Hier, un ami m'a demandé comment déployer le projet express. J'ai donc compilé cet article, qui explique principalement comment déployer un programme serveur développé sur la base de nodejs pour la référence des amis dans le besoin.
L'article contient plusieurs parties :
processus (processus) est l'ordinateur Allocation du système d'exploitation et Unité de base des tâches de planification . Ouvrez le gestionnaire de tâches et vous pouvez voir qu'il existe en fait de nombreux programmes exécutés en arrière-plan de l'ordinateur et que chaque programme est un processus.

Les navigateurs modernes ont essentiellement une architecture multi-processus. En prenant le navigateur Chrome comme exemple, ouvrez "Plus d'outils" - "Gestionnaire des tâches" et vous pourrez voir les informations de processus du navigateur actuel. L'une des pages est un processus, à l'exception de. De plus, il existe des processus réseau, des processus GPU, etc.

L'architecture multi-processus assure un fonctionnement plus stable de l'application. En prenant le navigateur comme exemple, si tous les programmes s'exécutent en un seul processus, s'il y a une panne de réseau ou une erreur de rendu de page, cela entraînera le crash de l'ensemble du navigateur. Grâce à l'architecture multi-processus, même si le processus réseau tombe en panne, cela n'affectera pas l'affichage des pages existantes et, dans le pire des cas, il sera temporairement incapable d'accéder au réseau.
Un thread est la plus petite unité que le système d'exploitation peut effectuer en matière de planification informatique . Il est inclus dans le processus et constitue la véritable unité opérationnelle du processus. Par exemple, un programme est comme une entreprise avec plusieurs départements, qui sont des processus ; la coopération de chaque département permet à l'entreprise de fonctionner normalement, et les fils conducteurs sont les employés, les personnes qui effectuent le travail spécifique.
Nous savons tous que JavaScript est un langage monothread. Cette conception est due au fait qu'au début, JS était principalement utilisé pour écrire des scripts et était chargé de réaliser les effets interactifs de la page. S'il est conçu comme un langage multithread, d'une part, ce n'est pas nécessaire, et d'autre part, plusieurs threads exploitent conjointement un nœud DOM, alors quels conseils le navigateur doit-il écouter ? Bien entendu, avec le développement de la technologie, JS prend désormais également en charge le multithreading, mais il n'est utilisé que pour gérer certaines logiques sans rapport avec les opérations DOM.
Les threads uniques et les processus uniques posent un problème sérieux. Une fois que le thread principal d'un programme node.js en cours d'exécution raccroche, le processus raccroche également et l'application entière raccroche également. De plus, la plupart des ordinateurs modernes disposent de processeurs multicœurs, avec quatre cœurs et huit threads, et huit cœurs et seize threads, qui sont des périphériques très courants. En tant que programme à processus unique, node.js gaspille les performances des processeurs multicœurs.
En réponse à cette situation, nous avons besoin d'un modèle multi-processus approprié pour transformer un programme node.js mono-processus en une architecture multi-processus.
Il existe deux solutions courantes pour implémenter une architecture multi-processus dans Node.js, qui utilisent toutes deux des modules natifs, à savoir le module child_process et le module cluster .
child_process est un module intégré de node.js. Vous pouvez deviner d'après son nom qu'il est responsable des éléments liés aux processus enfants.
Nous ne détaillerons pas l'utilisation spécifique de ce module. En fait, il ne comporte qu'environ six ou sept méthodes, qui restent très simples à comprendre. Nous utilisons l'une des méthodes fork pour démontrer comment implémenter plusieurs processus et la communication entre plusieurs processus.
Examinons d'abord la structure des répertoires du cas de démonstration préparé :

Nous utilisons le module http pour créer un serveur http. Lorsqu'une requête /sum arrive, un processus enfant sera créé via le module child_process et le processus enfant sera averti pour effectuer la logique de calcul en même temps que le processus parent. doit également écouter les messages envoyés par le processus enfant :
/ /child_process.js
const http = exiger('http')
const { fork } = require('child_process')
const serveur = http.createServer((req, res) => {
if (req.url == '/somme') {
// La méthode fork reçoit un chemin de module, puis démarre un processus enfant et exécute le module dans le processus enfant // childProcess représente le processus enfant créé let childProcess = fork('./sum.js')
//Envoyer un message au processus enfant childProcess.send('Le processus enfant commence à calculer')
// Surveiller les messages du processus enfant dans le processus parent childProcess.on('message', (data) => {
res.end(données + '')
})
//Écoutez l'événement de clôture du processus enfant childProcess.on('close', () => {
// Si le processus enfant se termine normalement ou signale une erreur et raccroche, il ira ici console.log('le processus enfant se ferme')
enfantProcess.kill()
})
//Écoutez l'événement d'erreur du processus enfant childProcess.on('error', () => {
console.log('erreur de processus enfant')
enfantProcess.kill()
})
}
if (req.url == '/bonjour') {
res.end('bonjour')
}
// Simuler le processus parent pour signaler une erreur if (req.url == '/error') {
lancer une nouvelle erreur ('Erreur du processus parent')
res.end('bonjour')
}
})
serveur.écouter(3000, () => {
console.log('Le serveur fonctionne sur 3000')
}) sum.js est utilisé pour simuler les tâches à effectuer par le processus enfant. Le processus enfant écoute les messages envoyés par le processus parent, traite les tâches de calcul, puis envoie les résultats au processus parent :
// sum.js
fonction getSomme() {
soit somme = 0
pour (soit i = 0; i < 10000 * 1000 * 100; i++) {
somme += 1
}
somme de retour
}
// le processus est un objet global dans node.js, représentant le processus actuel. Ici, c'est le processus enfant.
// Écoute les messages envoyés par le processus principal process.on('message', (data) => {
console.log('Message du processus principal :', données)
résultat const = getSum()
//Envoyer les résultats du calcul au processus parent process.send(result)
}) Ouvrez le terminal et exécutez la commande node 1.child_process :

Visitez le navigateur :

Ensuite, simulez la situation où le processus enfant signale une erreur :
// sum.js
fonction getSomme() {
//....
}
// Après 5 secondes d'exécution du processus enfant, le processus de simulation raccroche setTimeout(() => {
lancer une nouvelle erreur ("rapport d'erreur")
}, 1000 * 5)
process.on('message', (données) => {
//...
}) Visitez à nouveau le navigateur et observez la console après 5 secondes :

Le processus enfant est mort, puis accède à une autre URL : /hello ,

On peut voir que le processus parent peut toujours traiter la demande correctement, ce qui indique que l'erreur signalée par le processus enfant n'affectera pas le fonctionnement du processus parent .
Ensuite, nous allons simuler le scénario dans lequel le processus parent signale une erreur, commenter le rapport d'erreur simulé du module sum.js , puis redémarrer le service et accéder à /error avec le navigateur :

Après avoir découvert que le processus parent avait raccroché, l'ensemble du programme node.js s'est automatiquement fermé et le service s'est complètement effondré, ne laissant aucune place à la récupération.
On peut voir qu'il n'est pas compliqué d'implémenter l'architecture multi-processus de node.js via fork de child_process . La communication inter-processus s'effectue principalement via send et on . À partir de cette dénomination, nous pouvons également savoir que la couche inférieure doit être un modèle de publication-abonnement.
Mais il y a un problème sérieux. Bien que le processus enfant n'affecte pas le processus parent, une fois que le processus parent fait une erreur et raccroche, tous les processus enfants seront « tués dans un seul pot ». Par conséquent, cette solution convient pour regrouper certaines opérations complexes et fastidieuses dans un sous-processus distinct . Pour être plus précis, cet usage est utilisé pour remplacer la mise en œuvre du multi-threading et non du multi-traitement.
utilise le module child_process pour implémenter le multi-processus, ce qui semble inutile. Par conséquent, il est généralement recommandé d'utiliser le module cluster pour implémenter le modèle multi-processus de node.js.
cluster signifie cluster. Je pense que tout le monde connaît ce terme. Par exemple, dans le passé, l’entreprise n’avait qu’une seule réception, et parfois elle était trop occupée pour recevoir les visiteurs à temps. L'entreprise s'est désormais dotée de quatre bureaux d'accueil, même si trois sont occupés, il en reste un qui peut accueillir de nouveaux visiteurs. Le clustering signifie en gros ceci. Pour la même chose, il est raisonnablement confié à différentes personnes de le faire, afin de garantir que la chose peut être faite au mieux.
L'utilisation du module cluster est également relativement simple. Si le processus actuel est le processus principal, créez un nombre approprié de sous-processus en fonction du nombre de cœurs de processeur et écoutez l'événement exit du sous-processus. Si un sous-processus se termine, recréez le nouveau sous-processus. -processus. S'il ne s'agit pas d'un processus enfant, l'activité réelle est traitée.
const http = exiger('http')
const cluster = exiger('cluster')
const cpus = require('os').cpus()
si (cluster.isMaster) {
// Lorsque le programme démarre, il va d'abord ici et crée plusieurs sous-processus en fonction du nombre de cœurs de processeur pour (soit i = 0; i < cpus.length; i++) {
//Créer un processus enfant cluster.fork()
}
// Lorsqu'un processus enfant raccroche, le module cluster émettra l'événement 'exit'. À ce stade, le processus est redémarré en appelant à nouveau fork.
cluster.on('exit', () => {
cluster.fork()
})
} autre {
// La méthode fork s'exécute pour créer un processus enfant, et le module sera à nouveau exécuté à ce moment-là, la logique viendra ici const server = http.createServer((req, res) => {.
console.log(process.pid)
res.end('ok')
})
serveur.écouter(3000, () => {
console.log('Le serveur fonctionne sur 3000', 'pid : ' + process.pid)
})
} Démarrez le service :

Comme vous pouvez le constater, le module cluster a créé de nombreux processus enfants et il semble que chaque processus enfant exécute le même service Web.
Il convient de noter que ces processus enfants n’écoutent pas le même port pour le moment. Le serveur créé par la méthode createServer est toujours responsable de la surveillance des ports et transmet les requêtes à chaque processus enfant.
Écrivons un script de requête pour demander le service ci-dessus et voyons l'effet.
// requête.js
const http = exiger('http')
pour (soit i = 0; i < 1000; i++) {
http.get('http://localhost:3000')
} Le module http peut non seulement créer un serveur http, mais peut également être utilisé pour envoyer des requêtes http. Axios prend en charge les environnements de navigateur et de serveur côté serveur, le module http est utilisé pour envoyer des requêtes http.
Utilisez node pour exécuter le fichier et regardez la console d'origine :

Les ID de processus des différents sous-processus qui gèrent spécifiquement la demande sont imprimés.
Il s'agit de l'architecture multi-processus de nodd.js implémentée via le module cluster .
Bien sûr, lorsque nous déployons des projets node.js, nous n'écrirons et n'utiliserons pas le module cluster aussi sèchement. Il existe un outil très utile appelé PM2 , qui est un outil de gestion de processus basé sur le module cluster. Son utilisation de base sera présentée dans les chapitres suivants.
Jusqu'à présent, nous avons consacré une partie de l'article à présenter les connaissances multi-processus dans node.js. En fait, nous voulons simplement expliquer pourquoi nous devons utiliser pm2 pour gérer les applications node.js. En raison de l'espace limité de cet article et du manque de description précise/détaillée, cet article ne donne qu'une brève introduction. Si c’est la première fois que vous entrez en contact avec ce contenu, vous ne le comprendrez peut-être pas très bien, alors ne vous inquiétez pas, il y aura un article plus détaillé plus tard.
Cet article a préparé un exemple de programme développé à l'aide d'express, cliquez ici pour y accéder.
Il implémente principalement un service d'interface lors de l'accès à /api/users , mockjs est utilisé pour simuler 10 éléments de données utilisateur et renvoyer une liste d'utilisateurs. En même temps, un timer sera démarré pour simuler une situation d'erreur :
const express = require('express')
const Mock = require('mockjs')
const application = express()
app.get("/api/users", (req, res) => {
const userList = Mock.mock({
'liste d'utilisateurs|10' : [{
'identifiant|+1' : 1,
'nom' : '@cname',
'email' : '@email'
}]
})
setTimeout(()=> {
lancer une nouvelle erreur (« Échec du serveur »)
}, 5000)
res.statut(200)
res.json (liste d'utilisateurs)
})
app.écouter(3000, () => {
console.log("Service démarré : 3000")
}) Testez-le localement et exécutez la commande dans le terminal :
node server.js
Ouvrez le navigateur et accédez à l'interface de la liste des utilisateurs :

Après cinq secondes, le serveur se bloquera :
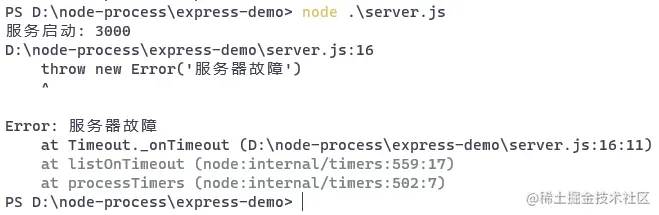
Nous pourrons résoudre ce problème plus tard lorsque nous utiliserons pm2 pour gérer les applications.
Habituellement, après avoir terminé un projet vue/react, nous le conditionnerons d'abord, puis le publierons. En fait, les projets frontaux doivent être empaquetés principalement parce que l'environnement d'exécution final du programme est le navigateur, et le navigateur présente divers problèmes de compatibilité et de performances, tels que :
.vue , .jsx , .ts doivent être compilésLes projets développés avec express.js ou koa.js n'ont pas ces problèmes. De plus, Node.js adopte la spécification modulaire CommonJS et dispose d'un mécanisme de mise en cache. En même temps, le module ne sera importé que lorsqu'il sera utilisé . Si vous le regroupez dans un fichier, cet avantage est en réalité gaspillé. Ainsi, pour les projets node.js, il n'est pas nécessaire de packager.
Cet article utilise le système CentOS comme exemple pour montrer
Afin de faciliter le changement de version de nœud, nous utilisons nvm pour gérer les nœuds.
Nvm (Node Version Manager) est l'outil de gestion de versions de Node.js. Grâce à lui, le nœud peut être arbitrairement basculé entre plusieurs versions, évitant ainsi les opérations répétées de téléchargement et d'installation lorsqu'un changement de version est nécessaire.
Le référentiel officiel de Nvm est github.com/nvm-sh/nvm. Son script d'installation étant stocké sur le site githubusercontent , il est souvent inaccessible. J'ai donc créé un nouveau référentiel miroir sur gitee, afin de pouvoir accéder à son script d'installation depuis gitee.
Téléchargez le script d'installation via la commande curl et utilisez bash pour exécuter le script, qui terminera automatiquement l'installation de nvm :
# curl -o- https://gitee.com/hsyq/nvm/raw/master/install.sh | bash
Une fois l'installation terminée, nous ouvrons une nouvelle fenêtre pour utiliser nvm :
[root@ecs-221238 ~]# nvm -v0.39.1
peut imprimer le numéro de version normalement, indiquant que nvm a été installé avec succès.
Vous pouvez désormais utiliser nvm pour installer et gérer Node.
Afficher les versions de nœud disponibles :
# nvm ls-remote
Nœud d'installation :
# nvm install 18.0.0
Afficher les versions de nœud installées :
[root@ecs-221238 ~]# nvm list -> v18.0.0 par défaut -> 18.0.0 (-> v18.0.0) iojs -> N/A (par défaut) instable -> N/A (par défaut) nœud -> stable (-> v18.0.0) (par défaut) stable -> 18.0 (-> v18.0.0) (par défaut)
Sélectionnez une version à utiliser :
# nvm use 18.0.0
Une chose à noter est que lorsque vous utilisez nvm sous Windows, vous devez utiliser les droits d'administrateur pour exécuter la commande nvm. Sur CentOS, je me connecte par défaut en tant qu'utilisateur root, il n'y a donc aucun problème. Si vous rencontrez des erreurs inconnues lors de son utilisation, vous pouvez rechercher des solutions ou essayer de voir si le problème est causé par les autorisations.
Lors de l'installation du nœud, npm sera installé automatiquement. Vérifiez les numéros de version de node et npm :
[root@ecs-221238 ~]# node -v v18.0.0 [root@ecs-221238 ~]# npm -v
La source d'image npm par défaut
dans la version 8.6.0est l'adresse officielle :
[root@ecs-221238 ~]# npm config get Registry https://registry.npmjs.org/
Basculez vers la source du miroir Taobao national :
[root@ecs-221238 ~]# npm config set Registry https://registry.npmmirror.com
À ce stade, le serveur a installé le nœud Le l'environnement et npm sont configurés.
Il existe de nombreuses façons, soit en les téléchargeant sur le serveur à partir du référentiel Github/GitLab/Gitee, soit en les téléchargeant localement via l'outil ftp. Les étapes sont très simples et ne seront pas démontrées à nouveau.
Le projet de démonstration est placé dans le répertoire /www :
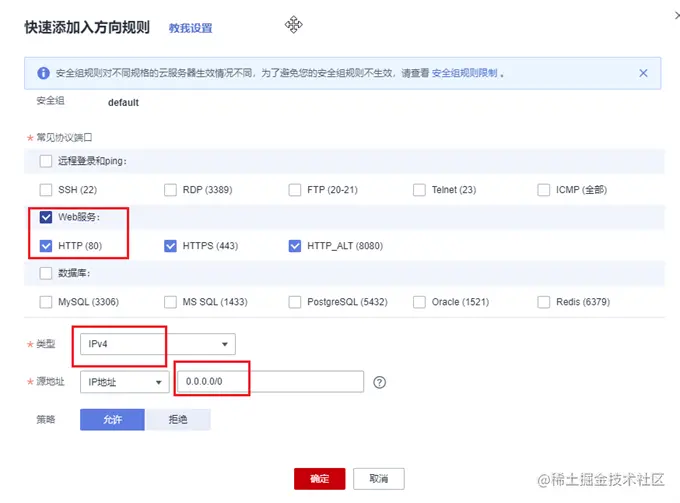
Généralement, les serveurs cloud n'ouvrent que le port 22 pour la connexion à distance. Les ports couramment utilisés tels que 80 et 443 ne sont pas ouverts. De plus, le projet express que nous avons préparé fonctionne sur le port 3000. Vous devez donc d'abord vous rendre sur la console du serveur cloud, rechercher le groupe de sécurité, ajouter quelques règles et ouvrir les ports 80 et 3000.
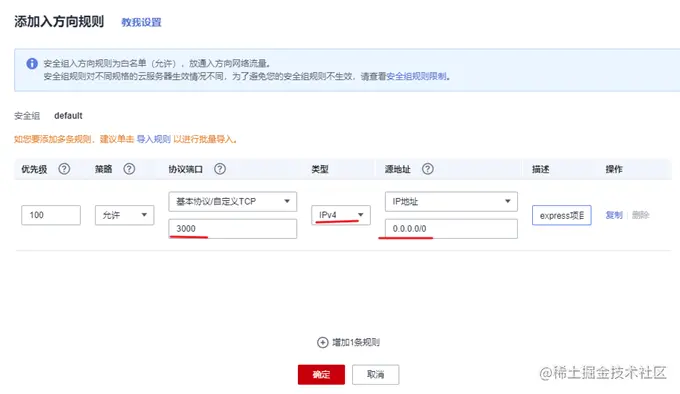
, nous pouvons utiliser nodemon pour la surveillance en temps réel et le redémarrage automatique afin d'améliorer l'efficacité du développement. Dans un environnement de production, vous devez utiliser le grand tueur : PM2.
installez d'abord pm2 globalement :
# npm i -g pm2
Exécutez la commande pm2 -v pour vérifier si l'installation a réussi :
[root@ecs-221238 ~]# pm2 -v5.2.0
Basculez vers le répertoire du projet et installez d'abord les dépendances :
cd /www/express-demo npm install
puis utilisez la commande pm2 pour démarrer l'application.
pm2 démarrer app.js -i max // Ou pm2 start server.js -i 2
L'application de gestion PM2 a deux modes : fork et cluster. Lors du démarrage de l'application, en utilisant le paramètre -i pour spécifier le nombre d'instances, le mode cluster sera automatiquement activé. À ce stade, des capacités d’équilibrage de charge sont disponibles.
-i : instance, le nombre d'instances. Vous pouvez écrire un nombre spécifique ou le configurer au maximum.
PM2vérifiera automatiquement le nombre de processeurs disponibles, puis démarrera autant de processus que possible.
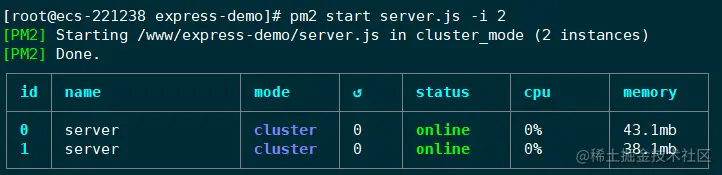
L'application est maintenant lancée. PM2 gérera l'application sous la forme d'un processus démon. Ce tableau affiche des informations sur l'application en cours d'exécution, telles que l'état d'exécution, l'utilisation du processeur, l'utilisation de la mémoire, etc.
Accédez à l'interface dans un navigateur local :

Le mode cluster est un modèle multi-processus et multi-instance Lorsqu'une demande arrive, elle sera affectée à l'un des processus pour traitement. Tout comme l'utilisation cluster que nous avons vu précédemment, en raison de la tutelle de pm2, même si un processus meurt, le processus sera redémarré immédiatement.
Retournez au terminal du serveur et exécutez la commande pm2 logs pour afficher les journaux pm2 :
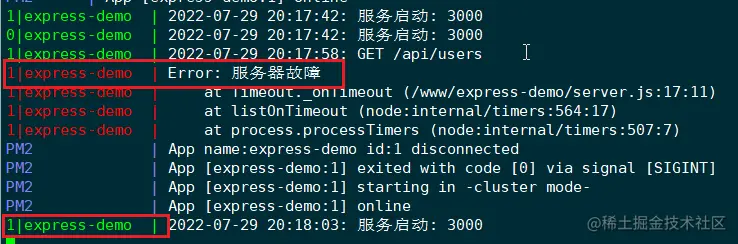
On peut voir que l'instance d'application portant l'ID 1 raccroche et pm2 redémarrera l'instance immédiatement. Notez que l'identifiant ici est l'identifiant de l'instance d'application, et non l'identifiant du processus.
À ce stade, le simple déploiement d’un projet express est terminé. En utilisant l'outil pm2, nous pouvons essentiellement garantir que notre projet peut fonctionner de manière stable et fiable.
Voici un résumé de certaines commandes couramment utilisées de l'outil pm2 à titre de référence.
# Fork mode pm2 start app.js --name app # Définit le nom de l'application sur app #Mode cluster# Utilisez l'équilibrage de charge pour démarrer 4 processus pm2 start app.js -i 4 # Démarrera 4 processus en utilisant l'équilibrage de charge, en fonction du processeur disponible pm2 démarrer app.js -i 0 # Équivalent à l'effet de la commande ci-dessus pm2 start app.js -i max # Développez l'application avec 3 processus supplémentaires pm2 scale app +3 # Développez ou réduisez l'application à 2 processus pm2 scale app 2 # Afficher l'état de l'application # Afficher l'état de tous les processus liste pm2 # Imprimer la liste de tous les processus au format brut JSON pm2 jlist # Utilisez JSON embelli pour imprimer la liste de tous les processus pm2 Prettylist # Afficher toutes les informations sur un processus spécifique pm2 décrire 0 # Utilisez le tableau de bord pour surveiller tous les processus pm2 monit #Gestion des logs# Afficher tous les logs des applications pm2 logs en temps réel # Afficher les journaux d'application de l'application en temps réel # Utilisez le format json pour afficher les journaux en temps réel, ne publiez pas les anciens journaux, affichez uniquement les journaux nouvellement générés pm2 logs --json #Gestion des applications# Arrêter tous les processus pm2 arrêter tout # Redémarrer tous les processus pm2 tout redémarrer # Arrêtez le processus avec l'ID spécifié pm2 stop 0 # Redémarrez le processus avec l'ID spécifié pm2 restart 0 # Supprimer le processus pm2 avec l'ID 0 supprimer 0 # Supprimer tous les processus pm2 supprimer tout
Vous pouvez essayer chaque commande vous-même pour voir l'effet.
Voici une démonstration spéciale de la commande monit , qui permet de lancer un panneau dans le terminal pour afficher l'état d'exécution de l'application en temps réel. Toutes les applications gérées par pm2 peuvent être basculées via les flèches haut et bas :
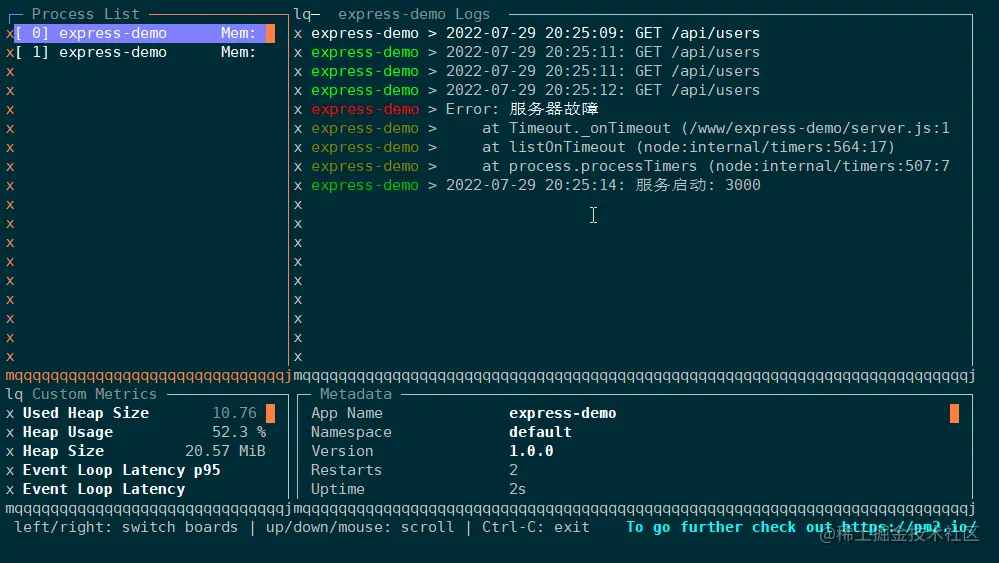
PM2 possède des fonctions très puissantes, bien plus que les commandes ci-dessus. Dans le déploiement d'un projet réel, vous devrez peut-être également configurer les fichiers journaux, le mode de surveillance, les variables d'environnement, etc. Il serait très fastidieux de taper des commandes manuellement à chaque fois, c'est pourquoi pm2 fournit des fichiers de configuration pour gérer et déployer des applications.
Vous pouvez générer un fichier de configuration via la commande suivante :
[root@ecs-221238 express-demo]# pm2 init simple Le fichier /www/express-demo/ecosystem.config.js généré
générera un fichier ecosystem.config.js :
module.exports = {
applications : [{
nom : "app1",
script : "./app.js"
}]
} Vous pouvez également créer vous-même un fichier de configuration, tel que app.config.js :
const path = require('path')
module.exports = {
// Un fichier de configuration peut gérer plusieurs applications node.js en même temps // apps est un tableau, chaque élément est la configuration d'une application apps : [{
//Nom de l'application : "express-demo",
// Script du fichier d'entrée de l'application : "./server.js",
// Il existe deux modes de démarrage de l'application : cluster et fork. La valeur par défaut est fork.
exec_mode : 'cluster',
// Nombre d'instances d'application pour créer des instances : 'max',
// Activer la surveillance et redémarrer automatiquement l'application lorsque le fichier change watch: true,
//Ignore les modifications apportées à certains fichiers de répertoire.
// Puisque le répertoire des journaux est placé dans le chemin du projet, il doit être ignoré, sinon l'application générera des journaux au démarrage, PM2 redémarrera lorsqu'elle surveille les modifications. Si elle redémarre et génère des journaux, elle entrera dans un nombre infini. boucle ignore_watch : [
"noeud_modules",
"journaux"
],
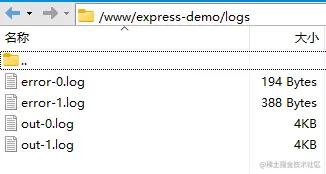
// Chemin de stockage du journal des erreurs err_file : path.resolve(__dirname, 'logs/error.log'),
//Imprimer le chemin de stockage du journal out_file : path.resolve(__dirname, 'logs/out.log'),
//Définissez le format de date devant chaque journal dans le fichier journal log_date_format : "AAAA-MM-JJ HH:mm:ss",
}]
} Laissez pm2 utiliser les fichiers de configuration pour gérer les applications de nœud :
pm2 start app.config.js
Désormais, les applications gérées par pm2 placeront les journaux dans le répertoire du projet (la valeur par défaut est dans le répertoire d'installation de pm2) et pourront surveiller les modifications des fichiers. , redémarrez automatiquement le service.