Awesome ChatTTS
1.0.0

Anglais | chinois simplifié
Awesome-Chattts est un projet de résumé des ressources Chattts officiellement recommandé.
Si vous pensez que ce projet vous est utile de comprendre et d'utiliser des chattts, veuillez me donner des récompenses et un soutien.
Note
Les projets suivants sont des ressources communautaires.
| Site web | taper |
|---|---|
| Web original | Expérience de version Web originale |
| Forge web | Forge Expection en édition améliorée |
| Linux | Package d'installation Python |
| Échantillons | Exemple de graines de tonalité |
| Clonage | Expérience de clonage de tonalité |
| projet | Étoile | Points forts |
|---|---|---|
| jianchang512 / chattts-ui | Fournit une interface API qui peut être appelée dans des applications tierces | |
| 6DRF21E / CHATTTS_COLAB | Fournir une sortie en streaming, prendre en charge une longue génération audio et une lecture de caractéristiques partielles | |
| Lenml / Chattts-Forge | Fournit une amélioration vocale et une réduction du bruit de fond, avec des mots rapides supplémentaires disponibles | |
| Ccmahua / chattts amélioré | Prend en charge le traitement par lots des fichiers et exportations de fichiers SRT | |
| Hkoon / chattts-openvoice | Clonage sonore avec OpenVoice |
| projet | Étoile | Points forts |
|---|---|---|
| 6drf21e / chattts_speaker | Marquage des caractères de ton et évaluation de la stabilité | |
| Aifsh / Comfyui-chattts | Version Comfyui, qui peut être introduite comme un nœud de workflow | |
| Matériauhadow / chattts-manager | Fournit un système de gestion des tons et une interface webui |
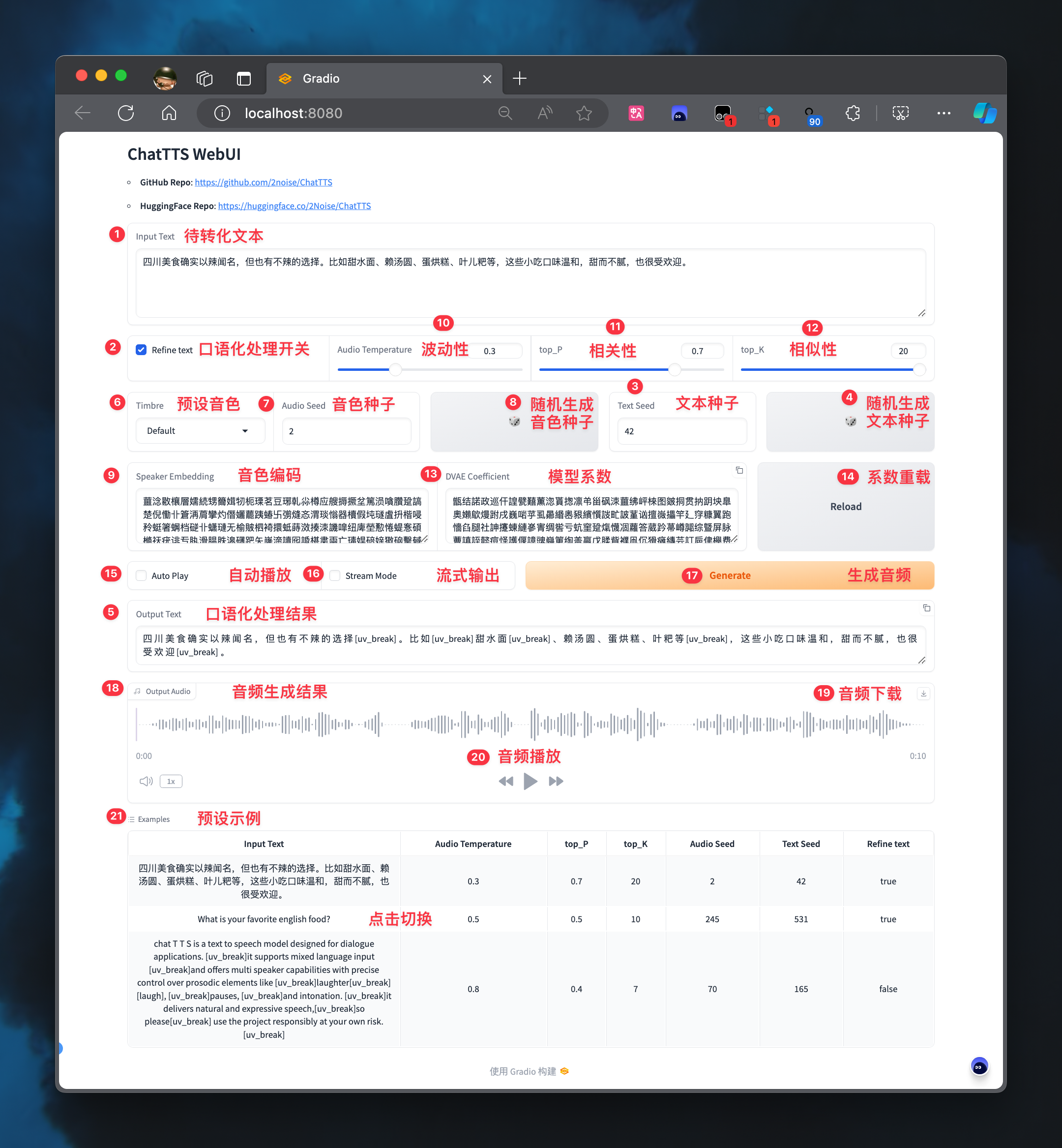
Après des .pt réels, il y a une différence significative dans l'effet de la génération spk_emb chaque fois que la valeur de graine de tonalité spécifiée est générée et réutiliser spk_emb pré-généré.
Les graines de ton ont été initialement marquées et une évaluation stable dans le projet CHATTTS_SPEAKER, et le ton droit peut être rapidement sélectionné à travers des exemples.
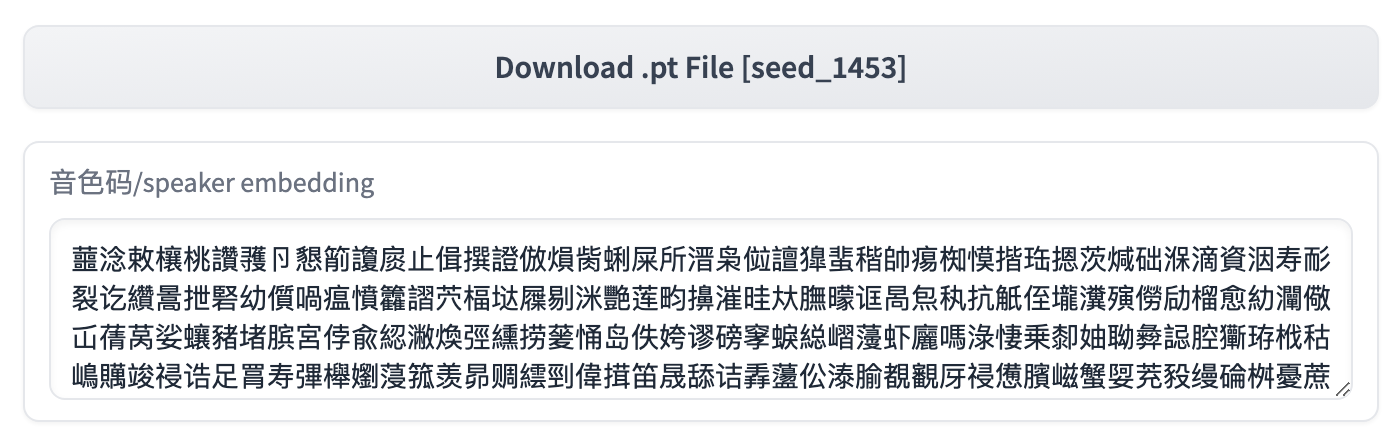
Lorsqu'il est utilisé dans le webui officiel, vous pouvez copier directement le code de tonalité et remplacer la valeur en 9. Speaker Embedding pour atteindre le contrôle de la tonalité.
Lorsqu'il est utilisé dans les scripts Python, reportez-vous au schéma de compression dans le numéro 07 pour atteindre le contrôle de la tonalité.
spk = torch . load ( "asset/seed_1332_restored_emb.pt" , map_location = torch . device ( 'cpu' )). detach ()
spk_emb_str = compress_and_encode ( spk )
params_infer_code = ChatTTS . Chat . InferCodeParams (
spk_emb = spk_emb_str , # add sampled speaker
temperature = .0003 , # using custom temperature
top_P = 0.7 , # top P decode
top_K = 20 , # top K decode
)| vidéo | Points forts |
|---|---|
| Frère Tongji Zihao | Tutoriel de déploiement détaillé de l'entrée à l'avancé |
| Ztfs | Tutoriel de déploiement Mac M1 |
| King - Bao Bao | Tutoriel de déploiement Windows |
| vidéo | Points forts |
|---|---|
| Sam Witteveen | Introduction à la version anglaise |
Après les itérations récentes, les problèmes du code du référentiel source ont été essentiellement résolus. Si vous rencontrez des problèmes, il est recommandé de vérifier en détail la version chinoise du document de description officiel.
Le projet d'origine doit télécharger le modèle correspondant à partir de Huggingface. En tant qu'alternative, vous pouvez télécharger le modèle et la configuration à partir de ModelScope et configurer le chemin local.
Important
La bibliothèque de modèles sur la tour magique est maintenue par des bénévoles et ne garantit pas que tous les modèles sont à jour.
pip install modelscope # 在开头导入依赖,并下载模型和配置
from modelscope import snapshot_download
model_dir = snapshot_download ( 'zlj2546/ChatTTS' )
# 第 118 行修改模型路径
ret = chat . load_models ( 'custom' , custom_path = model_dir )Lors de l'exécution dans l'IDE, le script ne peut pas fonctionner en douceur en raison du chemin relatif du fichier.
Il est recommandé de se référer aux instructions du démarrage rapide de la documentation officielle et de l'exécuter directement dans le terminal.
Assurez-vous que vous êtes dans le répertoire racine du projet lors de l'exécution de la commande suivante.
python examples/web/webui.pyL'audio généré sera enregistré sur
./output_audio_n.mp3
python examples/cmd/run.py " Your text 1. " " Your text 2. " Ce problème se produit parce que le code officiel ne couvre pas tout le temps lorsqu'il s'agit de ponctuation chinoise, par exemple ? Les symboles tels que, … ne sont pas traités, entraînant une erreur pendant la génération de modèles.
Vous pouvez supprimer manuellement des marques de ponctuation chinoises similaires ou modifier le code dans ChatTTS/utils/infer_utils.py pour ajouter des marques de ponctuation manquantes au dictionnaire de character_map sur les lignes 103.
character_map = {
'…' : '' ,
'—' : ',' ,
'_' : ',' ,
'?' : ',' ,
}Le GPU nécessite une mémoire vidéo 4G, sinon le CPU sera utilisé pour les problèmes connexes, veuillez vous référer aux instructions du projet Chattts-UI.
1. load_models() got an unexpected keyword argument 'source'
Voir FAQS pour plus de détails - le modèle ne peut pas être téléchargé
2. cannot import name 'CommitOperationAdd' from 'huggingface_hub'
Voir FAQS pour plus de détails - le modèle ne peut pas être téléchargé
3. FileNotFoundError:[Erzno 2] No such file or directory: 'C:\Users\xxx\.cache\huggingface\hub\models--2Noise--ChatTTS\snapshots
Voir FAQS pour plus de détails - le modèle ne peut pas être téléchargé
4. local variable 'Normalizer' referenced before assignment
Vous devez installer des dépendances pynini et WeTextProcessing après avoir terminé la configuration de l'environnement.
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing 5. download to Local path D:pythonlprojectChatTTSChatTTS failed.
Exécuter les scripts directement dans l' IDE et une erreur sera signalée en raison des problèmes de chemin de fichier.
6. ModuleNotFoundError : No module named'Cython'
Le chemin d'exécution Python n'est pas trouvé, les appareils Windows doivent configurer le chemin d'environnement en fonction du tutoriel


