Deep RL Keras
1.0.0
Mise en œuvre modulaire des algorithmes d'apprentissage du renforcement profond populaire dans Keras:
Cette implémentation nécessite Keras 2.1.6, ainsi que Openai Gym.
$ pip install gym keras==2.1.6L'algorithme acteur-critique est une méthode hors politique sans modèle où le critique agit comme un approximateur de valeur de valeur et l'acteur comme un approximateur de fonction de politique. Lors de la formation, le critique prédit l'erreur TD et guide l'apprentissage de lui-même et de l'acteur. Dans la pratique, nous approximations de l'erreur TD en utilisant la fonction Advantage. Pour plus de stabilité, nous utilisons une épine dorsale de calcul partagée sur les deux réseaux, ainsi qu'une formulation en n étage des récompenses à prix réduit. Nous incorporons également un terme de régularisation d'entropie (apprentissage "doux") pour encourager l'exploration. Alors que A2C est simple et efficace, l'exécuter sur les jeux Atari devient rapidement insoluble en raison du long temps de calcul.
De la même manière que l'algorithme A2C, l'implémentation d'A3C intègre des mises à jour de poids asynchrones, permettant un calcul beaucoup plus rapide. Nous utilisons plusieurs agents pour effectuer une ascension de gradient de manière asynchrone, sur plusieurs threads. Nous testons A3C sur l'environnement de la rupture d'Atari.
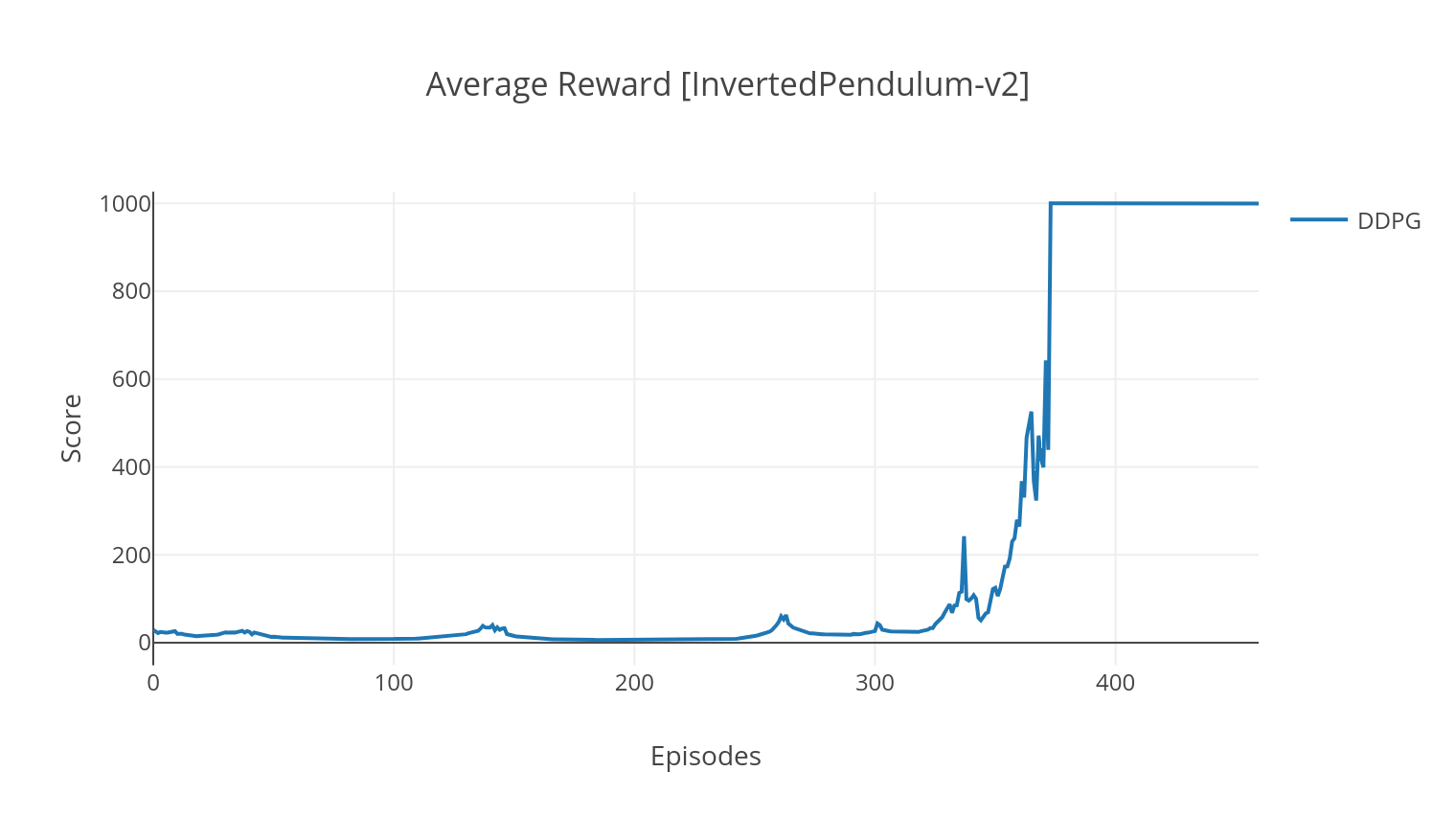
L'algorithme DDPG est un algorithme hors politique sans modèle pour les espaces d'action continue. De façon similaire à A2C, il s'agit d'un algorithme acteur-critique dans lequel l'acteur est formé sur une politique cible déterministe, et le critique prédit des valeurs Q. Afin de réduire la variance et d'augmenter la stabilité, nous utilisons une relecture d'expérience et des réseaux cibles séparés. De plus, comme indiqué par OpenAI, nous encourageons l'exploration à travers le bruit de l'espace des paramètres (par opposition au bruit traditionnel de l'espace d'action). Nous testons DDPG sur l'environnement Lunar Lander.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2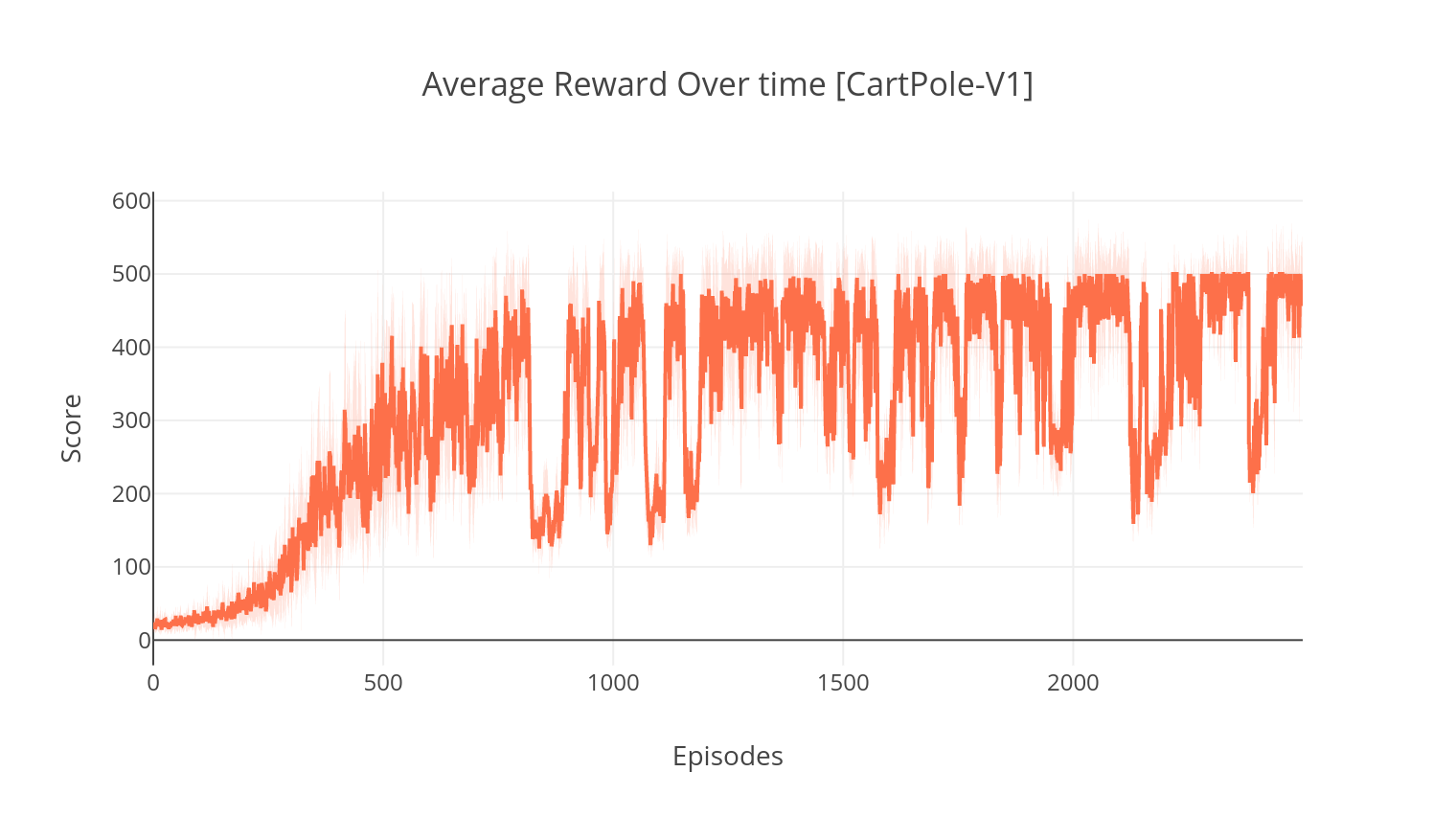
L'algorithme DQN est un algorithme de télévision Q, qui utilise un réseau neuronal profond comme approximateur de fonction de valeur Q. Nous estimons les valeurs Q cible en tirant parti de l'équation de Bellman et rassemblons l'expérience grâce à une politique d'Epsilon-Greedy. Pour plus de stabilité, nous échantillons les expériences passées au hasard (expérimentations de relecture). Une variante de l'algorithme DQN est le double-DQN (ou DDQN). Pour une estimation plus précise de nos valeurs Q, nous utilisons un deuxième réseau pour tempérer les surestimations des valeurs Q par le réseau d'origine. Ce réseau cible est mis à jour à un tau plus lent, à chaque étape de formation.
Nous pouvons encore améliorer notre algorithme DDQN en ajoutant dans la relecture d'expérience prioritaire (PER), qui vise à effectuer un échantillonnage d'importance sur l'expérience rassemblée. L'expérience est classée par son Error TD, et stockée dans une structure Sumtree, qui permet une récupération efficace des transitions (S, A, R, S ') avec l'erreur la plus élevée.
Dans la variante de duel du DQN, nous incorporons une couche intermédiaire dans le réseau Q pour estimer à la fois la valeur de l'état et la fonction d'avantage dépendant de l'état. Après la reformulation (voir réf), il s'avère que nous pouvons exprimer la valeur Q estimée comme valeur de l'État, à laquelle nous ajoutons l'estimation de l'avantage et soustrayons sa moyenne. Cette factorisation des valeurs indépendantes et dépendantes de l'État aide à démêler l'apprentissage à travers les actions et donne de meilleurs résultats.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling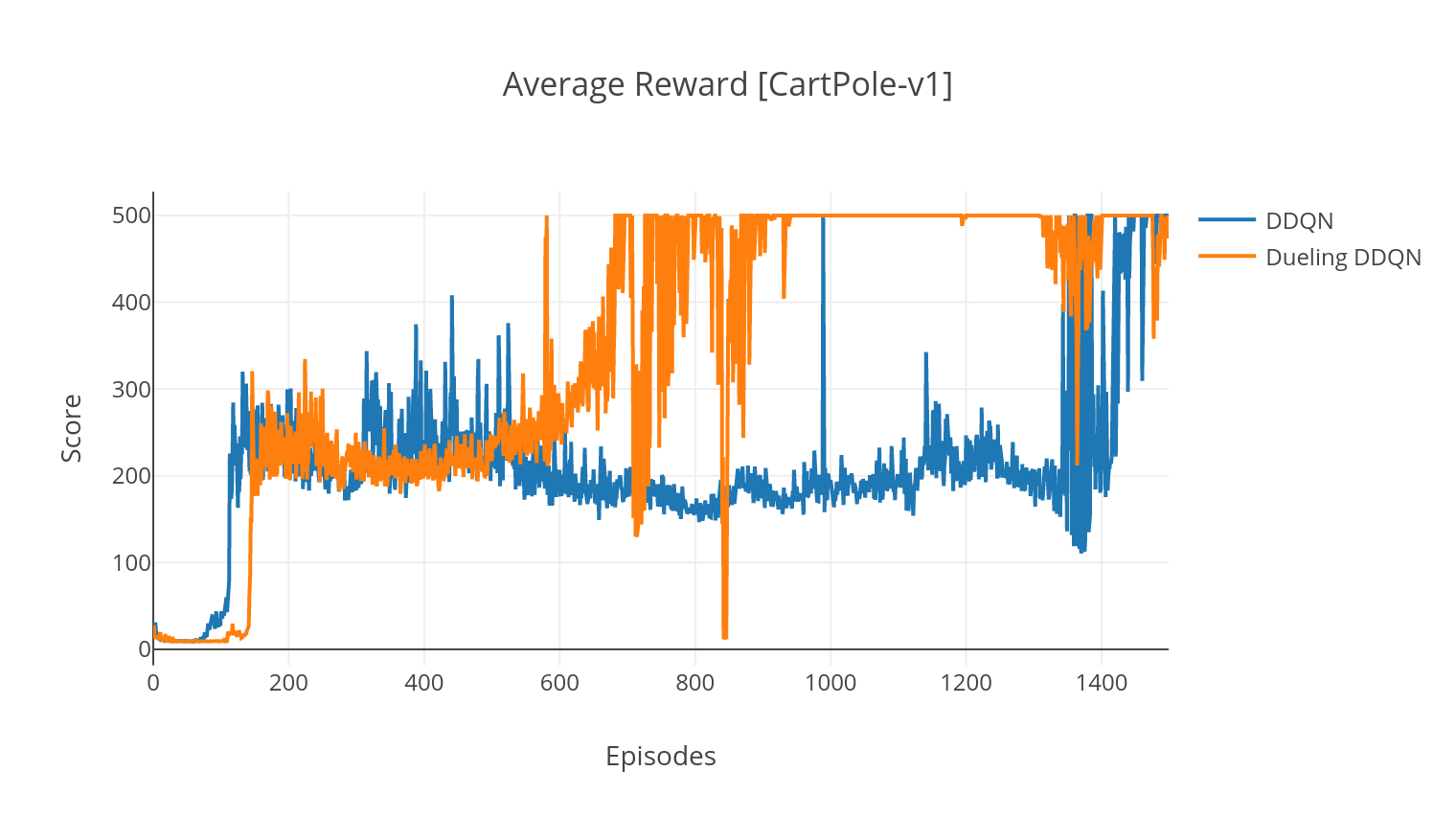
| Argument | Description | Valeurs |
|---|---|---|
| --taper | Type d'algorithme RL à fonctionner | Choisissez parmi {A2C, A3C, DDQN, DDPG} |
| --env | Spécifiez l'environnement | BreakoutnoframesKip-V4 (par défaut) |
| --nb_episodes | Nombre d'épisodes à exécuter | 5000 (par défaut) |
| - Batch_Size | Taille du lot (DDQN, DDPG) | 32 (par défaut) |
| --Conscutive_frames | Nombre de trames consécutives empilées | 4 (par défaut) |
| --is_atari | Si l'environnement est un jeu Atari avec entrée de pixels | - |
| --with_per | Que ce soit pour utiliser la relecture d'expérience prioritaire (avec DDQN) | - |
| - dueling | Que ce soit pour utiliser des réseaux de duel (avec DDQN) | - |
| --n_threads | Nombre de threads (A3C) | 16 (par défaut) |
| --gather_stats | Que ce soit pour calculer les statistiques des scores en moyenne sur 10 jeux (lent, voir ci-dessous) | - |
| --rendre | Que ce soit pour rendre l'environnement tel qu'il est en formation | - |
| --gpu | Index GPU | 0 |
Tous les modèles sont enregistrés sous <algorithm_folder>/models/ lors de l'entraînement terminé. Vous pouvez les visualiser en cours d'exécution dans le même environnement dans lequel ils ont été formés en exécutant le script load_and_run.py . Pour les modèles DQN, vous devez spécifier le chemin du modèle souhaité dans l'argument --model_path . Pour les modèles acteurs-critiques, vous devez spécifier les deux fichiers de poids dans les arguments --actor_path et --critic_path .
À l'aide de Tensorboard, vous pouvez surveiller le score de l'agent tel qu'il s'agit de formation. Lors de la formation, un dossier de journal avec le nom correspondant à l'environnement choisi sera créé. Par exemple, pour suivre la progression A2C sur Cartpole-V1, exécutez simplement:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ Lors de la formation avec l'argument --gather_stats , un fichier journal est généré contenant des scores en moyenne sur 10 jeux à chaque épisode: logs.csv . En utilisant Plotly, vous pouvez visualiser la récompense moyenne par épisode. Pour ce faire, vous devrez d'abord installer Plotly et obtenir une licence gratuite.
pip3 install plotlyPour configurer vos informations d'identification, exécutez:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )Enfin, pour tracer les résultats, exécutez:
python3 utils/plot_results.py < path_to_your_log_file >

