IncarnaMind
1.0.0
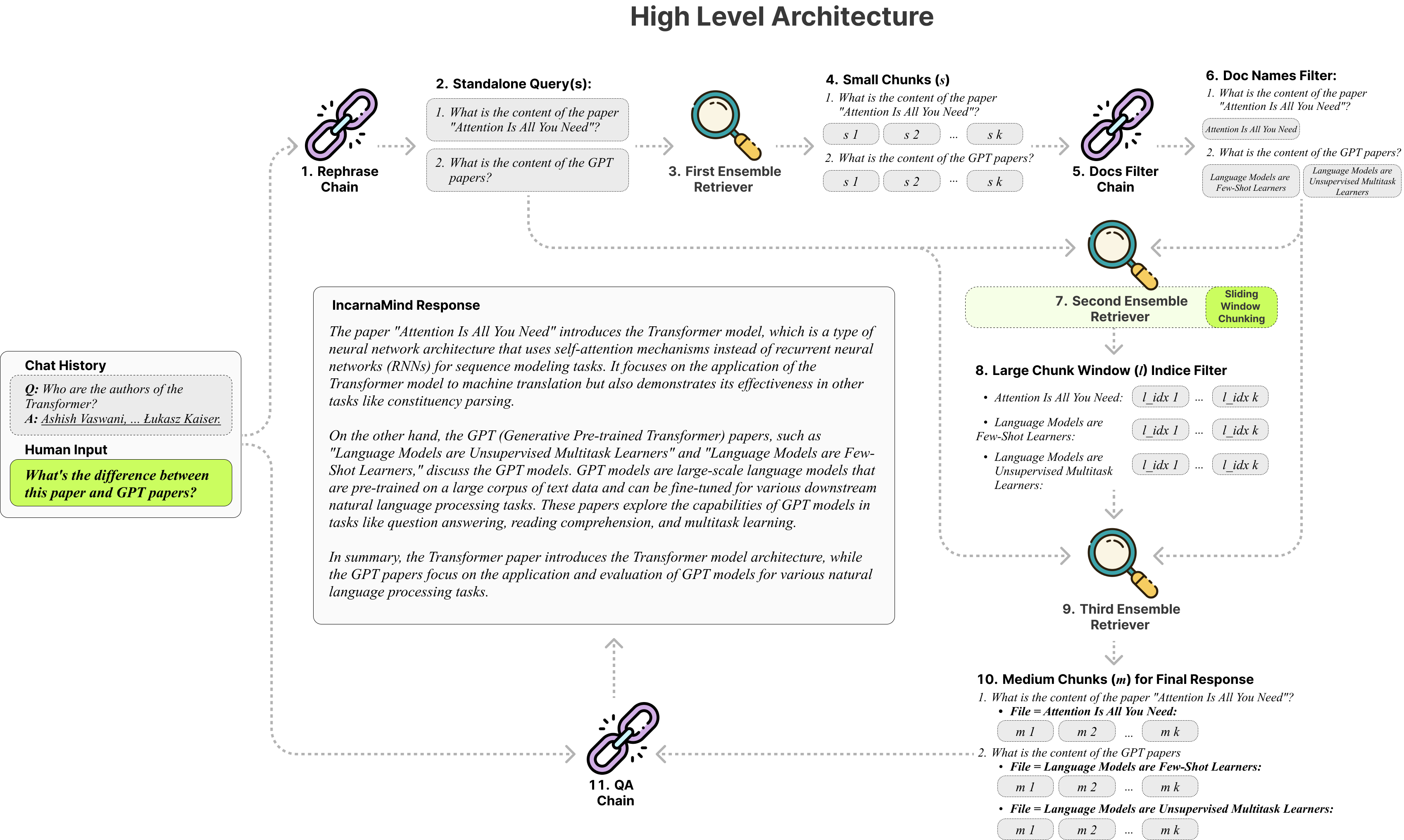
Incarnamind vous permet de discuter avec vos documents personnels? (PDF, TXT) Utilisation de modèles de grande langue (LLMS) comme GPT (Présentation de l'architecture). Alors qu'Openai a récemment lancé une API à réglage fin pour les modèles GPT, il ne permet pas aux modèles de base pré-entraînés d'apprendre de nouvelles données, et les réponses peuvent être sujettes aux hallucinations factuelles. Utilisez notre mécanisme de chasse à la fenêtre coulissante et notre récupération d'ensemble permet une interrogation efficace des informations à grains fins et à grains grossiers dans vos documents de vérité sur le terrain pour augmenter les LLM.
N'hésitez pas à l'utiliser et nous nous félicitons de commentaires et de nouvelles suggestions de fonctionnalités ?.
Voici un tableau de comparaison des différents modèles que j'ai testés, pour référence uniquement:
| Métrique | Gpt-4 | GPT-3.5 | Claude 2.0 | LLAMA2-70B | Llama2-70b-ganguf | LLAMA2-70B-API |
|---|---|---|---|---|---|---|
| Raisonnement | Haut | Moyen | Haut | Moyen | Moyen | Moyen |
| Vitesse | Moyen | Haut | Moyen | Très bas | Faible | Moyen |
| RAM GPU | N / A | N / A | N / A | Très haut | Haut | N / A |
| Sécurité | Faible | Faible | Faible | Haut | Haut | Faible |
Chunking fixe : les outils de chiffon traditionnels reposent sur des tailles de morceaux fixes, limitant leur adaptabilité dans la gestion de la complexité et du contexte variables des données.
Précision vs sémantique : les méthodes de récupération actuelles se concentrent généralement sur la compréhension sémantique ou la récupération précise, mais rarement les deux.
Limitation à un seul document : de nombreuses solutions ne peuvent interroger qu'un document à la fois, restreignant la récupération d'informations à plusieurs documents.
Stabilité : Incarnamind est compatible avec Openai GPT, Anthropic Claude, Llama2 et autres LLMS open-source, assurant une analyse stable.
Chunking adaptatif : notre technique de section de fenêtre coulissante ajuste dynamiquement la taille et la position de la fenêtre pour le chiffon, équilibrant l'accès aux données à grain fin et grossier en fonction de la complexité et du contexte des données.
QA conversationnel multi-documents : prend en charge simultanément les requêtes simples et multi-hop sur plusieurs documents, brisant la limitation d'un seul document.
Compatibilité des fichiers : prend en charge les formats de fichiers PDF et TXT.
Compatibilité du modèle LLM : prend en charge Openai GPT, Anthropic Claude, Llama2 et autres LLMS open-source.

L'installation est simple, il vous suffit d'exécuter quelques commandes.
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMindCréer un environnement virtuel Conda:
conda create -n IncarnaMind python=3.10Activer:
conda activate IncarnaMindInstallez toutes les exigences:
pip install -r requirements.txtInstallez la LLAMA-CPP séparément si vous souhaitez exécuter des LLM locales quantifiées:
NVIDIA , utilisez cuBLAS CMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 ), utilisez CMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirConfigurez votre / toutes les touches API dans le fichier configParser.ini :
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(Facultatif) Configuration de vos paramètres personnalisés dans le fichier configParser.ini :
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)Mettez tous vos fichiers (veuillez nommer correctement chaque fichier pour maximiser les performances) dans le répertoire / données et exécuter la commande suivante pour ingérer toutes les données: (vous pouvez supprimer des exemples de fichiers dans le répertoire / données avant d'exécuter la commande)
python docs2db.pyAfin de démarrer la conversation, exécutez une commande comme:
python main.pyAttendez que le script nécessite votre entrée comme celle ci-dessous.
Human:Lorsque vous commencez un chat, le système générera automatiquement un fichier incarnamind.log . Si vous souhaitez modifier la journalisation, veuillez modifier dans le fichier configParser.ini .
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)sUn merci spécial à Langchain, Chroma DB, LocalGpt, Llama-CPP pour leurs précieuses contributions à la communauté open-source. Leur travail a contribué à faire du projet Incarnamind une réalité.
Si vous souhaitez citer notre travail, veuillez utiliser l'entrée Bibtex suivante:
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Licence Apache 2.0


