GPTCache
v0.1.44
Slash votre API LLM coûte de 10x?, Alimenter la vitesse de 100x ⚡
? GPTCache a été entièrement intégré à? ️? Langchain! Voici des instructions d'utilisation détaillées.
? L'image Docker du serveur GPTCache a été publiée, ce qui signifie que n'importe quelle langue pourra utiliser GPTCache!
? Ce projet subit un développement rapide et, en tant que tel, l'API peut être sujette à un changement à tout moment. Pour les informations les plus à jour, veuillez vous référer à la dernière note de documentation et de publication.
Remarque: Comme le nombre de grands modèles augmente de manière explosive et que leur forme d'API évolue constamment, nous n'ajoutons plus le support pour de nouvelles API ou modèles. Nous encourageons l'utilisation de l'utilisation de l'API Get and Set dans gptcache, voici le code de démon
pip install gptcache
Chatgpt et divers modèles de grandes langues (LLMS) possèdent une polyvalence incroyable, permettant le développement d'un large éventail d'applications. Cependant, à mesure que votre application gagne en popularité et rencontre des niveaux de trafic plus élevés, les dépenses liées aux appels API LLM peuvent devenir substantielles. De plus, les services LLM pourraient présenter des temps de réponse lents, en particulier lorsqu'ils traitent d'un nombre important de demandes.
Pour relever ce défi, nous avons créé GPTCache, un projet dédié à la construction d'un cache sémantique pour stocker les réponses LLM.
Note :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installCes exemples vous aideront à comprendre comment utiliser une correspondance exacte et similaire avec la mise en cache. Vous pouvez également exécuter l'exemple sur Colab. Et plus d'exemples que vous pouvez vous référer au bootcamp
Avant d'exécuter l'exemple, assurez-vous que la variable d'environnement OpenAI_API_KEY est définie en exécutant echo $OPENAI_API_KEY .
S'il n'est pas déjà défini, il peut être défini à l'aide d' export OPENAI_API_KEY=YOUR_API_KEY sur les systèmes UNIX / Linux / macOS ou set OPENAI_API_KEY=YOUR_API_KEY sur les systèmes Windows.
Il est important de noter que cette méthode n'est efficace que temporairement, donc si vous voulez un effet permanent, vous devrez modifier le fichier de configuration de la variable d'environnement. Par exemple, sur un Mac, vous pouvez modifier le fichier situé sur
/etc/profile.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Si vous posez le chatppt des deux mêmes questions, la réponse à la deuxième question sera obtenue à partir du cache sans demander à nouveau Chatgpt.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Après avoir obtenu une réponse de Chatgpt en réponse à plusieurs questions similaires, les réponses aux questions ultérieures peuvent être récupérées du cache sans avoir à demander à nouveau Chatgpt.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Vous pouvez toujours passer un paramètre de température tout en demandant le service ou le modèle API.
La plage de
temperatureest [0, 2], la valeur par défaut est de 0,0.Une température plus élevée signifie une possibilité plus élevée de sauter directement le cache et de demander un grand modèle. Lorsque la température est de 2, il sautera directement le cache et envoie la demande au grand modèle. Lorsque la température est de 0, il recherchera le cache avant de demander un grand service de modèle.
Le
post_process_messages_funcpar défaut par défaut esttemperature_softmax. Dans ce cas, reportez-vous à la référence de l'API pour savoir commenttemperatureaffecte la sortie.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])Pour utiliser GPTCache exclusivement, seules les lignes de code suivantes sont nécessaires et il n'est pas nécessaire de modifier un code existant.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()Plus de documents:
GPTCache offre les principaux avantages suivants:
Les services en ligne présentent souvent une localité de données, les utilisateurs accédant fréquemment à un contenu populaire ou à tendance. Les systèmes de cache profitent de ce comportement en stockant des données couramment accessibles, ce qui réduit à son tour le temps de récupération des données, améliore les temps de réponse et assouplit la charge des serveurs backend. Les systèmes de cache traditionnels utilisent généralement une correspondance exacte entre une nouvelle requête et une requête en cache pour déterminer si le contenu demandé est disponible dans le cache avant de récupérer les données.
Cependant, l'utilisation d'une approche de correspondance exacte pour les caches LLM est moins efficace en raison de la complexité et de la variabilité des requêtes LLM, résultant en un faible taux de succès du cache. Pour résoudre ce problème, GPTCache adopte des stratégies alternatives comme la mise en cache sémantique. La mise en cache sémantique identifie et stocke des requêtes similaires ou connexes, augmentant ainsi le cache de cache et l'amélioration de l'efficacité de mise en cache globale.
GPTCache utilise des algorithmes d'intégration pour convertir les requêtes en intégres et utilise un magasin vectoriel pour une recherche de similitude sur ces intérêts. Ce processus permet à GPTCache d'identifier et de récupérer des requêtes similaires ou liées à partir du stockage du cache, comme illustré dans la section des modules.
Avec un design modulaire, GPTCache permet aux utilisateurs de personnaliser facilement leur propre cache sémantique. Le système propose diverses implémentations pour chaque module, et les utilisateurs peuvent même développer leurs propres implémentations en fonction de leurs besoins spécifiques.
Dans un cache sémantique, vous pouvez rencontrer de faux positifs pendant les coups de cache et les faux négatifs pendant les manquements de cache. GPTCache propose trois mesures pour évaluer ses performances, qui sont utiles aux développeurs pour optimiser leurs systèmes de mise en cache:
Un exemple de référence est inclus pour que les utilisateurs commencent par évaluer les performances de leur cache sémantique.
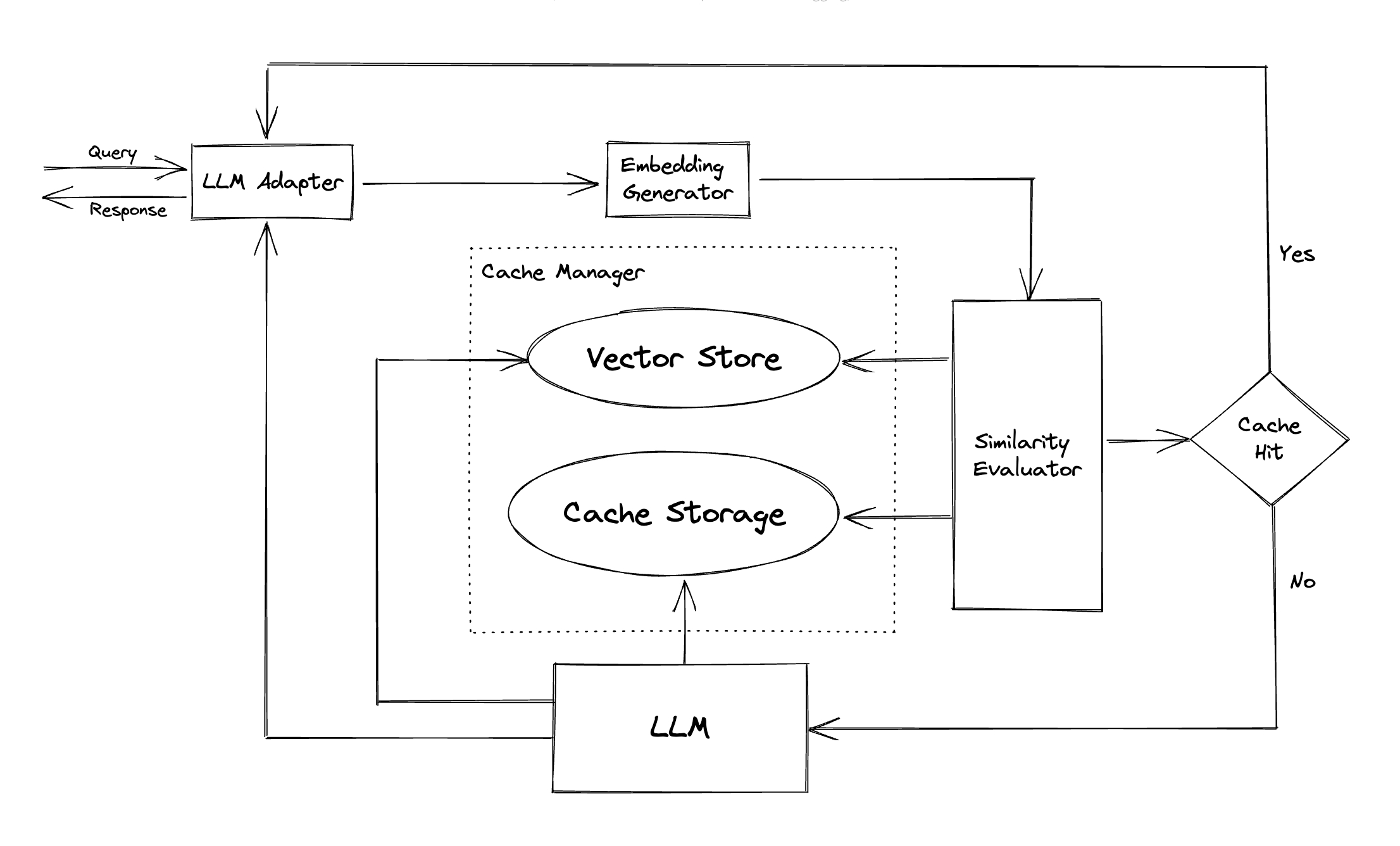
Adaptateur LLM : L'adaptateur LLM est conçu pour intégrer différents modèles LLM en unifiant leurs API et en demande des protocoles. GPTCACH propose une interface standardisée à cet effet, avec la prise en charge actuelle de l'intégration ChatGPT.
Adaptateur multimodal (expérimental) : L'adaptateur multimodal est conçu pour intégrer différents modèles multimodaux en unificateur en unifiant leurs API et en demandant des protocoles. GPTCache propose une interface standardisée à cet effet, avec la prise en charge actuelle des intégrations de la génération d'images, la transcription audio.
Générateur d'intégration : ce module est créé pour extraire des intégres à partir de demandes de recherche de similitude. GPTCache propose une interface générique qui prend en charge plusieurs API d'intégration et présente une gamme de solutions à choisir.
Stockage de cache : le stockage du cache est où la réponse de LLMS, telle que ChatGpt, est stockée. Les réponses en cache sont récupérées pour aider à évaluer la similitude et sont retournées au demandeur en cas de bon match sémantique. À l'heure actuelle, GPTCache prend en charge SQLite et propose une interface universellement accessible pour l'extension de ce module.
Magasin vectoriel : Le module de magasin vectoriel aide à trouver les K les plus similaires demandes de l'intégration extraite de la demande d'entrée. Les résultats peuvent aider à évaluer la similitude. GPTCache fournit une interface conviviale qui prend en charge divers magasins vectoriels, notamment Milvus, Zilliz Cloud et Faish. Plus d'options seront disponibles à l'avenir.
Cache Manager : Le gestionnaire de cache est responsable du contrôle du fonctionnement du magasin de stockage de cache et de vecteur .
cachetools de Python ou de manière distribuée en utilisant Redis comme magasin de valeurs clés.Actuellement, GPTCache prend des décisions concernant les expulsions basées uniquement sur le nombre de lignes. Cette approche peut entraîner une évaluation inexacte des ressources et peut entraîner des erreurs hors mémoire (OOM). Nous étudions activement et développons une stratégie plus sophistiquée.
Si vous deviez évoluer votre déploiement GPTCache à l'aide d'une mise en cache en mémoire, cela ne sera pas possible. Étant donné que les informations mises en cache seraient limitées au pod unique.
Avec la mise en cache distribuée, les informations de cache cohérentes dans toutes les répliques, nous pouvons utiliser des magasins de cache distribués comme Redis.
Évaluateur de similitude : ce module collecte des données à la fois dans le magasin de stockage de cache et de vecteur, et utilise diverses stratégies pour déterminer la similitude entre la demande d'entrée et les demandes du magasin vectoriel . Sur la base de cette similitude, il détermine si une demande correspond au cache. GPTCache fournit une interface standardisée pour intégrer diverses stratégies, ainsi qu'une collection d'implémentations à utiliser. Les définitions de similitude suivantes sont actuellement prises en charge ou seront prises en charge à l'avenir:
Remarque : Toutes les combinaisons de différents modules peuvent être compatibles entre elles. Par exemple, si nous désactivons l' extracteur d'intégration , le magasin vectoriel peut ne pas fonctionner comme prévu. Nous travaillons actuellement sur la mise en œuvre d'une vérification de santé mentale combinée pour GPTCache .
À venir! Restez à l'écoute!
Nous sommes extrêmement ouverts aux contributions, que ce soit à travers de nouvelles fonctionnalités, une infrastructure améliorée ou une documentation améliorée.
Pour des instructions complètes sur la façon de contribuer, veuillez vous référer à notre guide de contribution.


