
[Recommandations associées : didacticiels vidéo JavaScript, interface Web]
Quel que soit le langage de programmation que vous utilisez, les chaînes sont un type de données important. Suivez-moi pour en savoir plus sur les chaînes JavaScript !
Une chaîne est une chaîne composée de caractères Si vous avez étudié C et Java , sachez que les caractères eux-mêmes peuvent également devenir un type indépendant. Cependant, JavaScript n'a pas un seul type de caractère, seulement des chaînes de longueur 1 .
Les chaînes JavaScript utilisent un codage UTF-16 fixe. Quel que soit le codage que nous utilisons lors de l'écriture du programme, il ne sera pas affecté.
des chaînes : les guillemets simples, les guillemets doubles et les guillemets inversés.
let single = 'abcdefg';//Guillemets simples let double = "asdfghj";//Guillemets doubles let backti = `zxcvbnm`;//Les guillemets
simples et doubles ont le même statut, nous ne faisons pas de distinction.
Les backticksde formatage de chaîne
nous permettent de formater élégamment les chaînes en utilisant ${...} au lieu d'utiliser l'ajout de chaînes.
let str = `J'ai ${Math.round(18.5)} ans.`;console.log(str) ;

de chaîne multiligne
permettent également à la chaîne de s'étendre sur plusieurs lignes, ce qui est très utile lorsque nous écrivons des chaînes multilignes.
let ques = `L'auteur est-il beau ? R. Très beau ; B. Si beau ; C. Super beau;`;console.log(ques);
Résultats de l'exécution du code :
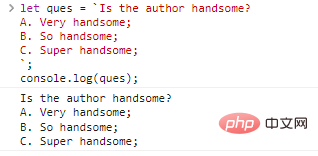
Ne semble-t-il pas qu’il n’y a rien de mal à cela ? Mais cela ne peut pas être réalisé en utilisant des guillemets simples et doubles. Si vous voulez obtenir le même résultat, vous pouvez écrire comme ceci :
let ques = 'L'auteur est-il beau ?nA. Tellement beau;nC. Super beau;'; console.log(ques);
Le code ci-dessus contient un caractère spécial n , qui est le caractère spécial le plus courant dans notre processus de programmation.
n également appelé « caractère de nouvelle ligne », prend en charge les guillemets simples et doubles pour générer des chaînes multilignes. Lorsque le moteur génère une chaîne, s'il rencontre n , il continuera à afficher sur une autre ligne, réalisant ainsi une chaîne multiligne.
Bien que n semble être constitué de deux caractères, il n'occupe qu'une seule position de caractère. En effet, est un caractère d'échappement dans la chaîne et les caractères modifiés par le caractère d'échappement deviennent des caractères spéciaux.
Liste des caractères spéciaux
| Description | des caractères spéciaux | |
|---|---|---|
n | , utilisé pour démarrer une nouvelle ligne de texte de sortie. | |
r | déplace le curseur au début de la ligne. Dans les systèmes Windows , rn est utilisé pour représenter un saut de ligne, ce qui signifie que le curseur doit d'abord aller au début de la ligne, puis ensuite. à la ligne suivante avant de pouvoir passer à une nouvelle ligne. D'autres systèmes peuvent utiliser n directement. | |
' " | Guillemets simples et doubles, principalement parce que les guillemets simples et doubles sont des caractères spéciaux. Si nous voulons utiliser des guillemets simples et doubles dans une chaîne, nous devons les échapper. | |
\ | Barre oblique inverse, également parce que | |
b f v | retour arrière, saut de page, étiquette verticale - il n'est plus utilisé | |
xXX | est un caractère Unicode hexadécimal codé comme XX , par exemple | |
: x7A signifie. z (Le codage Unicode hexadécimal de z est 7A ). | ||
uXXXX | est codé comme le caractère Unicode hexadécimal de XXXX , par exemple : u00A9 signifie © | |
UTF-32 | 1-6 caractères hexadécimaux u{X...X} . | l'encodage est le symbole Unicode de X...X . |
Par exemple :
console.log('I'ma student.');// 'console.log(""I love U. "");/ / "console.log("\n est un caractère de nouvelle ligne.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// Code résultats d'exécution :
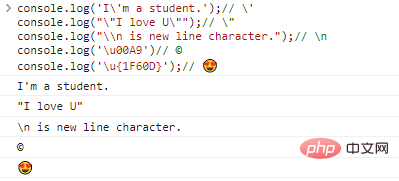
Avec l'existence du caractère d'échappement , nous pouvons théoriquement afficher n'importe quel caractère, à condition de trouver son encodage correspondant.
Évitez d'utiliser ' et "
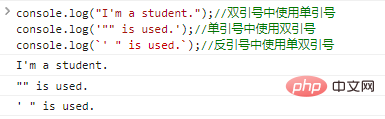
pour les guillemets simples et doubles dans les chaînes. Nous pouvons intelligemment utiliser des guillemets doubles entre guillemets simples, utiliser des guillemets simples entre guillemets doubles ou utiliser directement des guillemets simples et doubles dans des guillemets doubles. Évitez d'utiliser des caractères d'échappement, par exemple :
console.log("Je suis étudiant.");
//Utiliser des guillemets simples entre guillemets doubles console.log('"" est utilisé.');
//Utiliser des guillemets doubles entre guillemets simples console.log(`' " est utilisé.`);
//Les résultats de l'exécution du code utilisant des guillemets simples et doubles entre guillemets sont les suivants :
Grâce à la propriété .length de la chaîne, nous pouvons obtenir la longueur de la chaîne :
console.log("HelloWorldn".length);//11 n n'occupe ici qu'un seul caractère.
Dans le chapitre « Méthodes des types de base », nous avons exploré pourquoi les types de base en
JavaScriptont des propriétés et des méthodes. Vous en souvenez-vous encore ?
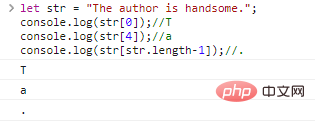
string est une chaîne de caractères. Nous pouvons accéder à un seul caractère via [字符下标] . L'indice du caractère commence à 0 :
let str = "L'auteur est beau.";console.log(str[0]);//Tconsole.log(str[4])
;
//aconsole.log(str[str.length-1]);//.
On peut aussi utiliser la fonction charAt(post) pour obtenir des caractères :
let str = "L'auteur est beau.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.L'effet
d'exécution des deux est exactement le même, la seule différence réside dans l'accès aux caractères hors limites :
let str = "01234"; console.log(str[ 9]);//undefinedconsole.log(str.charAt(9));//"" (chaîne vide)
On peut également utiliser for ..of pour parcourir la chaîne :
for(let c of '01234'){
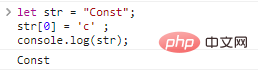
console.log(c);} Une chaîne en JavaScript ne peut pas être modifiée une fois définie. Par exemple :
let str = "Const";str[0] = 'c' ;console.log(str)
; résultats:
Si vous souhaitez obtenir une chaîne différente, vous pouvez uniquement en créer une nouvelle :
let str = "Const";str = str.replace('C','c');console.log
(str);
avons modifié la chaîne de caractères, en fait la chaîne d'origine n'a pas été modifiée, ce que nous obtenons est la nouvelle chaîne renvoyée par la méthode replace .
convertit la casse d'une chaîne ou convertit la casse d'un seul caractère dans une chaîne.
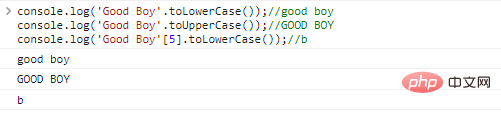
Les méthodes pour ces deux chaînes sont relativement simples, comme le montre l'exemple :
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//BON
BOYconsole.log('Good Boy'[5].toLowerCase());//b résultats de l'exécution du code :
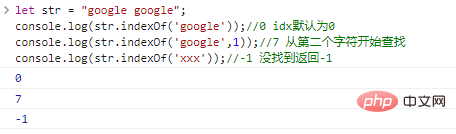
La fonction .indexOf(substr,idx) commence à partir de la position idx de la chaîne, recherche la position de la sous-chaîne substr et renvoie l'indice du premier caractère de la chaîne. sous-chaîne en cas de succès, ou -1 en cas d'échec.
let str = "google google";console.log(str.indexOf('google'));
//0 idx est par défaut 0console.log(str.indexOf('google',1));
//7 Rechercher console.log(str.indexOf('xxx')); à partir du deuxième caractère.
//-1 not found renvoie -1 résultat d'exécution de code :
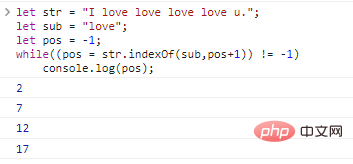
Si nous voulons interroger les positions de toutes les sous-chaînes de la chaîne, nous pouvons utiliser une boucle :
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); Les résultats de l'exécution du code sont les suivants :
.lastIndexOf(substr,idx) recherche les sous-chaînes en arrière, en trouvant d'abord la dernière chaîne correspondante :
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx par défaut est 0 car indexOf() et lastIndexOf() renverront -1 lorsque la requête échoue, et ~-1 === 0 . C'est-à-dire que l'utilisation ~ n'est vraie que lorsque le résultat de la requête n'est pas -1 , nous pouvons donc :
let str = "google google";if(~indexOf('google',str)){
...} Normalement, nous ne recommandons pas d'utiliser une syntaxe dont les caractéristiques syntaxiques ne peuvent pas être clairement reflétées, car cela aurait un impact sur la lisibilité. Heureusement, le code ci-dessus n'apparaît que dans l'ancienne version du code. Il est mentionné ici afin que tout le monde ne soit pas confus lors de la lecture de l'ancien code.
Supplément :
~est l'opérateur de négation au niveau du bit. Par exemple : la forme binaire du nombre décimal2est0010et la forme binaire de~2est1101(complément), soit-3.Une façon simple de comprendre,
~nest équivalent à-(n+1), par exemple :~2 === -(2+1) === -3
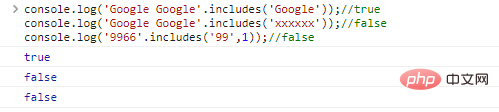
.includes(substr,idx) est utilisé pour déterminer si substr est dans la chaîne. idx est la position de départ de la requête
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google' include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//faux résultats d'exécution de code :
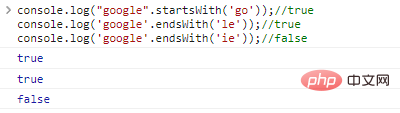
.startsWith('substr') et .endsWith('substr') déterminent respectivement si la chaîne commence ou se termine par substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));// résultat d'exécution de faux code :
.substr() , .substring() , .slice() sont tous utilisés pour obtenir des sous-chaînes de chaînes, mais leur utilisation est différente.
.substr(start,len)
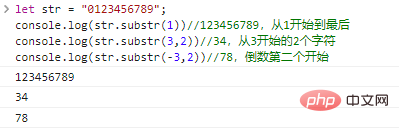
renvoie une chaîne composée de caractères len commençant à start . Si len est omis, elle sera interceptée jusqu'à la fin de la chaîne d'origine. start peut être un nombre négatif, indiquant le caractère start de l’arrière vers l’avant.
let str = "0123456789";console.log(str.substr(1))//123456789, de 1 à la fin console.log(str.substr(3,2))//34, 2 à partir de 3 Caractère console.log(str.substr(-3,2))//78, l'avant-dernier
résultat de l'exécution du code de démarrage :
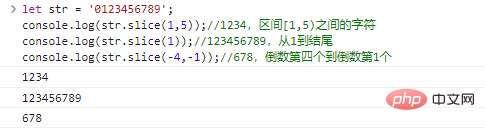
.slice(start,end)
renvoie la chaîne commençant au start et se terminant à end (exclusif). start et end peuvent être des nombres négatifs, indiquant les avant-derniers caractères start/end .
let str = '0123456789';console.log(str.slice(1,5));//1234, caractères entre l'intervalle [1,5) console.log(str.slice(1));//123456789 , de 1 à la fin console.log(str.slice(-4,-1));//678, l'avant-dernier
résultat de l'exécution du code :
.substring(start,end)
est presque la même que celle .slice() . La différence est à deux endroits :
end > start est autorisé ;0;
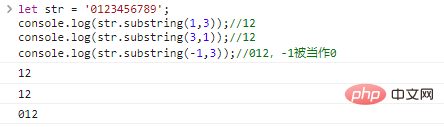
let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1 est traité comme
un résultat d'exécution de code Make 0 :
Comparez les différences entre les trois :
| méthode | description | paramètres.slice |
|---|---|---|
.slice(start,end) | [start,end) | peut être négatif.substring |
.substring(start,end) | [start,end) | La valeur négative 0 |
.substr(start,len) | commence depuis start Il existe len | nombreuses |
méthodes de sous-chaîne négatives pour len, il est donc naturellement difficile de choisir. Il est recommandé de se souvenir
.slice(), qui est plus flexible que les deux autres.
Nous avons déjà mentionné la comparaison des chaînes dans l'article précédent. Les chaînes sont triées dans l'ordre du dictionnaire. Derrière chaque caractère se trouve un code, et le code ASCII est une référence importante.
Par exemple :
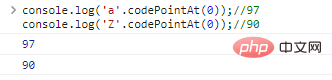
console.log('a'>'Z');// La comparaison entre les vrais caractères est essentiellement une comparaison entre les encodages représentant les caractères. JavaScript utilise UTF-16 pour encoder les chaînes. Chaque caractère est un code 16 bits. Si vous souhaitez connaître la nature de la comparaison, vous devez utiliser .codePointAt(idx) pour obtenir l'encodage des caractères :
console.log('a. '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 résultats d'exécution de code :
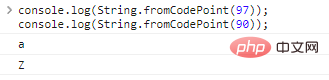
Utilisez String.fromCodePoint(code) pour convertir l'encodage en caractères :
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
Les résultats de l'exécution du code sont les suivants :
Ce processus peut être réalisé en utilisant le caractère d'échappement u , comme suit :
console.log('u005a');//Z, 005a est la notation hexadécimale de 90 console.log('u0061');//a, 0061 C'est la notation hexadécimale de 97. Explorons les caractères codés dans la plage [65,220] :
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); Les résultats de la partie exécution du code sont les suivants :

L'image ci-dessus ne montre pas tous les résultats, alors essayez-la.
est basé sur la norme internationale ECMA-402 . JavaScript a implémenté une méthode spéciale ( .localeCompare() ) pour comparer différentes chaînes, en utilisant str1.localeCompare(str2) :
str1 < str2 , renvoie un nombre négatif ;str1 > str2 , renvoie un nombre positif ;str1 == str2 , renvoie 0 ;par exemple :
console.log("abc".localeCompare('def'));//-1 Pourquoi ne pas utiliser directement les opérateurs de comparaison ?
En effet, les caractères anglais ont des façons d'écrire spéciales. Par exemple, á est une variante de a :
console.log('á' < 'z');// Bien que false soit aussi a , il est plus grand que z ! !
À ce stade, vous devez utiliser .localeCompare() :
console.log('á'.localeCompare('z'));//-1 str.trim() supprime les caractères d'espacement avant et après le
str.repeat(n)
str.trimStart() str.trimEnd() les espaces au début et à la fin ;
let str = " 999 " ; console.log(str.trim());
la chaîne n fois ;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) remplace la première sous-chaîne, str.replaceAll() est utilisé pour tout remplacer sous-chaînes ;
laissez str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6est toujours Il existe de nombreuses autres méthodes et nous pouvons consulter le manuel pour plus de connaissances.
JavaScript utilise UTF-16 pour coder les chaînes, c'est-à-dire que deux octets ( 16 bits) sont utilisés pour représenter un caractère. Cependant, les données 16 bits ne peuvent représenter que 65536 caractères. les caractères courants ne sont naturellement pas inclus. C'est facile à comprendre, mais ce n'est pas suffisant pour les caractères rares (chinois), emoji , les symboles mathématiques rares, etc.
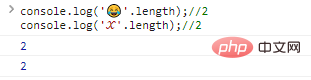
Dans ce cas, vous devez développer et utiliser des chiffres plus longs ( 32 bits) pour représenter les caractères spéciaux, par exemple :
console.log(''.length);//2console.log('?'.length);//2 code Résultat de l'exécution :
Le résultat est que nous ne pouvons pas les traiter en utilisant les méthodes conventionnelles. Que se passe-t-il si nous produisons chaque octet individuellement ?
console.log(''[0]);console.log(''[1]); Résultats de l'exécution du code :
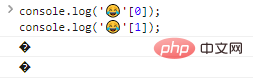
Comme vous pouvez le constater, les octets de sortie individuels ne sont pas reconnus.
Heureusement, String.fromCodePoint() et .codePointAt() peuvent gérer cette situation car elles ont été ajoutées récemment. Dans les anciennes versions de JavaScript , vous ne pouvez utiliser que String.fromCharCode() et .charCodeAt() pour convertir les encodages et les caractères, mais elles ne conviennent pas aux caractères spéciaux.
Nous pouvons traiter les caractères spéciaux en évaluant la plage de codage d'un caractère pour déterminer s'il s'agit d'un caractère spécial. Si le code d'un caractère est compris entre 0xd800~0xdbff , alors c'est la première partie du caractère 32 bits et sa deuxième partie doit être comprise entre 0xdc00~0xdfff .
Par exemple :
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02 résultat de l'exécution du code :

En anglais, il existe de nombreuses variantes basées sur les lettres, par exemple : la lettre a peut être le caractère de base de àáâäãåā . Tous ces symboles de variantes ne sont pas stockés dans le codage UTF-16 car il existe trop de combinaisons de variantes.
Afin de prendre en charge toutes les combinaisons de variantes, plusieurs caractères Unicode sont également utilisés pour représenter un seul caractère variante. Au cours du processus de programmation, nous pouvons utiliser des caractères de base plus des « symboles décoratifs » pour exprimer des caractères spéciaux :
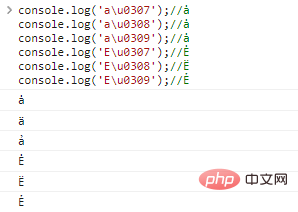
console.log('au0307') . );//ȧ
console.log('au0308');//ȧ
console.log('au0309');//ȧ
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');// ẺRésultats de l'exécution du code :
Une lettre de base peut également avoir plusieurs décorations, par exemple :
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');// Ẹ̇Résultats de l'exécution du code :
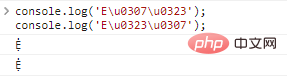
Il y a ici un problème. Dans le cas de décorations multiples, les décorations sont ordonnées différemment, mais les caractères réellement affichés sont les mêmes.
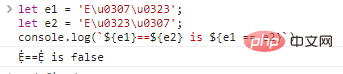
Si l'on compare directement ces deux représentations, on obtient un résultat erroné :
soit e1 = 'Eu0307u0323' ;
soit e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`) résultats de l'exécution du code :
Afin de résoudre cette situation, il existe un algorithme de normalisation ** Unicode qui peut convertir la chaîne dans un format universel **, implémenté par str.normalize() :
let e1 = 'Eu0307u0323';
soit e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} est ${e1.normalize() == e2.normalize()}`)
Résultats de l'exécution du code :

[Recommandations associées : didacticiels vidéo JavaScript, front-end Web]
Ce qui précède est le contenu détaillé des méthodes de base courantes des chaînes JavaScript. Pour plus d'informations, veuillez prêter attention aux autres articles connexes sur le site Web PHP chinois !