instructor
1.7.0
L'instructeur est la bibliothèque Python la plus populaire pour travailler avec des sorties structurées de modèles de grande langue (LLM), avec plus de 600 000 téléchargements mensuels. Construit au-dessus de Pyndantic, il fournit une API simple, transparente et conviviale pour gérer les réponses de validation, de tentatives et de streaming. Préparez-vous à suralimenter vos flux de travail LLM avec le premier choix de la communauté!
Si votre entreprise utilise beaucoup l'instructeur, nous aimerions avoir votre logo sur notre site Web! Veuillez remplir ce formulaire
Installez l'instructeur avec une seule commande:
pip install -U instructorMaintenant, voyons l'instructeur en action avec un exemple simple:
import instructor
from pydantic import BaseModel
from openai import OpenAI
# Define your desired output structure
class UserInfo ( BaseModel ):
name : str
age : int
# Patch the OpenAI client
client = instructor . from_openai ( OpenAI ())
# Extract structured data from natural language
user_info = client . chat . completions . create (
model = "gpt-4o-mini" ,
response_model = UserInfo ,
messages = [{ "role" : "user" , "content" : "John Doe is 30 years old." }],
)
print ( user_info . name )
#> John Doe
print ( user_info . age )
#> 30L'instructeur fournit un système de crochets puissant qui vous permet d'intercepter et d'enregistrer différentes étapes du processus d'interaction LLM. Voici un exemple simple démontrant comment utiliser les crochets:
import instructor
from openai import OpenAI
from pydantic import BaseModel
class UserInfo ( BaseModel ):
name : str
age : int
# Initialize the OpenAI client with Instructor
client = instructor . from_openai ( OpenAI ())
# Define hook functions
def log_kwargs ( ** kwargs ):
print ( f"Function called with kwargs: { kwargs } " )
def log_exception ( exception : Exception ):
print ( f"An exception occurred: { str ( exception ) } " )
client . on ( "completion:kwargs" , log_kwargs )
client . on ( "completion:error" , log_exception )
user_info = client . chat . completions . create (
model = "gpt-4o-mini" ,
response_model = UserInfo ,
messages = [
{ "role" : "user" , "content" : "Extract the user name: 'John is 20 years old'" }
],
)
"""
{
'args': (),
'kwargs': {
'messages': [
{
'role': 'user',
'content': "Extract the user name: 'John is 20 years old'",
}
],
'model': 'gpt-4o-mini',
'tools': [
{
'type': 'function',
'function': {
'name': 'UserInfo',
'description': 'Correctly extracted `UserInfo` with all the required parameters with correct types',
'parameters': {
'properties': {
'name': {'title': 'Name', 'type': 'string'},
'age': {'title': 'Age', 'type': 'integer'},
},
'required': ['age', 'name'],
'type': 'object',
},
},
}
],
'tool_choice': {'type': 'function', 'function': {'name': 'UserInfo'}},
},
}
"""
print ( f"Name: { user_info . name } , Age: { user_info . age } " )
#> Name: John, Age: 20Cet exemple démontre:
Les crochets fournissent des informations précieuses sur les entrées de la fonction et toutes les erreurs, améliorant les capacités de débogage et de surveillance.
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_anthropic ( Anthropic ())
# note that client.chat.completions.create will also work
resp = client . messages . create (
model = "claude-3-opus-20240229" ,
max_tokens = 1024 ,
system = "You are a world class AI that excels at extracting user data from a sentence" ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 Assurez-vous d'installer cohere et de définir votre variable d'environnement système avec export CO_API_KEY=<YOUR_COHERE_API_KEY> .
pip install cohere
import instructor
import cohere
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_cohere ( cohere . Client ())
# note that client.chat.completions.create will also work
resp = client . chat . completions . create (
model = "command-r-plus" ,
max_tokens = 1024 ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 Assurez-vous d'installer le SDK Google AI Python. Vous devez définir une variable d'environnement GOOGLE_API_KEY avec votre clé API. L'appel d'outil Gemini nécessite également que jsonref soit installé.
pip install google-generativeai jsonref
import instructor
import google . generativeai as genai
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
# genai.configure(api_key=os.environ["API_KEY"]) # alternative API key configuration
client = instructor . from_gemini (
client = genai . GenerativeModel (
model_name = "models/gemini-1.5-flash-latest" , # model defaults to "gemini-pro"
),
mode = instructor . Mode . GEMINI_JSON ,
) Alternativement, vous pouvez appeler Gemini auprès du client OpenAI. Vous devrez configurer gcloud , obtenir une configuration sur Vertex AI et installer la bibliothèque Google Auth.
pip install google-auth import google . auth
import google . auth . transport . requests
import instructor
from openai import OpenAI
from pydantic import BaseModel
creds , project = google . auth . default ()
auth_req = google . auth . transport . requests . Request ()
creds . refresh ( auth_req )
# Pass the Vertex endpoint and authentication to the OpenAI SDK
PROJECT = 'PROJECT_ID'
LOCATION = (
'LOCATION' # https://cloud.google.com/vertex-ai/generative-ai/docs/learn/locations
)
base_url = f'https:// { LOCATION } -aiplatform.googleapis.com/v1beta1/projects/ { PROJECT } /locations/ { LOCATION } /endpoints/openapi'
client = instructor . from_openai (
OpenAI ( base_url = base_url , api_key = creds . token ), mode = instructor . Mode . JSON
)
# JSON mode is req'd
class User ( BaseModel ):
name : str
age : int
resp = client . chat . completions . create (
model = "google/gemini-1.5-flash-001" ,
max_tokens = 1024 ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 import instructor
from litellm import completion
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_litellm ( completion )
resp = client . chat . completions . create (
model = "claude-3-opus-20240229" ,
max_tokens = 1024 ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 C'était le rêve de l'instructeur, mais en raison du correctif d'Openai, il n'était pas possible pour moi de bien fonctionner. Maintenant, avec le nouveau client, nous pouvons faire fonctionner bien la frappe! Nous avons également ajouté quelques méthodes create_* pour faciliter la création d'itérables et partiels, et pour accéder à l'achèvement d'origine.
create import openai
import instructor
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_openai ( openai . OpenAI ())
user = client . chat . completions . create (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
)Maintenant, si vous utilisez un IDE, vous pouvez voir que le type est correctement déduit.
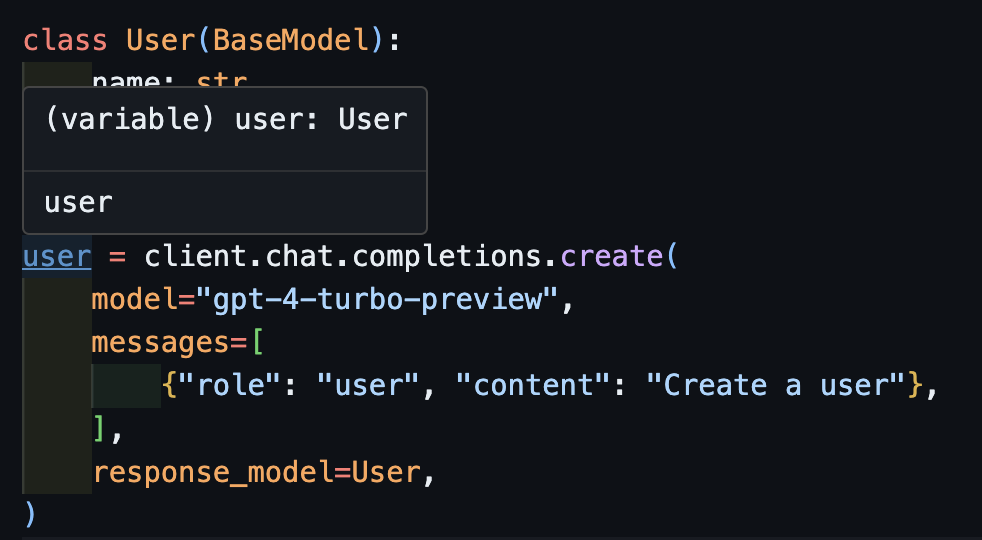
await createCela fonctionnera également correctement avec des clients asynchrones.
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . AsyncOpenAI ())
class User ( BaseModel ):
name : str
age : int
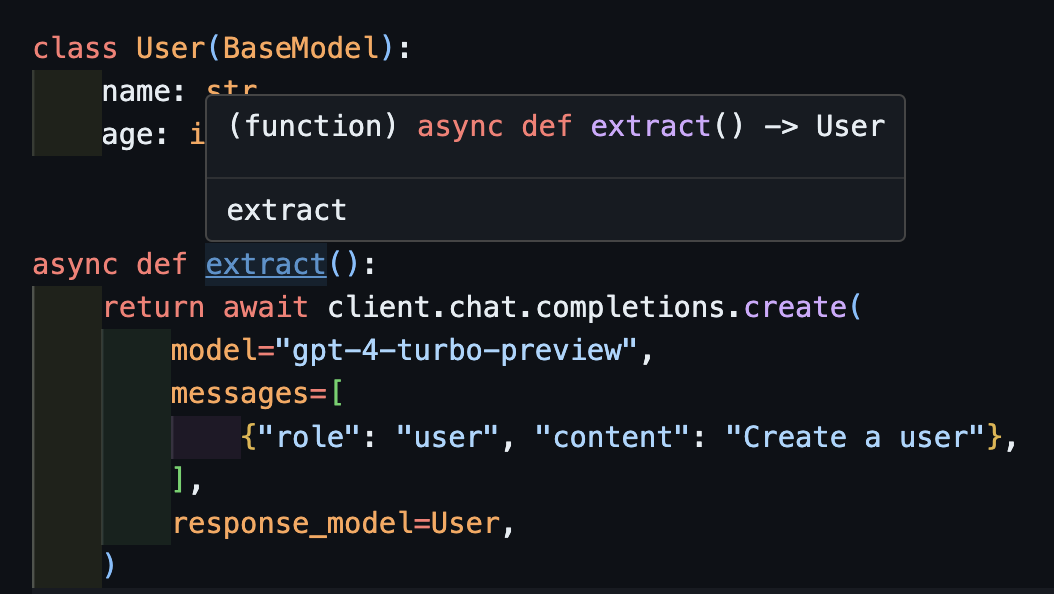
async def extract ():
return await client . chat . completions . create (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
) Notez que simplement parce que nous renvoyons la méthode create , la fonction extract() renvoie le type d'utilisateur correct.
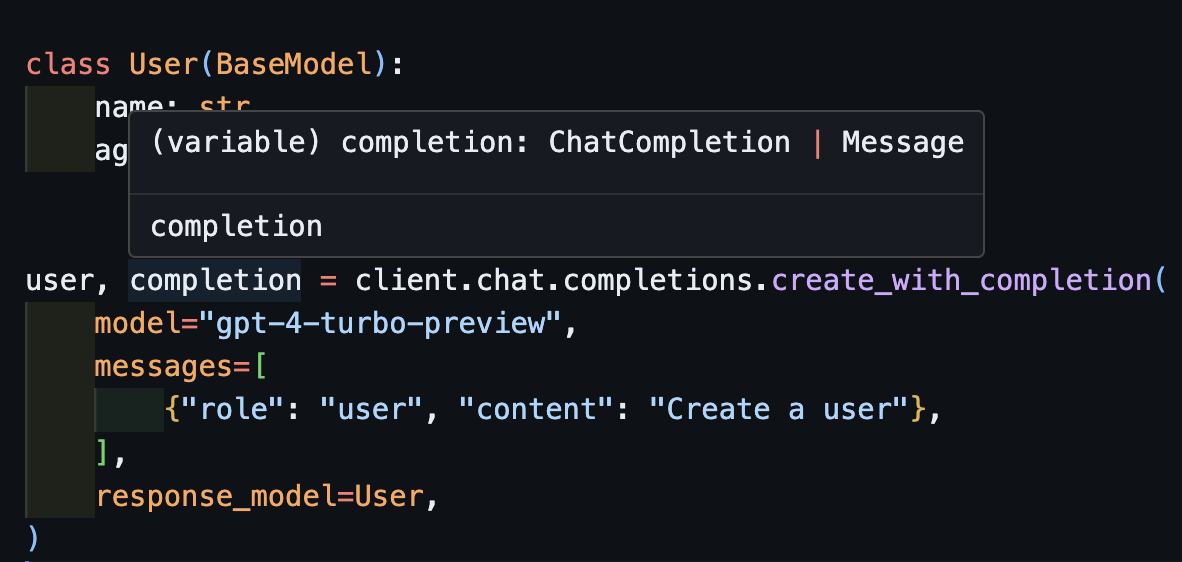
create_with_completionVous pouvez également retourner l'objet d'achèvement d'origine
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . OpenAI ())
class User ( BaseModel ):
name : str
age : int
user , completion = client . chat . completions . create_with_completion (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
)
create_partial Afin de gérer les flux, nous prenons toujours en charge Iterable[T] et Partial[T] mais pour simplifier l'inférence de type, nous avons également ajouté des méthodes create_iterable et create_partial !
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . OpenAI ())
class User ( BaseModel ):
name : str
age : int
user_stream = client . chat . completions . create_partial (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
)
for user in user_stream :
print ( user )
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name='John Doe' age=None
#> name='John Doe' age=None
#> name='John Doe' age=None
#> name='John Doe' age=30
#> name='John Doe' age=30
# name=None age=None
# name='' age=None
# name='John' age=None
# name='John Doe' age=None
# name='John Doe' age=30 Remarquez maintenant que le type inféré est Generator[User, None]
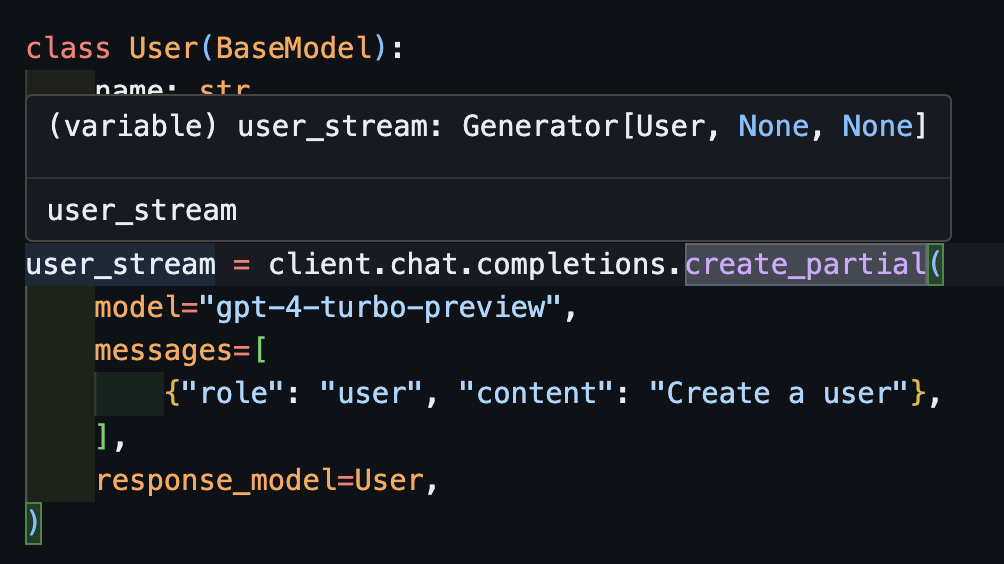
create_iterableNous obtenons un itérable d'objets lorsque nous voulons extraire plusieurs objets.
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . OpenAI ())
class User ( BaseModel ):
name : str
age : int
users = client . chat . completions . create_iterable (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create 2 users" },
],
response_model = User ,
)
for user in users :
print ( user )
#> name='John Doe' age=30
#> name='Jane Doe' age=28
# User(name='John Doe', age=30)
# User(name='Jane Smith', age=25) 
Nous vous invitons à contribuer aux Evals dans pytest afin de surveiller la qualité des modèles OpenAI et de la bibliothèque instructor . Pour commencer, consultez les Evals pour Anthropic et OpenAI et contribuez vos propres Evals sous la forme de tests Pytest. Ces évals seront exécutés une fois par semaine et les résultats seront affichés.
Si vous voulez aider, consultez certains des problèmes marqués comme good-first-issue ou help-wanted ici. Ils pourraient être des améliorations de code, un article de blog invité ou un nouveau livre de cuisine.
Nous fournissons également des fonctionnalités CLI supplémentaires pour une commodité facile:
instructor jobs : Cela aide à la création de travaux de réglage fin avec OpenAI. Utilisation simple instructor jobs create-from-file --help pour commencer à créer votre premier modèle GPT-3.5 affiné
instructor files : gérez facilement vos fichiers téléchargés. Vous pourrez créer, supprimer et télécharger des fichiers tous de la ligne de commande
instructor usage : Au lieu de vous diriger vers le site OpenAI à chaque fois, vous pouvez surveiller votre utilisation à partir de la CLI et filtrer par date et période. Notez que l'utilisation prend souvent ~ 5 à 10 minutes à mettre à jour du côté d'Openai
Ce projet est concédé sous licence de la licence du MIT.


