ChatIE
1.0.0
Référentiel officiel de papier "Extraction d'informations zéro par chat avec chatppt". Veuillez jouer, regarder et alimenter notre dépôt pour les mises à jour actives!
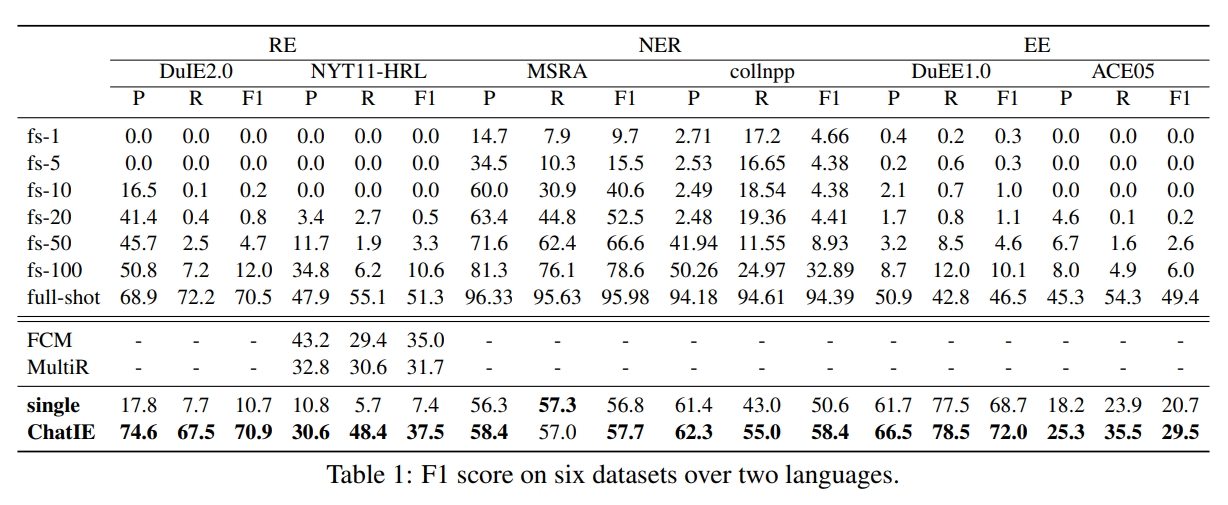
L'extraction d'informations zéro-tir (IE) vise à construire des systèmes IE à partir du texte non annoté. C'est difficile en raison de l'implication de peu d'intervention humaine. Difficile mais valable, Zero-Shot IE réduit le temps et les efforts que prend l'étiquetage des données. Les efforts récents sur les modèles de grande langue (LLMS, EG, GPT3, Chatgpt) montrent des performances prometteuses sur des paramètres de tirs zéro, nous inspirant ainsi à explorer des méthodes basées sur des méthodes. Dans ce travail, nous demandons si des modèles IE puissants peuvent être construits en invitant directement les LLM. Plus précisément, nous transformons la tâche IE à tirs zéro en un problème de réponse à plusieurs tours avec un framework en deux étapes (Chatie). Avec la puissance de Chatgpt, nous évaluons largement notre cadre sur trois tâches IE: Triple Extrait entité, reconnaissance de l'entité et extraction d'événements. Les résultats empiriques sur six ensembles de données sur deux langues montrent que Chatie réalise des performances impressionnantes et dépasse même certains modèles à coup complet sur plusieurs ensembles de données (par exemple, NYT11-HRL). Nous pensons que notre travail pourrait faire la lumière sur la construction de modèles IE avec des ressources limitées.
零样本信息抽取 (Extraction d'informations , c'est-à-dire) 旨在从无标注文本中建立 c'est-à-dire 系统 , 因为很少涉及人为干预 , 该问题非常具有挑战性。但零样本 ie 不再需要标注数据时耗费的时间和人力, 因此十分重要。近来的大规模语言模型 (例如 GPT-3 , Chat GPT) 在零样本设置下取得了很好的表现 , 这启发我们探索基于提示的方法来解决零样本 IE 任务。我们提出一个问题 : 不经过训练来实现零样本信息抽取是否可行?我们将零样本 c'est-à-dire 任务转变为一个两阶段框架的多轮问答问题 (CHAT IE), 并在三个 c'est-à-dire : : 实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的 6 个数据集上的实验结果表明 , Chat C'est-à-dire 取得了非常好的效果 , 甚至在几个数据集上 (例如 nyt11-hrl) 上超过了全监督模型的表现。我们的工作能够为有限资源下 ie 系统的建立奠定基础。
Mise à jour: Nous utilisons l'API officielle, l'outil devient plus rapide !!! Si la clé dépasse les limites, veuillez nous le dire.
AVIS: La vitesse de réponse dépend de l'API officielle Openai Chatgpt. (Parfois, le fonctionnaire est trop encombré et la vitesse sera lente ou le chatppt sera surchargé.) De plus, vous mieux d'utiliser votre propre clé Openai, car si notre compte par défaut est utilisé par plusieurs personnes en même temps, le compte peut être surchargé.
AVIS: Parce que l'API officielle n'est pas disponible dans Domestic, nous utilisons donc l'API de RevChatGPT et V1 version. Mais c'est trop lent , nous vous conseillons donc d'utiliser l'outil hors ligne pour l'étude. Nous mettrons à jour l'API plus loin à l'avenir ( TODO ).
Nous fournissons également un outil IE basé sur GPT3.5, vous pouvez voir dans gpt4ie
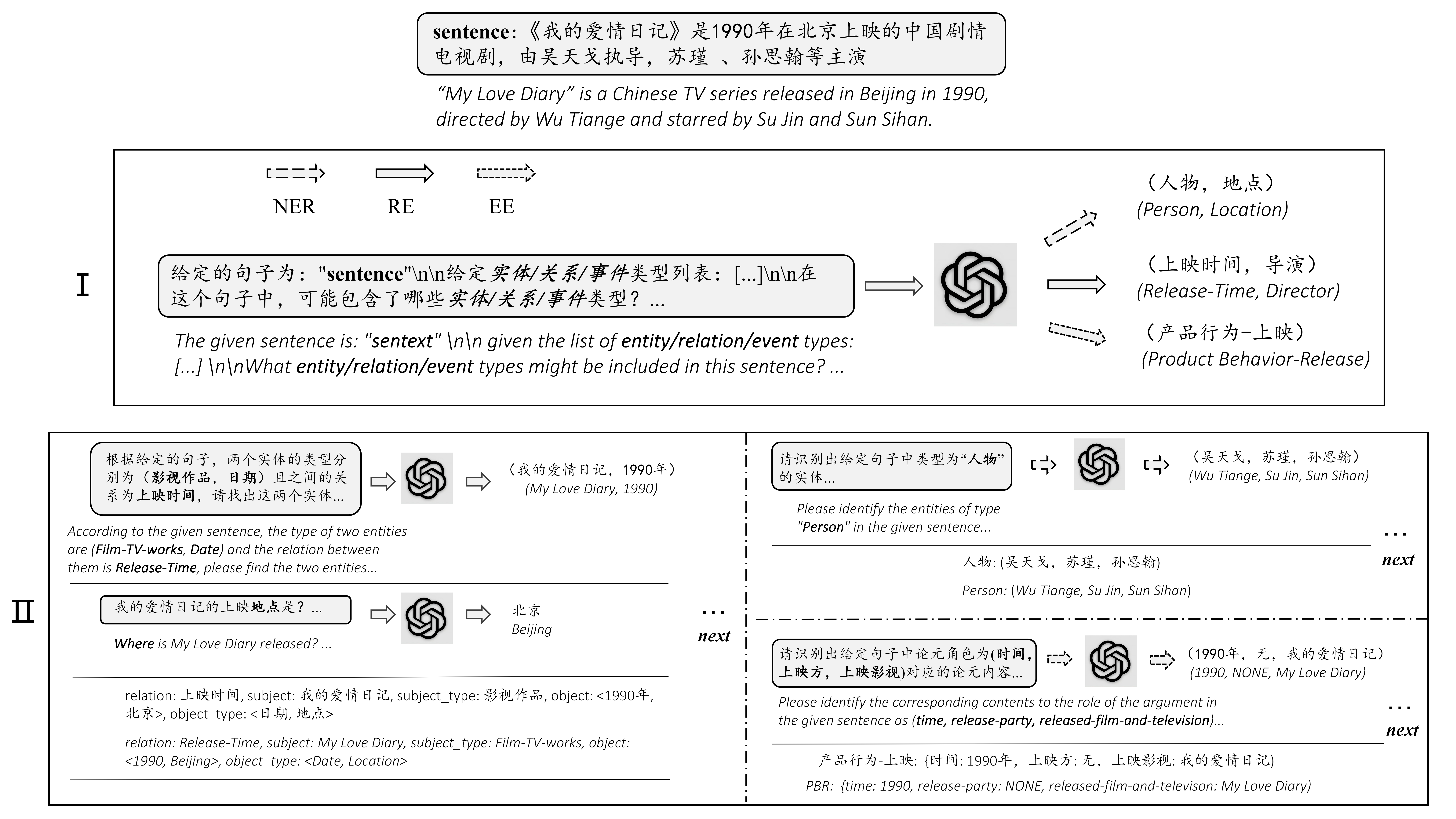
Chatie (extraction d'informations zéro-shot via la conversation avec Chatgpt) est une démo d'outils d'ouverture ouverte et puissante. Amélioré par Chatgpt et l'incitation, il vise à extraire automatiquement les informations structurées d'une phrase brute et à effectuer une analyse approfondie précieuse de la phrase d'entrée. L'évolution des informations structurées précieuses aide les entreprises à prendre des décisions incisives et commerciales. 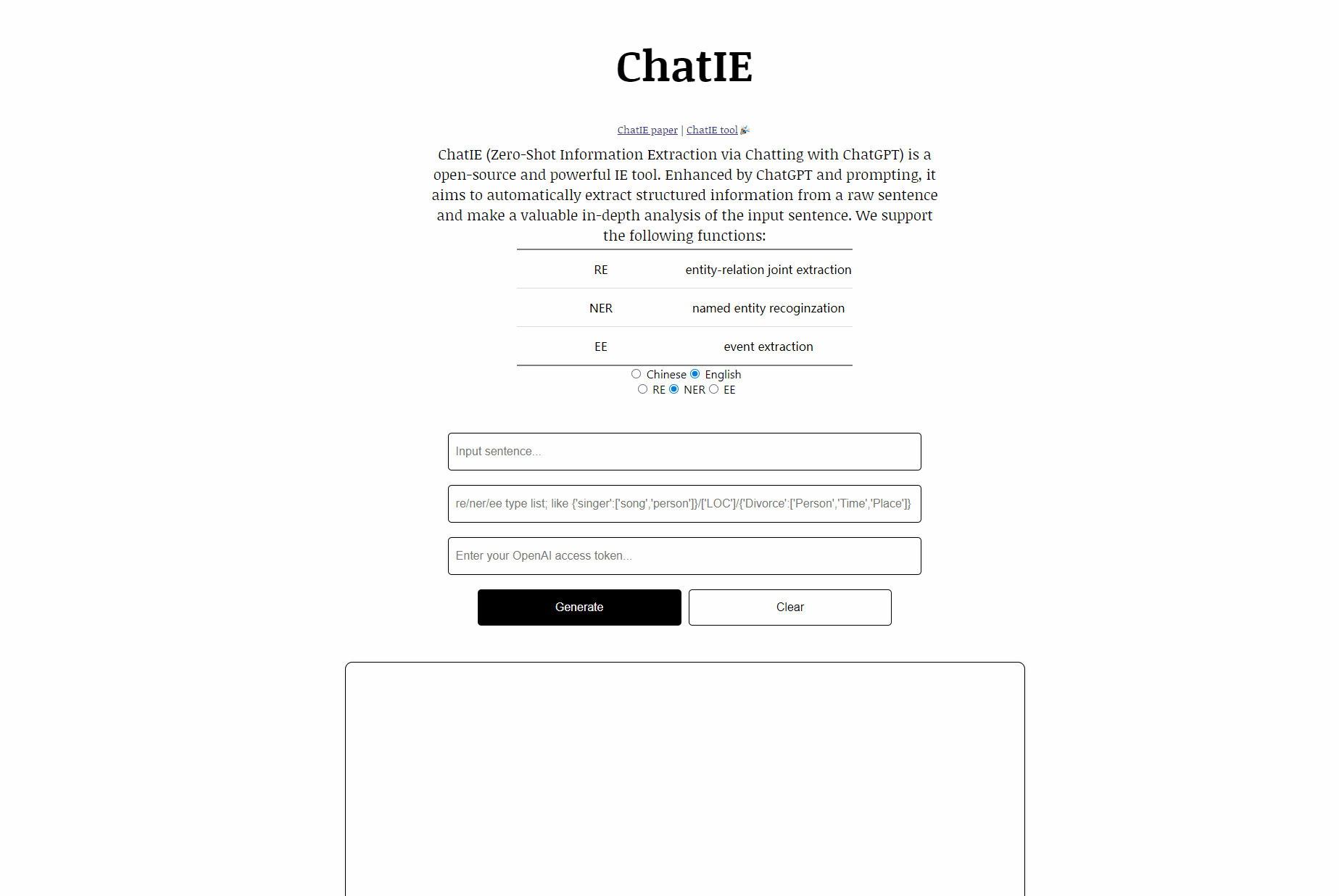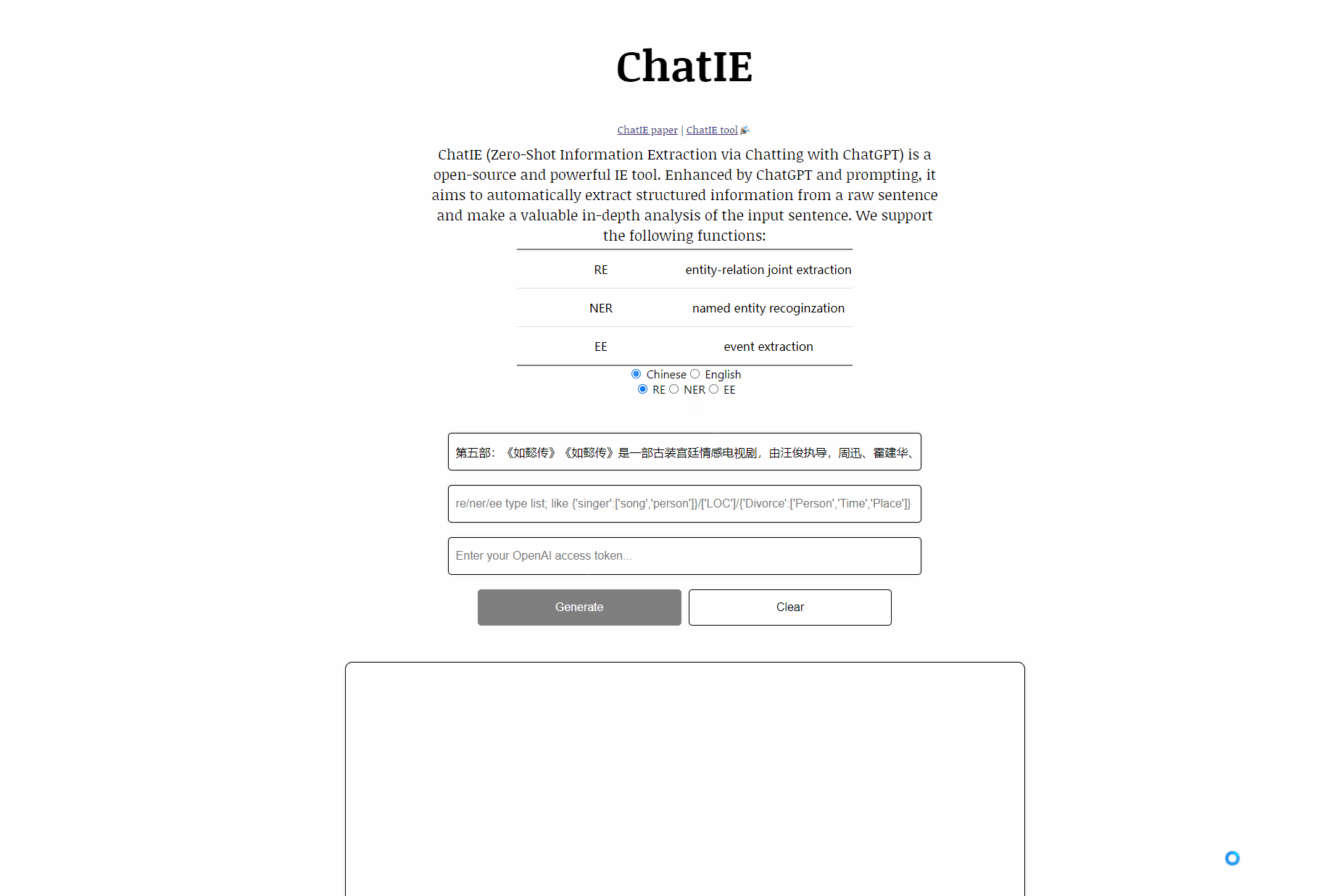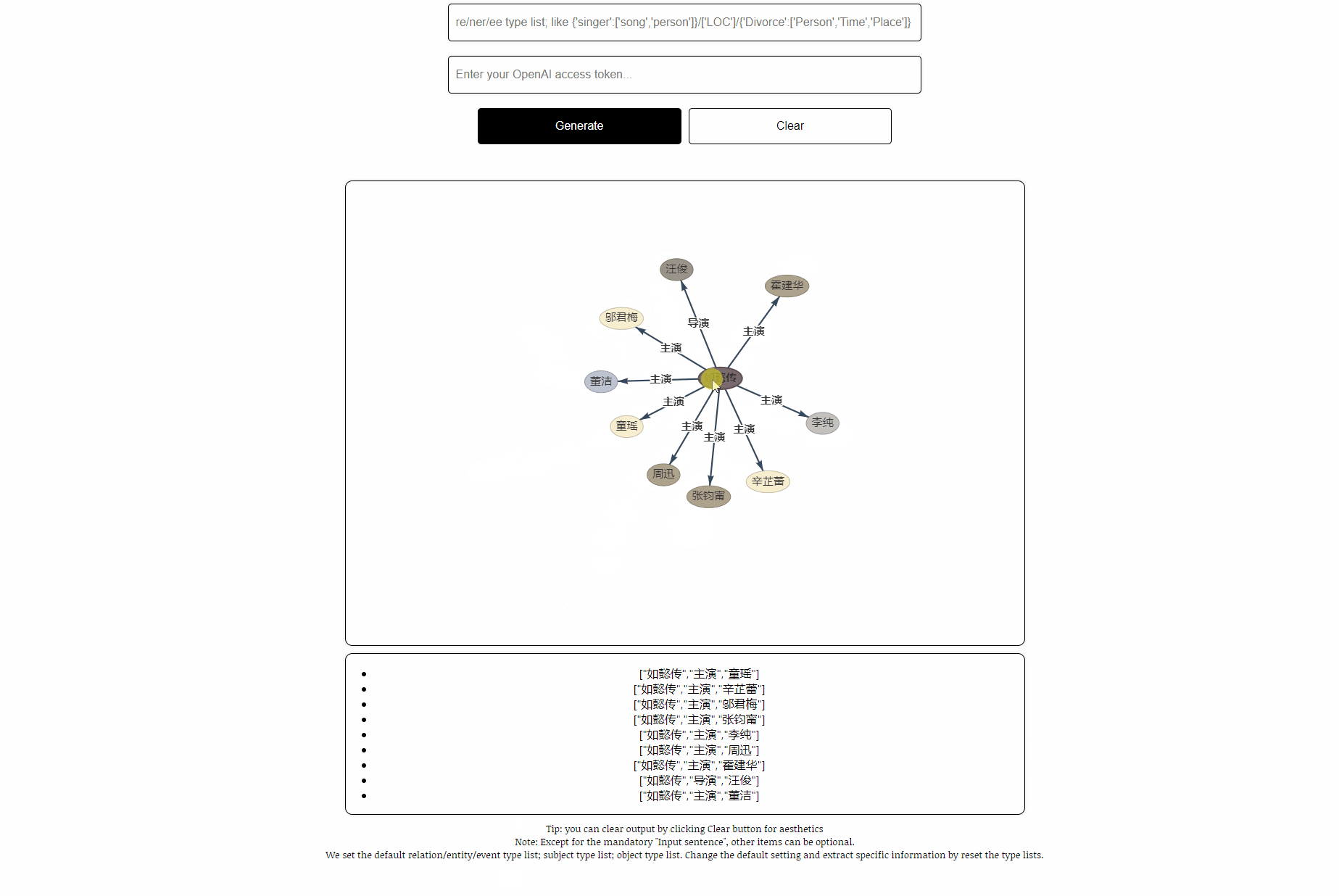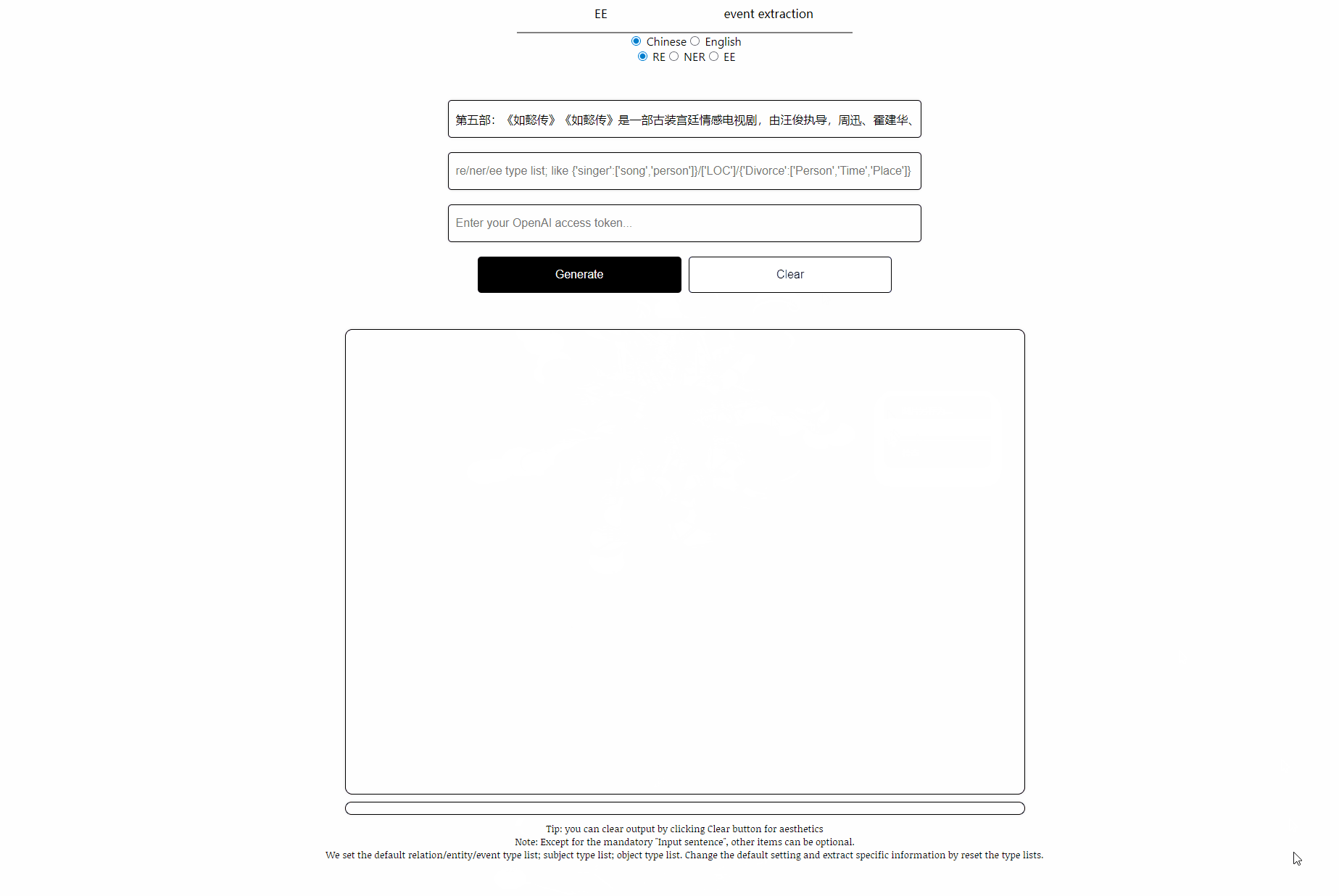
Nous prenons en charge les fonctions suivantes:
| Tâche | Nom | Dessiner |
|---|---|---|
| CONCERNANT | Extraction articulaire de relange d'entité | Chinois, anglais |
| Nervure | Recoginzation des entités nommées | Chinois, anglais |
| Ee | extraction d'événements | Chinois, anglais |
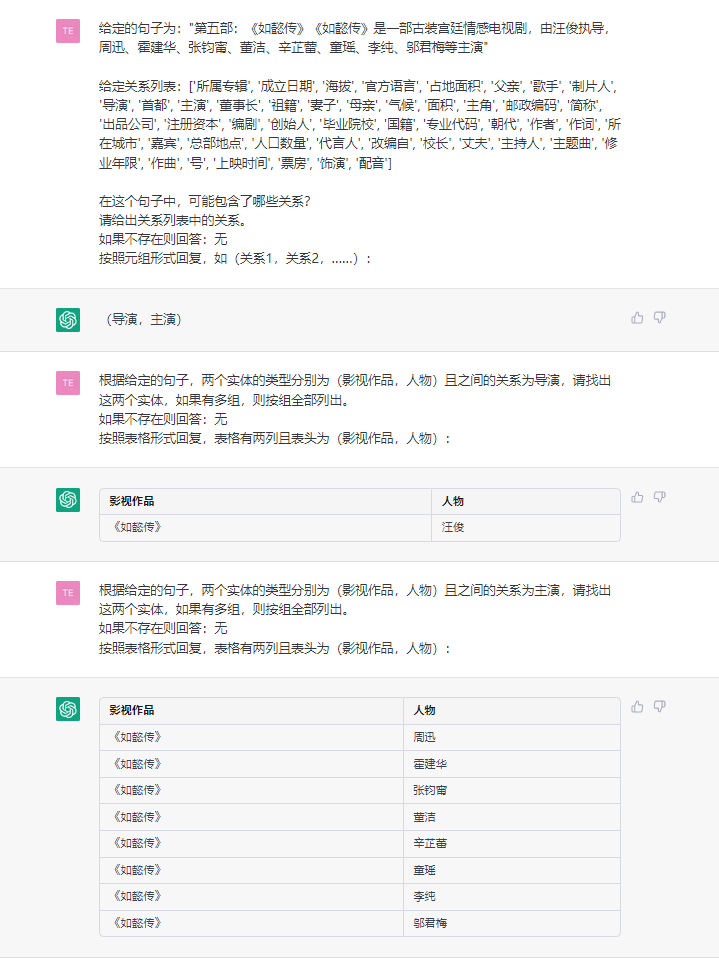
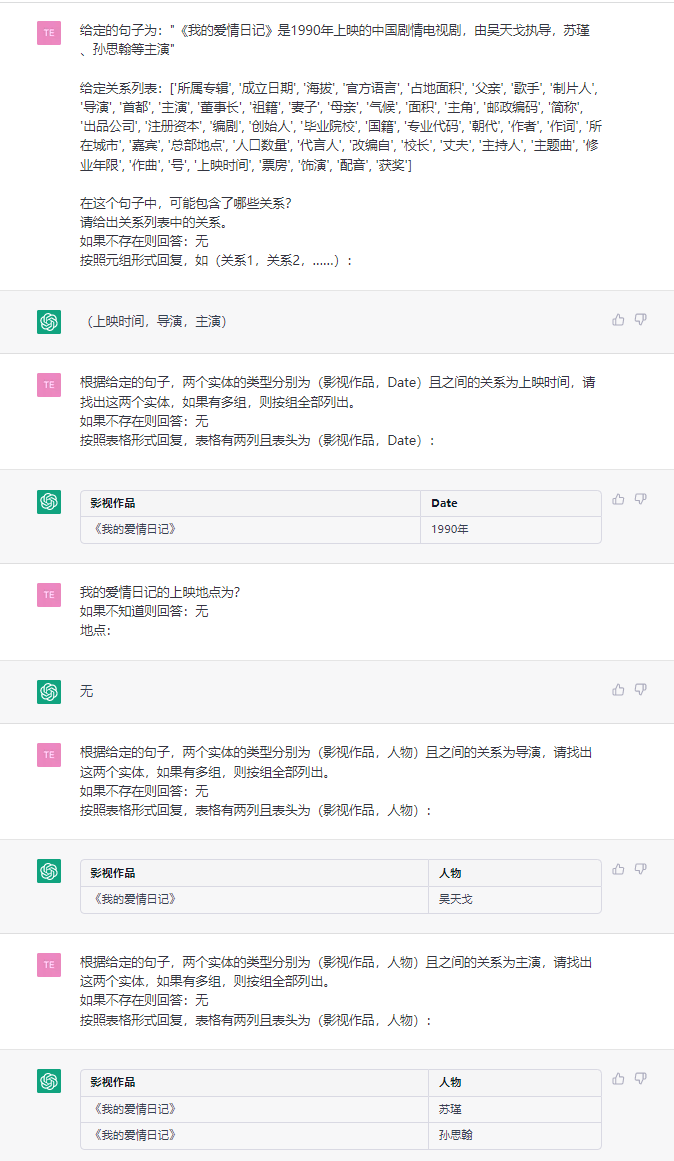
Cette tâche vise à extraire des triplets des textes brus, comme (Chine, capital, Pékin) , (《如懿传》, 主演, 周迅) .
PS: * DÉTENTION FACTIONNEL, nous définissons la valeur par défaut pour eux. Mais pour une meilleure extraction, vous devez spécifier la liste des trois selon les scénarios d'application.
Phrase: quatre autres dirigeants de Google le directeur financier, George Reyes; le vice-président principal des opérations commerciales, Shona Brown; le directeur juridique, David Drummond; Et le vice-président principal de la gestion des produits, Jonathan Rosenberg a gagné des salaires de 250 000 $ chacun.
RTL: par défaut, voir le fichier "Types par défaut"
OUPTUT: 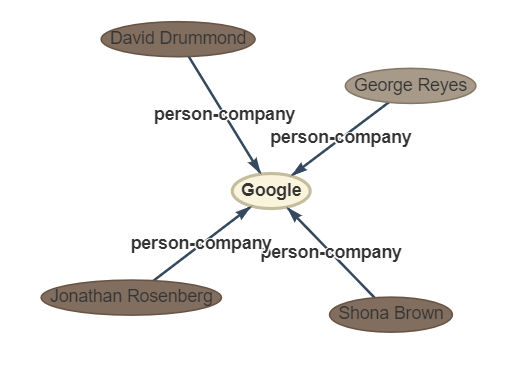
phrase:第五部 : 《如懿传》《如懿传》是一部古装宫廷情感电视剧 , 由汪俊执导 , 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。
RTL: par défaut, voir le fichier "Types par défaut"
OUPTUT: 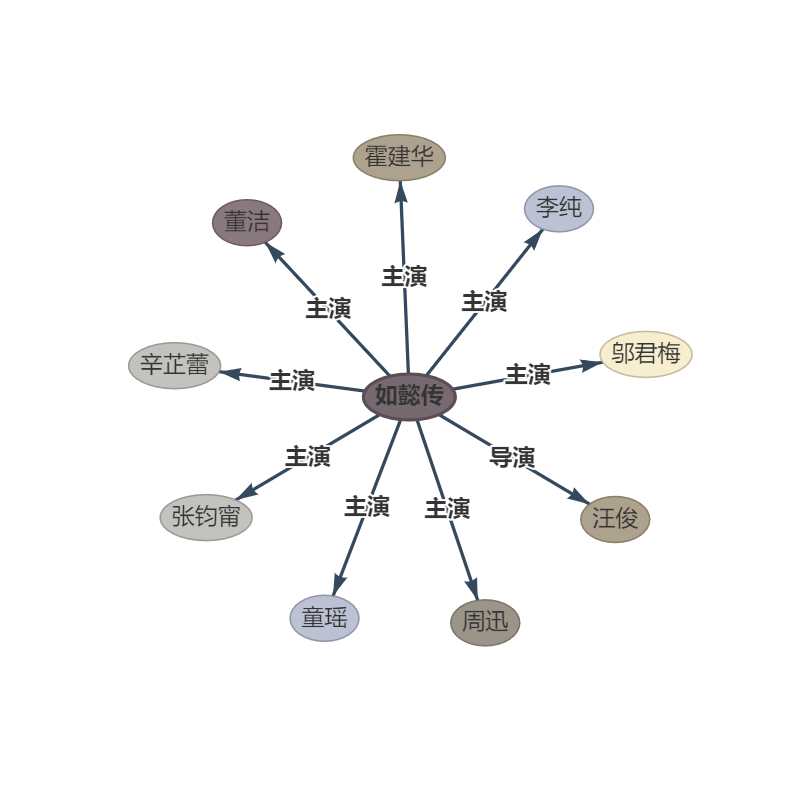
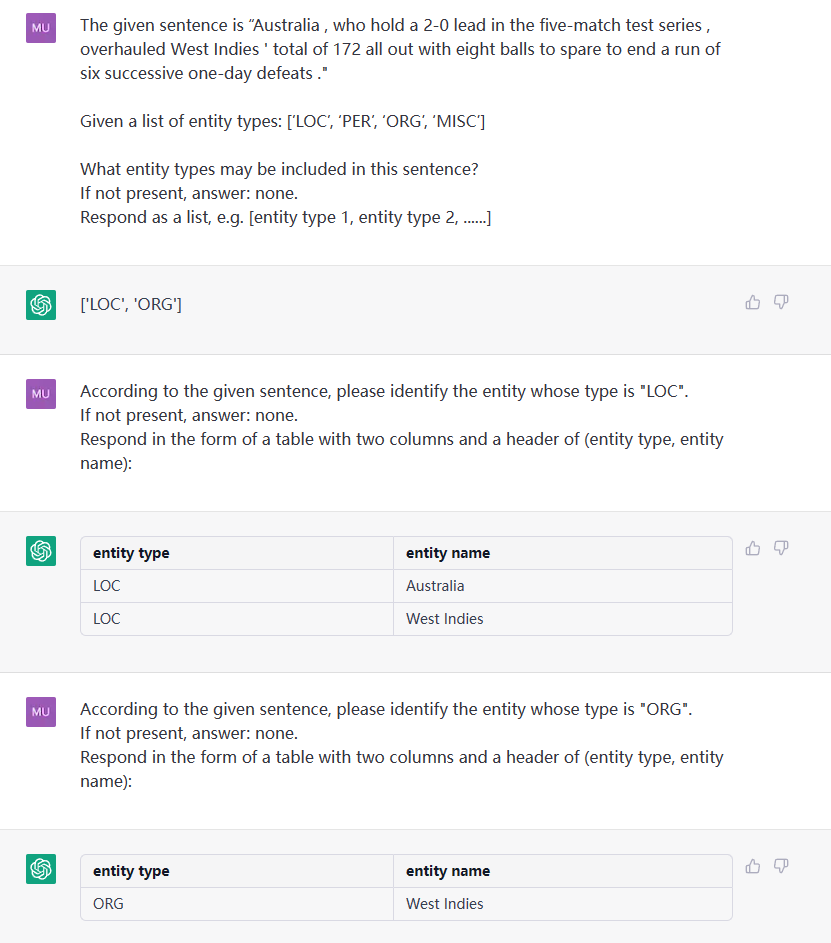
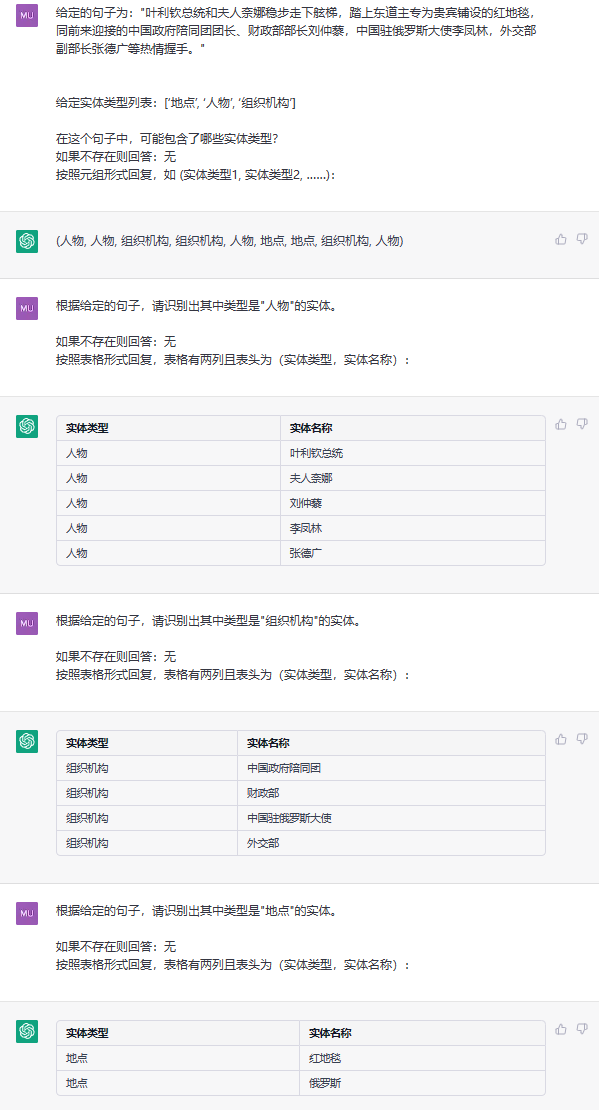
Cette tâche vise à extraire des entités de textes brutes, tels que (loc, beijing) , (人物, 周恩来) .
Phrase: James a travaillé pour Google à Pékin, la capitale de la Chine. ETL: [«loc», «disc», «org», «per»]
OUPTUT: 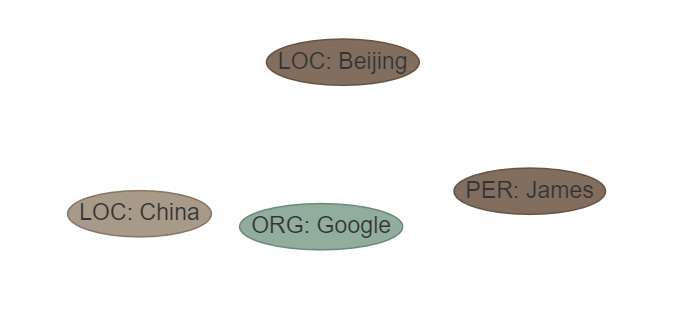
phrase:中国 产党创立于中华民国大陆时期产党创立于中华民国大陆时期 , 由陈独秀和李大钊领导组织。
ETL: ['组织机构', '地点', '人物']
OUPTUT: 
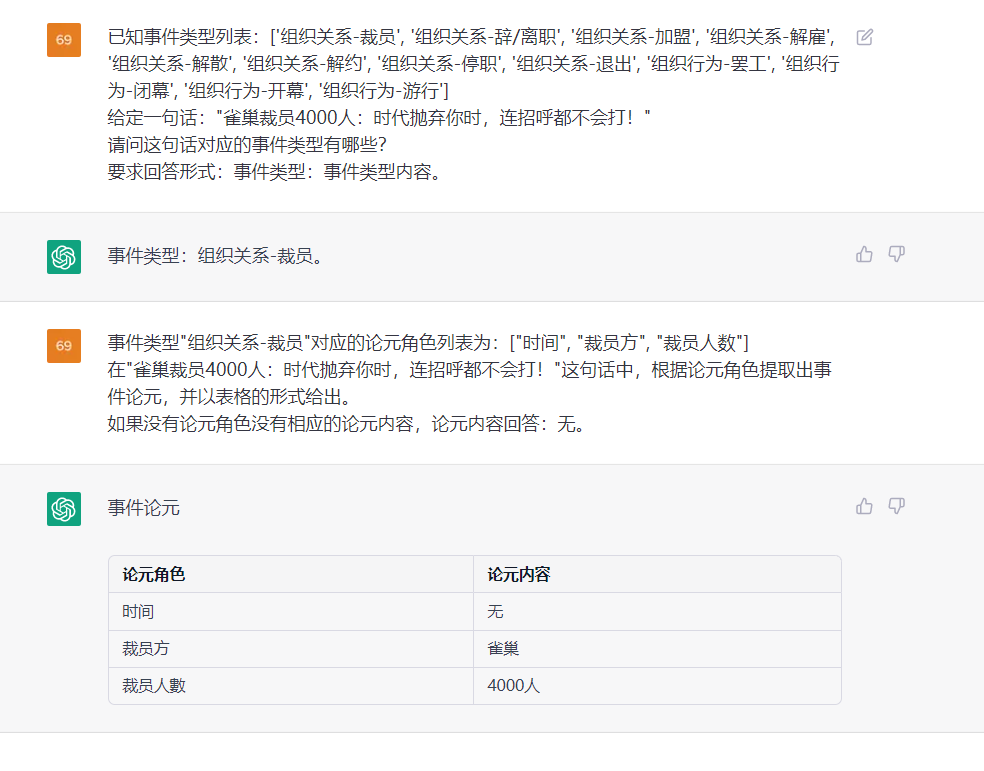
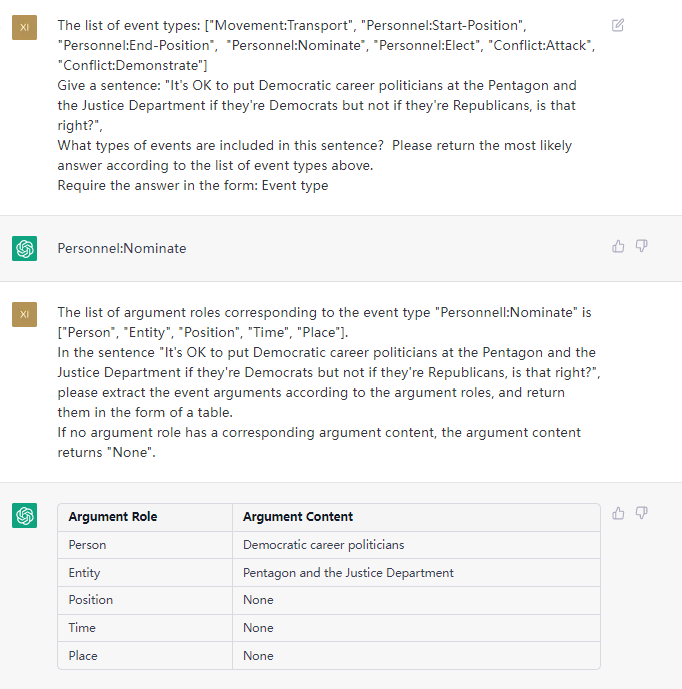
Cette tâche vise à extraire l'événement à partir de textes brusques, tels que {Life-Divorce: {Person: Bob, Time: Today, Place: America}}, {竞赛行为 - 晋级: {时间: 无, 晋级方: 西北狼, 晋级赛事: 中甲榜首之争}} .
Phrase: Hier, Bob et sa femme ont divorcé à Guangzhou.
ETL: par défaut, voir le fichier "Types par défaut"
OUPTUT: 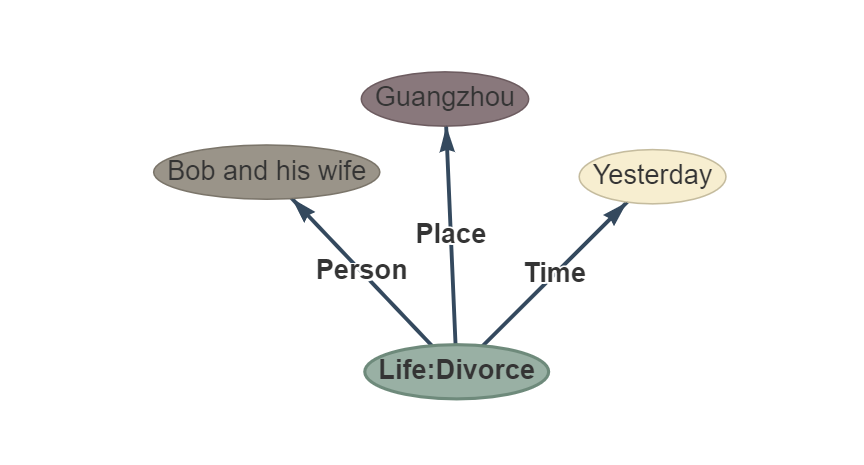
Phrase:在 2022 年卡塔尔世界杯决赛中 , 阿根廷以点球大战险胜法国。
ETL: par défaut, voir le fichier "Types par défaut"
OUPTUT: 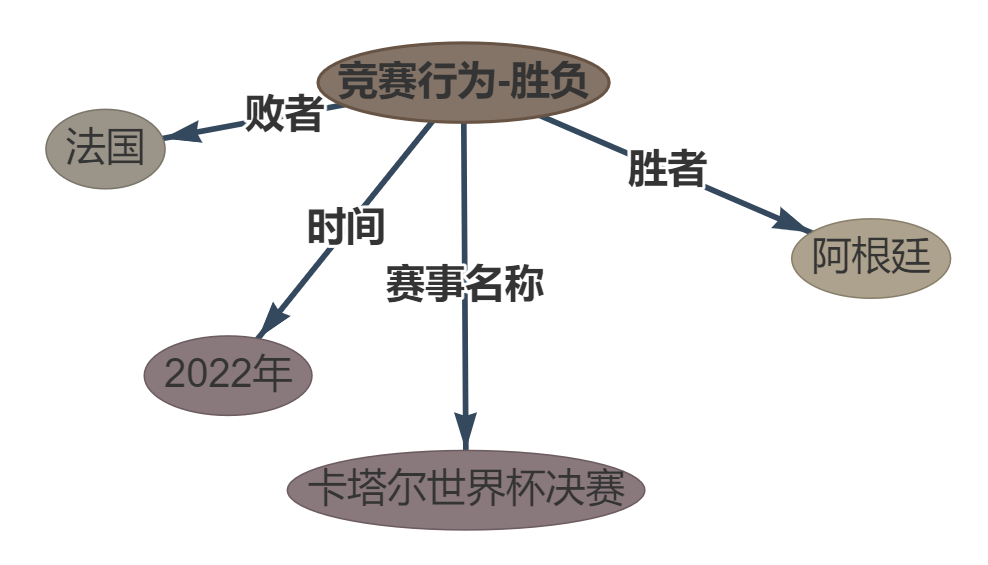
react + flacon
front-end et exécuter npm install pour télécharger les dépendances requises.npm run start . Chatie doit s'ouvrir dans un nouvel onglet de navigateur.back-end et exécuter python run.py
Nous nous engageons à améliorer notre projet et à vous offrir la meilleure expérience possible. Pour y parvenir, nous collecterons vos données pour nous aider à comprendre comment vous interagissez avec notre projet et identifier les domaines à améliorer. Nous apprécions la confidentialité et la sécurité de vos données et assurons les données uniquement dans le but d'améliorer notre projet.
Découvrez ce papier arxiv: 2302.10205
@article{wei2023zero,
title={Zero-Shot Information Extraction via Chatting with ChatGPT},
author={Wei, Xiang and Cui, Xingyu and Cheng, Ning and Wang, Xiaobin and Zhang, Xin and Huang, Shen and Xie, Pengjun and Xu, Jinan and Chen, Yufeng and Zhang, Meishan and others},
journal={arXiv preprint arXiv:2302.10205},
year={2023}
}


