JARVIS ChatGPT
1.0.0
Un assistant interactif basé sur la voix équipé d'une variété de voix synthétiques (y compris la voix de Jarvis d'Ironman)
 Image par MidJourney Ai
Image par MidJourney Ai
Avez-vous déjà rêvé de demander des conseils système hyper-intelligents pour améliorer votre armure? Maintenant, vous pouvez! Eh bien, peut-être pas la partie armure ... ce projet exploite Openai Whisper, Openai Chatgpt et IBM Watson.
Motivation du projet:
Plusieurs fois, les idées viennent dans le pire moment et ils se sontompent avant d'avoir le temps de les explorer mieux. L'objectif de ce projet est de développer un système capable de donner des conseils et des opinions en temps quasi-réel sur tout ce que vous demandez. L'assistant ultime pourra être accessible à partir de tout microphone autorisé à l'intérieur de votre maison ou de votre téléphone, il devrait s'exécuter constamment en arrière-plan et lorsqu'il est invoqué devrait pouvoir générer des réponses significatives (avec une voix badass) ainsi que l'interface avec le PC ou un serveur et enregistrer / lire / écrire des fichiers qui peuvent être accessibles plus tard. Il devrait être en mesure d'exécuter des recherches, de rassembler du matériel à partir d'Internet (extraire le contenu des pages HTML, transcrire des vidéos YouTube, trouver des articles scientifiques ...) et fournir des résumés qui peuvent être utilisés comme contexte pour prendre des décisions éclairées. De plus, il pourrait s'interfacer avec certains gadgets externes (IoT), mais c'est plus.
Démo:
Je peux partager Finnaly le premier projet du mode de recherche. Cette modalité a été pensée pour les gens qui traitent souvent des documents de recherche.
PS: Ce mode n'est pas super stable et doit être travaillé sur
PPS: Ce projet sera interrompu pendant un certain temps car je travaillerai sur ma thèse jusqu'en 2024. Cependant, il y a déjà tellement de choses qui peuvent être améliorées, donc je reviendrai!
CLAUSE DE NON-RESPONSABILITÉ:
Le projet pourrait consommer votre crédit OpenAI, ce qui a entraîné une facturation indésirable;
Je ne prends la responsabilité d'aucune accusation indésirable;
Envisagez de fixer des limites à la consommation de crédit sur votre compte OpenAI;
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );Vous pouvez compter sur la nouvelle
setup.batqui fera la plupart des choses pour vous.
Script principal Vous devez exécuter: openai_api_chatbot.py Si vous souhaitez utiliser la dernière version de l'API OpenAI dans le dossier Demos, vous trouverez des conseils pour les packages utilisés dans le projet, si vous avez des erreurs, vous pouvez d'abord vérifier ces fichiers pour cibler le problème. Maisant principalement dans le dossier Assistant: get_audio.py stocke toutes les fonctions pour gérer les interactions micro, tools.py implémente certains aspects de base de l'assistant virtuel, voice.py décrit une classe vocale (très). Agents.py Gire la partie Langchain du système (ici, vous pouvez ajouter ou supprimer des outils des boîtes à outils des agents)
Les scripts restants sont complémentaires à la génération de voix et ne doivent pas être modifiés.
Vous pouvez exécuter setup.bat si vous exécutez sur Windows / Linux. Le script effectuera chaque étape de l'installation manuelle en séquence. Reportez-vous à ceux-ci dans le cas où la procédure devrait échouer.
L'installation automatique exécutera également l'installation de Vicuna (Guide d'installation de Vicuna)
pip install -r venv_requirements.txt ; Cela pourrait prendre un certain temps; Si vous rencontrez des conflits sur des packages spécifiques, installez-les manuellement sans le ==<version> ;whisper_edits dans le dossier whisper de votre environnement (. VENV lib site-Packages Whisper ) Ces modifications ajouteront juste un attribut au modèle Whisper pour accéder plus facilement à sa dimension;demos/tts_demo.py ); cd Vicuna
call vicuna.ps1
env.txt et renommez-la à .env (oui, supprimez l'extension txt)torch.cuda.is_available() et torch.cuda.get_device_name(0) à l'intérieur de pyhton; .tests.py . Ce fichier tente d'effectuer des opérations de base qui pourraient augmenter les erreurs;VirtualAssistant.__init__() ; 
__main__() sur whisper_model = whisper.load_model("large") ; Mais j'espère que votre mémoire GPU est également importante. openai_api_chatbot.py ):Lors de l'exécution, vous verrez beaucoup d'informations affichées. Je m'efforce constamment d'améliorer la lisibilité de l'exécution, l'ensemble du projet est une énorme version bêta, pardonne de légères variations des écrans ci-dessous. Quoi qu'il en soit, c'est ce qui se passe en termes généraux lorsque vous appuyez sur «Run»:
Jarvis invoque l'assistant. À ce stade, une conversation commencera et vous pouvez parler dans la langue que vous voulez (si vous avez suivi l'étape 2). La conversation se terminera lorsque vous 1) dire un mot d'arrêt 2) dire quelque chose avec un mot (comme 'ok') 3) lorsque vous cessez de poser des questions pendant plus de 30 secondes 
chat_history avec votre question, il enverra une demande avec l'API et il mettra à jour l'historique dès qu'il recevra une réponse complète de Chatgpt (cela peut prendre jusqu'à 5 à 10 secondes, envisagez de demander explicitement une réponse courte si vous êtes pressé);say() effectuera la duplication vocale pour parler avec la voix de Jarvis / quelqu'un; Si l'argument n'est pas en anglais, IBM Watson enverra la réponse de l'un de leurs beaux modèles de texte vocale. Si tout échoue, les fonctions s'appuieront sur PYTTSX3 qui est une alternative rapide mais pas aussi cool;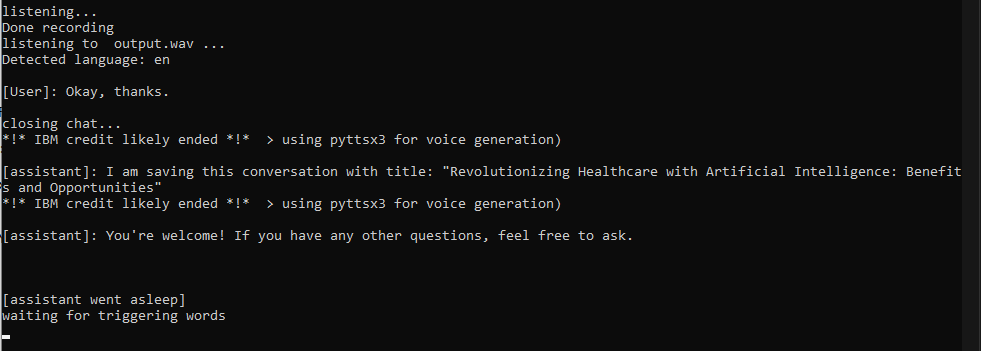
J'ai fait quelques invites et fermé la conversation
pas idéal je sais mais fonctionne pour le moment
VirtualAssistant complète avec mémoire et accès de stockage local Travaille actuellement sur:
suivant:
Vérifiez le UpdateHistory.md du projet pour plus d'informations.
Amusez-vous!
Catégories: installer, général, runtime
Le problème est préoccupant Whisper. Vous devriez le réinstaller manuellement avec pip install whisper-openai
pip install --upgrade openai . Les exigences ne sont pas mises à jour à chaque engagement. Bien que cela puisse générer des erreurs, vous pouvez rapidement installer les modules manquants, en même temps, il empêche l'environnement des conflits lorsque j'essaie de nouveaux packages (et j'en essaie beaucoup)
Cela signifie que le modèle que vous avez sélectionné est trop grand pour la mémoire de votre périphérique CUDA. Malheureusement, vous ne pouvez pas y faire grand-chose, sauf charger un modèle plus petit. Si le modèle plus petit ne vous satisfait pas, vous voudrez peut-être parler «plus clair» ou faire des invites plus longues pour permettre au modèle de prédire plus précisément ce que vous dites. Cela semble gênant mais, dans mon cas, a grandement amélioré mon anglophone :)
C'est un bug toujours présent, ne vous attendez pas à avoir des conversations toujours longues avec votre assistant car il aura simplement suffisamment de mémoire pour se souvenir de toute la conversation à un moment donné. Un correctif est en développement, il pourrait consister à adopter une approche de «fenêtres coulissantes» même si elle peut provoquer la répétition de certains concepts.
En ce moment (avril 2023), je travaille presque sans arrêt à ce sujet. Je vais probablement faire une pause en été parce que je vais travailler sur ma thèse.
Si vous avez des questions, vous pouvez me contacter en soulevant un problème et je ferai de mon mieux pour aider dès que possible.
Gianmarco Guarnier


