
Avant d'étudier le contenu de cet article, nous devons d'abord comprendre le concept d'asynchrone. La première chose à souligner est qu'il existe une différence essentielle entre asynchrone et parallèle .
Le parallélisme fait généralement référence au calcul parallèle, ce qui signifie que plusieurs instructions sont exécutées en même temps. Ces instructions peuvent être exécutées sur plusieurs cœurs du même CPU , ou sur plusieurs CPU , ou sur plusieurs hôtes physiques ou même sur plusieurs réseaux.
La synchronisation fait généralement référence à l'exécution de tâches dans un ordre prédéterminé. Ce n'est que lorsque la tâche précédente est terminée que la tâche suivante sera exécutée.
Asynchrone, correspondant à la synchronisation, signifie que CPU met temporairement de côté la tâche en cours, traite d'abord la tâche suivante, puis revient à la tâche précédente pour continuer l'exécution après avoir reçu la notification de rappel de la tâche précédente. L'ensemble du processus ne nécessite pas de rappel . deuxième fil participer .
Il est peut-être plus intuitif d'expliquer le parallélisme, la synchronisation et l'asynchrone sous forme d'images. Supposons qu'il y ait deux tâches A et B qui doivent être traitées. Les méthodes de traitement parallèle, synchrone et asynchrone adopteront les méthodes d'exécution comme indiqué dans le. figure suivante :
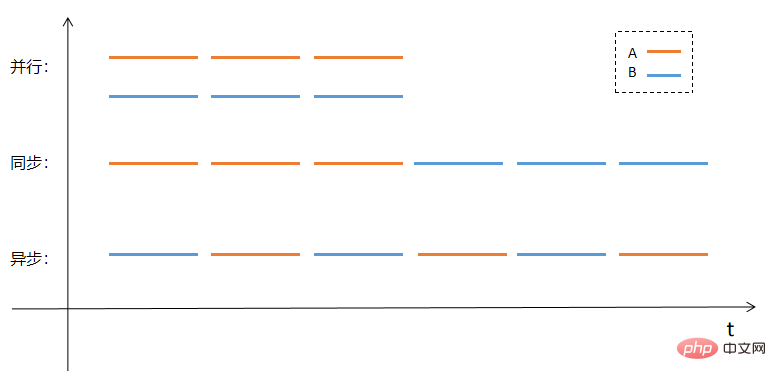
JavaScript nous fournit de nombreuses fonctions asynchrones.Ces fonctions nous permettent d'exécuter facilement des tâches asynchrones, c'est-à-dire que nous commençons à exécuter une tâche (fonction) maintenant, mais la tâche sera terminée plus tard, et dans un délai précis. n'est pas Je ne suis pas sûr.
Par exemple, la fonction setTimeout est une fonction asynchrone très typique. De plus, fs.readFile et fs.writeFile sont également des fonctions asynchrones.
Nous pouvons définir nous-mêmes un cas de tâche asynchrone, comme la personnalisation d'une fonction de copie de fichier copyFile(from,to) :
const fs = require('fs')function copyFile(from, to) {
fs.readFile(from, (erreur, données) => {
si (erreur) {
console.log(err.message)
retour
}
fs.writeFile(to, data, (err) => {
si (erreur) {
console.log(err.message)
retour
}
console.log('Copie terminée')
})
})} La fonction copyFile lit d'abord les données du fichier à partir du paramètre from , puis écrit les données dans le fichier pointé par le paramètre to .
Nous pouvons appeler copyFile comme ceci :
copyFile('./from.txt','./to.txt')//Copier le fichier S'il y a un autre code après copyFile(...) à ce moment, le programme ne le fera pas wait L'exécution de copyFile se termine, mais il s'exécute directement vers le bas. Le programme ne se soucie pas de la fin de la tâche de copie de fichier.
copyFile('./from.txt','./to.txt')//Le code suivant n'attendra pas la fin de l'exécution du code ci-dessus... A ce stade, tout semble être normal, mais si we Que se passe-t-il si vous accédez directement au contenu du fichier ./to.txt après la fonction copyFile(...) ?
Cela ne lira pas le contenu copié, juste comme ceci :
copyFile('./from.txt','./to.txt')fs.readFile('./to.txt',(err,data)= >{
...}) Si le fichier ./to.txt n'a pas été créé avant l'exécution du programme, vous obtiendrez l'erreur suivante :
PS E:CodeNodedemos�3-callback> node .index.js fini Copie terminée PS E:CodeNodedemos�3-callback> nœud .index.js Erreur : ENOENT : aucun fichier ou répertoire de ce type, ouvrez 'E:CodeNodedemos�3-callbackto.txt'Copie terminée
Même si ./to.txt existe, le contenu copié ne peut pas être lu.
La raison de ce phénomène est la suivante : copyFile(...) est exécuté de manière asynchrone. Une fois que le programme a exécuté copyFile(...) , il n'attend pas que la copie soit terminée, mais l'exécute directement vers le bas, provoquant le fichier. apparaître. L'erreur ./to.txt n'existe pas, ou le contenu du fichier est une erreur vide (si le fichier est créé à l'avance).
L'heure de fin d'exécution spécifique de la fonction asynchrone de la fonction de rappel ne peut pas être déterminée. Par exemple, l'heure de fin d'exécution de readFile(from,to) dépend très probablement de la taille du fichier from .
La question est donc de savoir comment localiser avec précision la fin de l’exécution copyFile et lire le contenu du fichier to ?
Cela nécessite l'utilisation d'une fonction de rappel. Nous pouvons modifier la fonction copyFile comme suit :
function copyFile(from, to, callback) {
fs.readFile(from, (erreur, données) => {
si (erreur) {
console.log(err.message)
retour
}
fs.writeFile(to, data, (err) => {
si (erreur) {
console.log(err.message)
retour
}
console.log('Copie terminée')
callback()//La fonction de rappel est appelée lorsque l'opération de copie est terminée})
})} De cette façon, si nous devons effectuer certaines opérations immédiatement après la fin de la copie du fichier, nous pouvons écrire ces opérations dans la fonction de rappel :
function copyFile(from, to, callback) {
fs.readFile(from, (erreur, données) => {
si (erreur) {
console.log(err.message)
retour
}
fs.writeFile(to, data, (err) => {
si (erreur) {
console.log(err.message)
retour
}
console.log('Copie terminée')
callback()//La fonction de rappel est appelée lorsque l'opération de copie est terminée})
})}copyFile('./from.txt', './to.txt', function () {
// Passer une fonction de rappel, lire le contenu du fichier "to.txt" et afficher fs.readFile('./to.txt', (err, data) => {
si (erreur) {
console.log(err.message)
retour
}
console.log(data.toString())
})}) Si vous avez préparé le fichier ./from.txt , alors le code ci-dessus peut être exécuté directement :
PS E:CodeNodedemos�3-callback> node .index.js Copie terminée Rejoignez la communauté "Xianzong" et cultivez l'immortalité avec moi. Adresse de la communauté : http://t.csdn.cn/EKf1h
Cette méthode de programmation est appelée style de programmation asynchrone "basé sur le rappel". Les fonctions exécutées de manière asynchrone doivent fournir un rappel. utilisé pour appeler après la fin de la tâche.
Ce style est courant dans la programmation JavaScript . Par exemple, les fonctions de lecture de fichiers fs.readFile et fs.writeFile sont toutes des fonctions asynchrones.
La fonction de rappel peut gérer avec précision les questions ultérieures une fois le travail asynchrone terminé. Si nous devons effectuer plusieurs opérations asynchrones en séquence, nous devons imbriquer la fonction de rappel.
Scénario de cas :
implémentation de code pour lire le fichier A et le fichier B dans l'ordre :
fs.readFile('./A.txt', (err, data) => {
si (erreur) {
console.log(err.message)
retour
}
console.log('Lire le fichier A : ' + data.toString())
fs.readFile('./B.txt', (erreur, données) => {
si (erreur) {
console.log(err.message)
retour
}
console.log("Lire le fichier B : " + data.toString())
})}) Effet d'exécution :
PS E:CodeNodedemos�3-callback> node .index.js Lire le fichier A : Immortal Sect est infiniment bon, mais il manque quelqu'un. Lecture du fichier B : Si vous souhaitez rejoindre Immortal Sect, vous devez avoir le lien http://t.csdn.cn/H1faI.
Grâce au rappel, vous pouvez lire. le fichier. Après A, le fichier B est lu immédiatement.
Et si nous voulions continuer à lire le fichier C après le fichier B ? Cela nécessite de continuer à imbriquer les rappels :
fs.readFile('./A.txt', (err, data) => {//Premier rappel if (err) {
console.log(err.message)
retour
}
console.log('Lire le fichier A : ' + data.toString())
fs.readFile('./B.txt', (err, data) => {//Deuxième rappel if (err) {
console.log(err.message)
retour
}
console.log("Lire le fichier B : " + data.toString())
fs.readFile('./C.txt',(err,data)=>{//Le troisième rappel...
})
})}) En d'autres termes, si nous voulons effectuer plusieurs opérations asynchrones en séquence, nous avons besoin de plusieurs niveaux de rappels imbriqués. Ceci est efficace lorsque le nombre de niveaux est petit, mais lorsqu'il y a trop de temps d'imbrication, certains problèmes surviendront. se poser.
Conventions de rappel
En fait, le style des fonctions de rappel dans fs.readFile n'est pas une exception, mais une convention courante en JavaScript . Nous personnaliserons un grand nombre de fonctions de rappel à l'avenir, et nous devons respecter cette convention et prendre de bonnes habitudes de codage.
La convention est la suivante :
callback est réservé à l'erreur. Une fois qu'une erreur se produit, callback(err) sera appelé.callback(null, result1, result2,...) sera appelé.Sur la base de la convention ci-dessus, une fonction de rappel a deux fonctions : la gestion des erreurs et la réception des résultats. Par exemple, la fonction de rappel de fs.readFile('...',(err,data)=>{}) suit cette convention.
Si nous n'approfondissons pas, le traitement de méthode asynchrone basé sur les rappels semble être un moyen assez parfait de le gérer. Le problème est que si nous avons un comportement asynchrone après l'autre, le code ressemblera à ceci :
fs.readFile('./a.txt',(err,data)=>{
si(erreur){
console.log(err.message)
retour
}
//Lire l'opération de résultat fs.readFile('./b.txt',(err,data)=>{
si(erreur){
console.log(err.message)
retour
}
//Lire l'opération de résultat fs.readFile('./c.txt',(err,data)=>{
si(erreur){
console.log(err.message)
retour
}
//Lire l'opération de résultat fs.readFile('./d.txt',(err,data)=>{
si(erreur){
console.log(err.message)
retour
}
...
})
})
})}) Le contenu d'exécution du code ci-dessus est :
À mesure que le nombre d'appels augmente, le niveau d'imbrication du code devient de plus en plus profond, incluant de plus en plus d'instructions conditionnelles, ce qui entraîne un code confus qui est constamment en retrait vers la droite, ce qui le rend difficile à lire et à lire. maintenir.
Nous appelons ce phénomène de croissance continue vers la droite (indentation à droite) « l'enfer du rappel » ou « pyramide du malheur » !
fs.readFile('a.txt',(err,data)=>{
fs.readFile('b.txt',(err,data)=>{
fs.readFile('c.txt',(err,data)=>{
fs.readFile('d.txt',(err,data)=>{
fs.readFile('e.txt',(err,data)=>{
fs.readFile('f.txt',(err,data)=>{
fs.readFile('g.txt',(err,data)=>{
fs.readFile('h.txt',(err,data)=>{
...
/*
Porte de l'Enfer ===>
*/
})
})
})
})
})
})
})}) Bien que le code ci-dessus semble assez régulier, il ne s'agit que d'une situation idéale, par exemple. Il existe généralement un grand nombre d'instructions conditionnelles, d'opérations de traitement de données et d'autres codes dans la logique métier, ce qui perturbe le bel ordre actuel et rend le changement de code est difficile à maintenir.
Heureusement, JavaScript nous offre plusieurs solutions, et Promise est la meilleure solution.