stream / Batch via des intégrations de messagerie (Kafka, Pubsub, etc.)
Citations de la communauté:
Solution réutilisable et bien abstraite pour exécuter les LLM - Mike Ensor
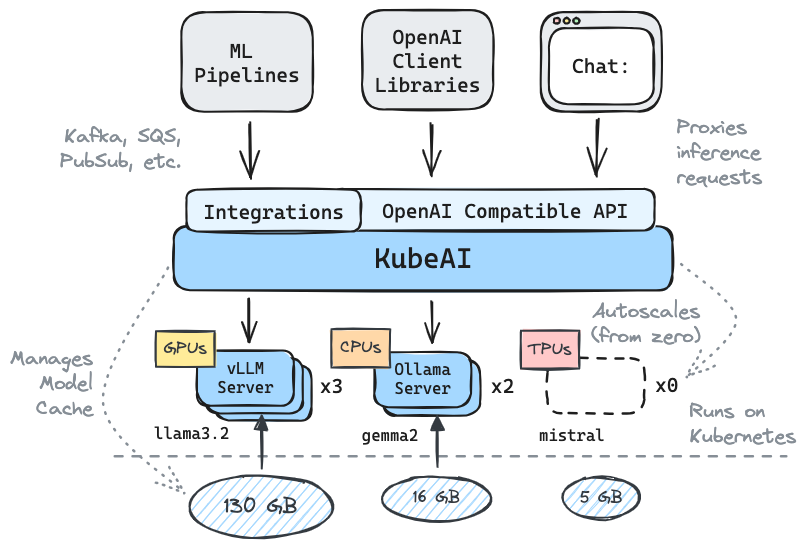
Kubeai sert une API HTTP compatible OpenAI. Les administrateurs peuvent configurer les modèles ML via kind: Model de ressources personnalisées Kubernetes. Kubeai peut être considéré comme un opérateur de modèle (voir le modèle de l'opérateur) qui gère les serveurs VLLM et OLLAMA.
Créez un cluster local à l'aide de Kind ou Minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startAjoutez le référentiel Kubeai Helm.
helm repo add kubeai https://www.kubeai.org
helm repo updateInstallez Kubeai et attendez que tous les composants soient prêts (peut prendre une minute).
helm install kubeai kubeai/kubeai --wait --timeout 10mInstallez certains modèles prédéfinis.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlAvant de progresser vers les étapes suivantes, commencez une montre sur les pods dans un terminal autonome pour voir comment Kubeai déploie les modèles.
kubectl get pods --watch Parce que nous définissons minReplicas: 1 pour le modèle Gemma, vous devriez voir un modèle de modèle à venir.
Commencez un port local à l'interface utilisateur de chat groupé.
kubectl port-forward svc/openwebui 8000:80Maintenant, ouvrez votre navigateur à LocalHost: 8000 et sélectionnez le modèle Gemma pour commencer à discuter avec.
Si vous retournez au navigateur et commencez une conversation avec QWEN2, vous remarquerez qu'il faudra un certain temps pour répondre au début. En effet, nous définissons minReplicas: 0 pour ce modèle et Kubeai doit faire tourner un nouveau pod (vous pouvez vérifier avec kubectl get models -oyaml qwen2-500m-cpu ).
Découvrez notre documentation sur kubeai.org pour trouver des informations sur:
Liste des adoptants connus:
| Nom | Description | Lien |
|---|---|---|
| Télescope | Le télescope utilise Kubeai pour l'inférence LLM à grande échelle à grande échelle. | trytelelescope.ai |
| Google Cloud Distributed Edge | Kubeai est inclus comme architecture de référence pour l'inférence au bord. | LinkedIn, gitlab |
| Lambda | Vous pouvez essayer Kubeai sur le Cloud Lambda AI Developer Cloud. Voir le tutoriel et la vidéo de Lambda. | Lambda |
Si vous utilisez Kubeai et que vous souhaitez être répertorié comme adoptant, veuillez faire un PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* Remarque: Kubeai est né d'un projet appelé Lingo qui était un simple proxy Kubernetes LLM avec automatique de base. Nous avons relancé le projet en tant que Kubeai (fin août 2024) et étendu la feuille de route à ce qu'elle est aujourd'hui.
? N'oubliez pas de nous laisser une étoile sur Github et suivez le dépôt pour rester à jour!
Faites-nous savoir les fonctionnalités que vous souhaitez voir ou contacter avec des questions. Visitez notre canal Discord pour rejoindre la discussion!
Ou contactez simplement LinkedIn si vous souhaitez vous connecter:


