Reading_groups
1.0.0
La puissance de l'informatique : de nombreuses preuves montrent que les progrès de l'apprentissage automatique sont largement motivés par l'informatique, et non la recherche, veuillez vous référer à "la leçon amère", et il y a souvent des phénomènes d'émergence et d'homogénéisation. Des études ont montré que l'utilisation de l'informatique de l'intelligence artificielle double environ 3,4 mois, tandis que l'amélioration de l'efficacité ne double que tous les 16 mois. Parmi eux, la quantité de calcul est principalement motivée par la puissance de calcul, tandis que l'efficacité est motivée par la recherche. Cela signifie que la croissance de l'informatique a historiquement dominé les progrès de l'apprentissage automatique et de ses sous-domaines. Ceci est en outre prouvé par l'émergence de GPT-4. Malgré cela, nous devons toujours faire attention à la question de savoir s'il y aura une architecture plus renversée à l'avenir, comme S4. La plupart des points chauds de recherche NLP actuels sont basés sur un LLM plus avancé (~ 100B,
Pour plus de sujets LLM, veuillez vous référer à ici et ici.
Documents ( catégorie approximative )
ressource
【Test sur GPT-4, Limitation】 Sparks of Artificiel General Intelligence: Early Experiments with GPT-4
【InstructGpt Papers, y compris SFT, PPO, etc., l'un des articles les plus importants】 Training Language Modèles pour suivre les instructions avec la rétroaction humaine
【OPPENSION SPORRABLE: Comment les humains peuvent-ils continuer à améliorer leurs modèles après que leurs modèles ont dépassé leurs propres tâches? 】 Mesurer les progrès sur la surveillance évolutive pour les modèles de grands langues
【Définition de l'alignement, produit par DeepMind】 Alignement des agents linguistiques
Un assistant de langue générale en tant que laboratoire d'alignement
[Papier rétro, modèle recherché à l'aide de CCA +] Amélioration des modèles de langage en récupérant des milliards de jetons
Modèles de langage affinés des préférences humaines
Former un assistant utile et inoffensif avec apprentissage du renforcement des commentaires humains
【Big Modèle en chinois et en anglais, dépassant le GPT-3】 GLM-130B: un modèle pré-formé bilingue ouvert
【Optimisation de la cible pré-formation】 UL2: paradigmes d'apprentissage des langues unificatrices
【Les nouveaux repères de l'alignement, les bibliothèques de modèles et les nouvelles méthodes】 L'apprentissage du renforcement est-il (pas) pour le traitement du langage naturel?
【MLM sans les étiquettes [de masque] à travers la technologie】 Débarcation de représentation dans la modélisation du langage masqué
【Le texte à l'image La formation soulage les besoins du vocabulaire et résiste à certaines attaques】 Modélisation du langage avec des pixels
Lexmae: lexique-bottlened pré-entraînement pour une récupération à grande échelle
Incodeur: un modèle génératif pour le remplissage de code et la synthèse
[Rechercher des images liées au texte pour le modèle de langue pré-formation] Modélisation du langage visuellement
Un modèle de langue auto-terminante non monotonique
【Comparaison et réglage fin de la rétroaction négative grâce à la conception propt】 Chaîne de recul aligne des modèles de langue avec la rétroaction
【Modèle du moineau】 Amélioration de l'alignement des agents de dialogue via des jugements humains ciblés
[Utilisez les petits paramètres du modèle pour accélérer le processus de formation du grand modèle (ne pas partir de zéro)] Apprendre à développer des modèles pré-entraînés pour une formation efficace au transformateur
[Modèle de fusion de connaissances semi-paramétriques pour les sources de connaissances multiples] Connaissances en contexte: vers des modèles de langage semi-paramétriques bien informé
[Méthode de fusion pour fusionner plusieurs modèles formés sur différents ensembles de données] La fusion de connaissances de données en fusionnant des poids de modèles de langue
[Il est très inspirant que le mécanisme de recherche remplace l'architecture générale de FFN dans le transformateur (× 2,54 temps) pour découpler les connaissances stockées dans les paramètres du modèle] Modèle de langue avec la mémoire du plug-in Knowldge
【Générez automatiquement les données de réglage des instructions pour la formation GPT-3】 Auto-instruction: Alignement Modèle de langue avec des instructions auto-générées
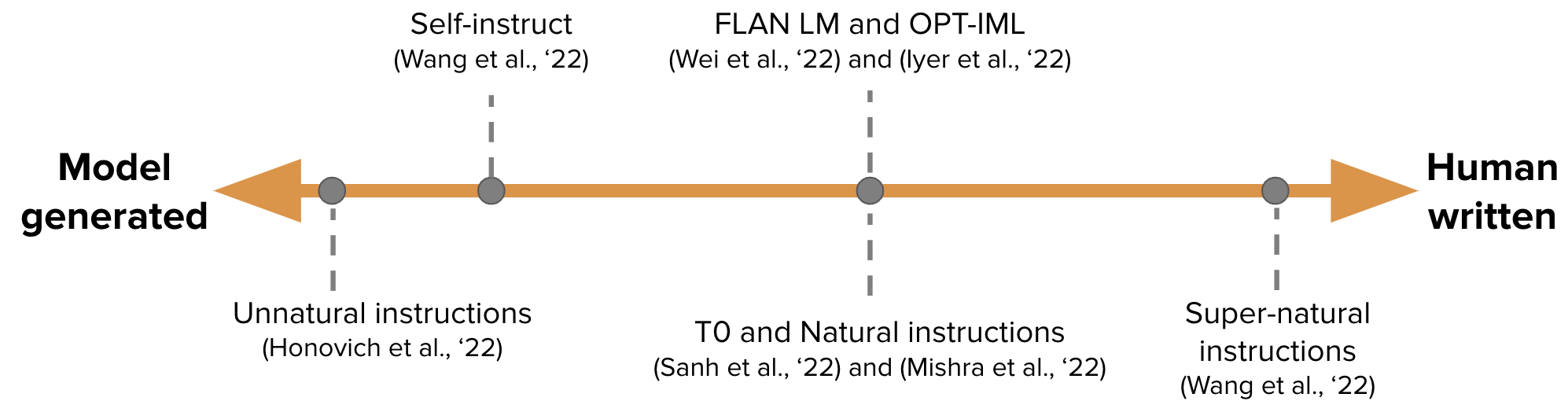
- 
Vers des modèles de langage masqué conditionnellement dépendants
【Calibré itérativement des correcteurs indépendants imparfaitement générés, l'article de suivi de Sean Welleck】 Génération de séquences en apprenant à se corriger
[Apprentissage continu: ajoutez une propt pour la nouvelle tâche, et la propt de la tâche précédente et le grand modèle restent inchangés] Invites progressives: apprentissage continu pour les modèles de langue sans oublier
[EMNLP 2022, mise à jour continue du modèle] MEMPROMPT: Édition rapide assistée par la mémoire avec commentaires des utilisateurs
【Nouvelle architecture neuronale (Folnet), qui contient un biais d'induction logique de premier ordre】 Les représentations de la langue d'apprentissage avec un biais inductif logique
GANLM: pré-formation de coder-décodeur avec un discriminateur auxiliaire
【Modèle de langage de pré-formation basé sur des modèles d'espace d'état, dépassant Bert】 Pre-Triping sans attention
[Considérez la rétroaction humaine pendant la pré-formation
[Meta's Open Source Llama Model, 7B-65B, entraîne plus de petits modèles étiquetés que d'habitude, réalisant des performances optimales dans divers budgets d'inférence] LLAMA: Modèles de base de base ouverts et efficaces
[Enseigner de grands modèles de langue à l'auto-plafonnement et expliquer le code généré à travers un petit nombre d'exemples, mais ils ont été utilisés comme celui-ci maintenant] Enseignant des modèles de grande langue à l'auto-lebug
Jusqu'où les chameaux peuvent-ils aller?
Lima: moins c'est plus pour l'alignement
【Arbre de pensée, de plus en plus comme l'alphago】 Résolution de problèmes délibérés avec des modèles de grands langues
【Méthode de raisonnement en plusieurs étapes pour l'application de l'ICL est très inspirante】 REACT: Synergisant le raisonnement et le jeu dans les modèles de langues
【Le COT génère directement le code du programme, puis permet à l'interprète de Python d'exécuter】 Programme de pensées Invitation: démontage du calcul du raisonnement pour les tâches de raisonnement numérique
[Le grand modèle génère directement le contexte des preuves] Générer plutôt que de récupérer: les modèles de grandes langues sont des générateurs de contexte solides
【Modèle d'écriture avec 4 opérations spécifiques】 Peer: un modèle de langue collaborative
【Combinaison de python, d'exécuteurs SQL et de grands modèles】 Modèles de langage de liaison dans les langues symboliques
[Récupérer le code de génération de documents] DOCPROMPING: Génération de code en récupérant les documents
[Il y aura de nombreux articles dans la mise à la terre + LLM dans la série suivante] LLM-Planner: Planification fondée sur quelques coups pour les agents incarnés avec de grands modèles de langue
【Génération d'auto-it itective (vérifiée à l'aide de Python) Données de formation】 Les modèles de langue peuvent s'apprendre à mieux programmer
Articles connexes: des modèles de langue plus petits spécialisés vers un raisonnement en plusieurs étapes
Star: Raisonnement de bootstrap avec le raisonnement, à partir de Neirips 22 (générer des données de COT pour un réglage fin du modèle), provoquant une série d'articles de COT enseignant de petits modèles.
Idées similaires [Distillation des connaissances] Enseignant des modèles de petits langues à la raison et à l'apprentissage par un contexte de distillation
Idées similaires Les groupes Kaist et Xiang Ren ([la justification du COT a fini (professeur)] Pinto: raisonnement fidèle en matière de langue à l'aide de rationnelles générées par une invidence, etc.) et les modèles de gros langues sont les enseignants des enseignants
Les modèles de décomposition du problème et de résolution de problèmes d'ETH [les modèles de résolution de problèmes] distillent les capacités de raisonnement en plusieurs étapes des modèles de grands langues en modèles plus petits via des décompositions sémantiques
【Laissez les petits modèles apprendre les capacités du COT】 Distillation d'apprentissage en contexte: transfert de la capacité d'apprentissage à quelques coup
【Le grand modèle enseigne au petit modèle COT】 Les modèles de grandes langues sont des enseignants de raisonnement
[Big Model génère des preuves (récitation) puis effectue un petit échantillon de questions et de réponse à un livre fermé] Modèles de langage à la récitation
[Méthodes de langage naturel des raisonneurs inductifs] Modèles de langue comme des raisons inductives
[GPT-3 est utilisé pour l'annotation des données (comme la classification émotionnelle)] GPT-3 est-il un bon annotateur de données?
【Modèles d'augmentation des données basés sur une formation multitâche pour moins d'échantillonnage d'augmentation des données】 Knowda: modèle de mélange de connaissances tout-en-un pour l'augmentation des données dans la PNL à faible ressource
【Travail de planification procédurale, pas intéressé par le temps étant】 Planification procédurale neuro-symbolique avec invitation de bon sens
[Objectif: générer des articles factuellement corrects pour les requêtes en mise à la terre sur un grand corpus Web
【Combinant les résultats du simulateur de physique externe dans le contexte】 Mind's Eye: Modèle de langage fondé Raisonnement à travers la simulation
[Récupérer la tâche d'améliorer le COT pour faire des connaissances à forte intensité de connaissances] La récupération entrelacée avec le raisonnement de la chaîne de pensées pour les questions en plusieurs étapes à forte intensité de connaissances
【Contraste les connaissances potentielles (binaires) dans le modèle de langage de reconnaissance non supervisé】 Découvrir les connaissances latentes dans les modèles de langues sans supervision
[Percy Liang Group, Engine de recherche de confiance, seulement 51,5% des phrases générées sont entièrement prises en charge par les citations] Évaluation de la vérifiabilité dans les moteurs de recherche génératifs
L'incitation progressive améliore le raisonnement dans les modèles de grande langue
Auto-alignement axé sur les principes des modèles de langue à partir de zéro avec une supervision humaine minimale
Juger LLM-AS-A-JUDUS avec MT-Bench et Chatbot Arena
[À mon avis, c'est l'un des articles les plus importants. Formation, et la largeur et la profondeur des détails de l'architecture tels que la largeur et la profondeur.
[L'un des autres articles les plus importants, Chinchilla, sous un calcul limité, le modèle optimal n'est pas le plus grand modèle, mais un modèle plus petit formé avec plus de données (60-70b)] Formation de modèles de grande langue Compute-optimal
[Quels objectifs d'architecture et d'optimisation aident la généralisation de l'échantillon zéro] Quelle architecture de modèle de langue et la pré-formation d'objectif fonctionnent mieux pour la généralisation zéro-shot?
【Mémorisation du processus d'apprentissage «Epiphanie»
[Étudiez les caractéristiques du modèle basé sur la recherche et constatez que les deux sont du raisonnement limité] Les modèles de langues peuvent être réinstallés?
[Cadre d'évaluation de l'interaction humaine-AI] Évaluation de l'interaction du modèle en langue humaine
Quel algorithme d'apprentissage est un apprentissage en contexte?
【Modification du modèle, c'est un sujet brûlant】 Mémoire d'édition de masse dans un transformateur
[La sensibilité du modèle à un contexte non pertinent, en ajoutant des informations non pertinentes aux exemples de l'invite et en ajoutant des instructions qui ignorent le contexte non pertinent partiellement] les modèles de langage de gros peuvent être facilement distraits par un contexte non pertinent
【Le lit zéro-shot montrera les biais et la toxicité sous des problèmes sensibles】 sur la deuxième réflexion, ne réfléchissons pas à l'étape par étape!
【Le COT du grand modèle a des capacités inter-langues】 Les modèles de langue sont des raisons multilingues de la chaîne de pensées
[Plus la confusion de différentes séquences rapides, meilleur est la performance] démystifier les invites dans les modèles de langues via l'estimation de la perplexité
[Tâche de résolution de l'implicité binaire des grands modèles, cette suggestion est difficile et il n'y a pas de phénomène de mise à l'échelle] Les modèles de langage grands ne sont pas des communicateurs zéro shot (https://github.com/google/big-bench/tree/main/bigbench/ benchmark_tasks / implicitement)
【Invitation basée sur la complexité pour le raisonnement en plusieurs étapes
Qu'est-ce qui compte dans l'élagage structuré des modèles de langage génératifs?
[Ambibench DataSet, Tâche Ambiguïté: le modèle RLHF de mise à l'échelle fonctionne mieux dans les tâches désambigantes. Le réglage fin est plus utile que l'incitation à quelques coups】 l'ambiguïté de la tâche chez l'homme et les modèles de langue
【Test GPT-3, y compris la mémoire, l'étalonnage, les biais, etc.】 inciter GPT-3 à être fiable
[Étude de l'OSU qui partie du COT est efficace pour la performance] vers la compréhension de l'incitation à la chaîne de réflexion: une étude empirique de ce qui compte
[La recherche sur le modèle inter-langage d'invites discrètes] Les invites d'extraction d'informations discrètes peuvent-elles généraliser entre les modèles de langue?
【Le taux de mémoire est une relation linéaire logarithmique avec la taille du modèle, la longueur du préfixe et le taux de répétition en formation】 Quantification de la mémorisation à travers les modèles de langage neuronal
【C'est très inspirant, décomposez le problème en sous-questions par l'itération GPT et répondez-y】 mesurer et rétrécir l'écart de compositionnalité dans les modèles de langue
[Test analogue de GPT-3 similaire aux questions de renseignement des fonctionnaires] Raisonnement analogique émergent dans les modèles de grande langue
【Formation en texte court, test de texte long, évaluation de l'adaptabilité de la longueur variable du modèle】 Un transformateur à exctrapolation de longueur
[Quand ne pas faire confiance aux modèles de langue: étudier l'efficacité et les limites des souvenirs paramétriques et non paramétriques
【ICL est une autre forme de mise à jour de gradient】 Pourquoi GPT peut-il apprendre en contexte?
GPT-3 est-il un psychopathe?
[Recherche sur le processus de formation du modèle OPT en différentes tailles et a constaté que la confusion est un indicateur de la formation de la formation des modèles de langage ICL à travers les échelles
[EMNLP 2022, le corpus d'anglais pur pré-formé contient d'autres langues, et les capacités inter-langues du modèle peuvent provenir de la fuite de données] La contamination par la langue aide les capacités interdicules des modèles anglais prétraités anglais
[Les prieurs sémantiques remplacés et l'utilisation d'informations dans Propt sont une capacité de surtension] Les modèles de langage plus grands font l'apprentissage en contexte différemment
【Résultats EMNLP 2022】 Quel modèle de langue s'entraîner si vous avez un million d'heures de GPU?
[L'introduction de la technologie CFG pendant le raisonnement améliore considérablement la capacité de conformité des instructions des petits modèles] Restez sur le sujet avec des conseils sans classificateur
【Formez votre propre modèle de lama avec le GPT-4 d'Openai, et je peux seulement dire que je vous admire】 CONSTRUCTION D'INSTRUCTION AVEC GPT-4
Réflexion: un agent autonome avec mémoire dynamique et auto-réflexion
【Apprentissage par un style personnalisé, opt】 invites extensibles pour les modèles de langue
[Accélérer un grand décodage de modèles, en utilisant le consensus direct entre les petits modèles et les grands modèles à utiliser plusieurs fois à la fois, après tout, l'entrée sera très lente si elle est longue] Accélérant le décodage de modèle de grande langue avec un échantillonnage spécialisé
[Utilisez une invite souple pour réduire la baisse de la capacité ICL causée par un réglage fin, le réglage fin de la première étape, le réglage fin de la deuxième étape] Préservant la capacité d'apprentissage dans le contexte dans le modèle de grande langue
【Tâches d'analyse sémantique, méthodes de sélection des échantillons d'ICL, Codex et T5-Large】 diverses démonstrations améliorent la généralisation de la composition dans le contexte
【Une nouvelle méthode d'optimisation pour la génération de texte】 Adapter les modèles de génération de langage sous distance de variation totale
[Estimation de l'incertitude de la génération conditionnelle, en utilisant un regroupement sémantique combiné avec de multiples sorties d'échantillonnage pour estimer l'entropie des grappes] Incertitude sémantique: invariances linguistiques pour l'estimation de l'incertitude dans la génération du langage naturel
Go-Tuning: Amélioration des capacités d'apprentissage zéro des modèles de langue plus petits
【Méthode de génération de texte très inspirante sous contraintes de texte libre】 Génération de texte contrôlable avec contraintes de langue
[Lorsque vous générez des prédictions, utilisez la similitude pour sélectionner une phrase au lieu du jeton Softmax] Modélisation du langage masqué non paramétrique
[Méthode ICL pour le texte long] Contexte parallèle Les fenêtres améliorent l'apprentissage en contexte des modèles de langue importants
【Échantillon de modèle instructgpt générant ICL par lui-même】 Modèles de grande langue auto-répartis pour un QA à domaine ouvert
【Les mécanismes de transfert et d'attention permettent à ICL de saisir plus d'échantillons d'annotation】 Invitation structurée: mise à l'échelle d'apprentissage en contexte à 1 000 exemples
Étalonnage de momentum pour la génération de texte
【Deux méthodes de sélection des échantillons ICL, expériences basées sur OPT et GPTJ】 Curration minutieuse des données stabilise l'apprentissage dans le contexte
【Analyse des indicateurs d'évaluation de Mauve (Pillutla et al.)】 Sur l'utilité des intérêts, des grappes et des chaînes pour l'évaluation de la génération de texte
Insidegator: récupération dense à quelques coups de 8 exemples
[Trois Cobblers, Zhuge Liang] L'auto-cohérence améliore le raisonnement de la chaîne de pensée dans les modèles de langues
[Invertissant, entrée et étiquette générer des instructions pour les conditions] Devinez l'instruction!
【Vérification d'auto-vérification de la dérivation inverse de LLM】 Les modèles de langues importants sont des raisons avec l'auto-vérification
【Méthodes de recherche - Scénarios de sécurité dans le cadre du processus de génération de preuves】 Foveate, attribut et rationaliser: vers une IA sûre et digne de confiance
[Estimation de la confiance des fragments extraits par des informations générées par le texte basées sur la recherche de faisceau] Comment la recherche de faisceau améliore-t-elle l'estimation de confiance au niveau de la portée dans le marquage de séquences génératifs?
SPT: réglage rapide semi-paramétrique pour l'apprentissage invité à plusieurs tâches
【Une discussion sur l'étiquette d'or résumé extrait】 Résumé du texte avec attente oracle
【Méthode de détection OOD basée sur la distance martienne】 Détection hors distribution et génération sélective pour les modèles de langage conditionnel
[Le module d'attention intègre l'invite pour prédire le niveau d'échantillonnage] Ensemble modèle au lieu d'une fusion rapide: une méthode de transfert de connaissances spécifique à l'échantillon pour un réglage invite à quelques coups
【Prompt pour plusieurs tâches par décomposition et distillation en une seule invite】 Le réglage invite multitâche permet un apprentissage transfert par les paramètres
[Les indicateurs d'évaluation du raisonnement étape par étape peuvent être utilisés comme sujet à partager la prochaine fois] Roscoe: une suite de mesures pour marquer un raisonnement étape par étape
[La vraisemblance de la séquence d'étalonnage améliore la génération de langage conditionnel]
【Méthode d'attaque de texte basée sur l'optimisation du gradient】 Textra: progression de l'évaluation de la robustesse dans la PNL par optimisation axée sur le gradient
[GMM Modélisation des limites de classification de décision ICL pour calibrer] Calibration prototypique pour l'apprentissage à quelques coups de modèles de langue
【Problème de réécriture et méthode d'agrégation ICL basée sur les graphiques】 Demandez-moi n'importe quoi: une stratégie simple pour inciter les modèles de langage
[Base de données pour sélectionner de bons candidats comme ICLS à partir d'exemples non-annotés] Annotation sélective rend les modèles de langage meilleurs apprenants à quelques tirs
PromptBoosting: Classification de texte de la boîte noire avec dix passes avant
Attaques de dérobée à l'attention contre les transformateurs
【Position rapide du masque Sélection d'étiquette automatique】 Les modèles de langage pré-formé peuvent être des apprenants entièrement zéro
[Compresser la longueur du vecteur d'entrée FID et le réorganiser lors de la sortie du classement des documents de sortie] FID-LIGHT: Génération de texte efficace et efficace
【Explication sur la génération de grands modèles】 Pinto: raisonnement fidèle de la langue à l'aide de rationnelles générées par invité
【Trouvez un sous-ensemble d'impacts avant la formation】 Orca: interpréter les modèles de langage invité via la localisation de preuves à l'appui dans l'océan de données de prélèvement
[Projet rapide, destiné à l'enseignement, génère le filtrage de tri et à deux étapes] Les modèles de langues importants sont des ingénieurs rapides au niveau de l'homme
Connaissances désapprentissage pour atténuer les risques de confidentialité dans les modèles de langue
Modification des modèles avec arithmétique de la tâche
[Ne saisissez pas les instructions et les échantillons à chaque fois, convertissez-les en modules économes par des paramètres,] Astuce: réglage des instructions hypernet pour une généralisation de zéro efficace
[Méthode de génération d'affichage ICL sans sélection d'échantillons manuelle] Z-ICL: apprentissage zero-shot en contexte avec des pseudo-démonstrations
[L'instruction de la tâche et le texte génèrent l'intégration ensemble] Un intégration, toute tâche: Instruction-Finetuned Text incorporeddings
【GRAND MODÈLE ENSEIGNEMENT SMEUX MODÈLE COT】 Couteau: Distillation des connaissances avec des justifications de texte libre
[Problème d'incohérence entre la source et la segmentation des mots cibles du modèle de génération d'extraction d'informations] La cohérence de la tokenisation Matters pour les modèles génératifs sur les tâches NLP extractives
PARLE: Un cadre de langue naturelle unifiée pour le raisonnement algorithmique
[Sélection de l'échantillon ICL, sélection de première phase et tri de deuxième phase] Apprentissage auto-adaptatif dans le contexte
[Lecture intensive, méthode de sélection invite non supervisée, GPT-2] vers un réglage invite lisible par l'homme: The Shining's est un bon film de Kubrick, et une bonne invite aussi
【Tests de données de données prontoqa Tests CAPILLE CABLE CONSÉRER et constate que la capacité de planification est encore limitée】 Les modèles de langage peuvent (un type de) raison: une analyse formelle systématique de la chaîne de pensée
【Reason Dataset】 Wikiwhy: Répondre et expliquer les questions de cause à effet
【Raisonnement Dataset】 Street: Un raisonnement structuré et des explications multi-tâches de référence
【Ensemble de données de raisonnement, comparaison de pré-formation et de réglage fin de l'OPT, y compris les modèles de réglage fin du COT】 Alerte: adaptation des modèles de langage aux tâches de raisonnement
[Résumé du raisonnement récent par l'équipe de Zhang Ningyu de l'Université du Zhejiang] Raisonnement avec modèle de langue Invitation: une enquête
[Résumé de la technologie de la génération de texte et de la direction par l'équipe de Xiao Yanghua à Fudan] Exploiter les connaissances et le raisonnement pour la génération de langage naturel de type humain: une brève revue
[Résumé des articles de raisonnement récent, Jie Huang de l'UIUC] vers le raisonnement dans les modèles de grande langue: une enquête
【Examen des tâches, des ensembles de données et des méthodes de raisonnement mathématique et DL】 Une enquête sur l'apprentissage en profondeur pour le raisonnement mathématique
Une enquête sur le traitement du langage naturel pour la programmation
Ensemble de données de modélisation de récompense:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


