Un site Web fait référence à un ensemble de pages Web produites à l'aide de HTML et d'autres contenus sur Internet selon certaines règles pour afficher un contenu spécifique.
Une page Web est une « page » dans un site Web. Il s'agit généralement d'un fichier au format HTML, lu par un navigateur.
Une page Web est en fait un fichier placé sur le serveur. Lorsque nous parcourons la page Web, ce fichier est téléchargé sur notre ordinateur local, puis analysé par le navigateur pour afficher diverses belles interfaces, telles que des tableaux, des images, des titres, des listes. etc.
Il existe de nombreux suffixes pour les fichiers de pages Web, tels que .html, .php, .jsp, .asp, etc. Je pense que les lecteurs les ont vus dans la barre d'adresse du navigateur, comme le montre la figure suivante :


L'URL peut être consultée dans la barre d'adresse du navigateur
Mais quel que soit le suffixe de la page Web, son essence est la même, à savoir un fichier texte brut composé de code HTML.
Nous pouvons utiliser des éditeurs de texte tels que Notepad, Notepad++, Sublime Text et Vim pour ouvrir le fichier de la page Web et voir tout son contenu, comme suit :
<!DOCTYPEhtml><html><head><metacharset=UTF-8><title>Cette position est le titre de la page Web</title></head><body><p>Cette position est le texte du contenu de la page Web</p ><ahref=http://dotcpp.com/>Cet emplacement est un lien hypertexte</a><ul><li>Projet 1</li><li>Projet 2</li>< li>Projet 3< /li></ul></body></html>
C'est le code HTML ! Nous pouvons voir de nombreuses balises spéciales entourées de <>, appelées balises HTML. Le navigateur restitue diverses interfaces et effets en reconnaissant ces balises HTML.
Enregistrez le code ci-dessus dans index.html, faites-le glisser vers le navigateur et exécutez-le (ou double-cliquez sur le fichier), vous pouvez voir l'effet suivant :
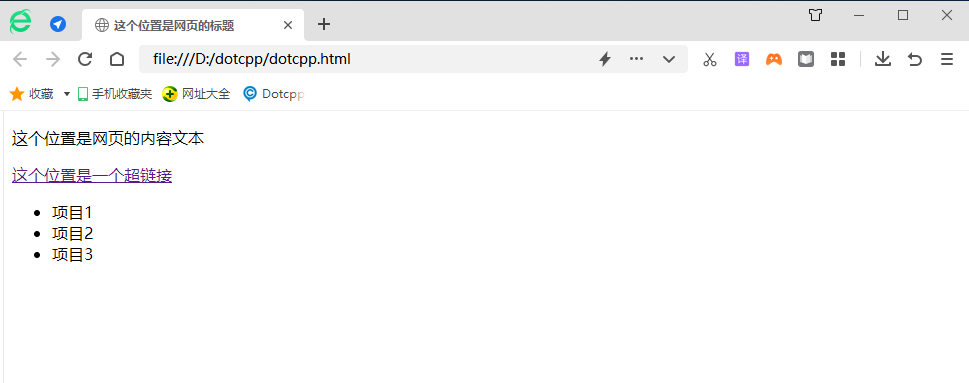
Il s'agit d'une page Web très simple et basique. Elle n'est utilisée qu'à titre d'exemple pour démontrer. Le code HTML d'une vraie page Web est beaucoup plus compliqué que cela. Vous pouvez cliquer avec le bouton droit sur la page Web et sélectionner « Afficher la page Web ». code source" dans le menu contextuel. Vous pouvez afficher le code HTML de la page Web actuelle.
Les pages Web sont identifiées et accessibles via une adresse de site Web (URL). Lorsque nous saisissons l'URL dans le navigateur Web, après un processus complexe et rapide, le fichier de la page Web sera transféré sur l'ordinateur personnel de l'utilisateur, puis le contenu du fichier. La page Web sera interprétée via le navigateur, puis affichée à l'utilisateur.
1. Page Web : Pour parler simplement, du point de vue de l'utilisateur, ce sont les choses que vous voyez, comme Taobao, le réseau en langage C, etc.
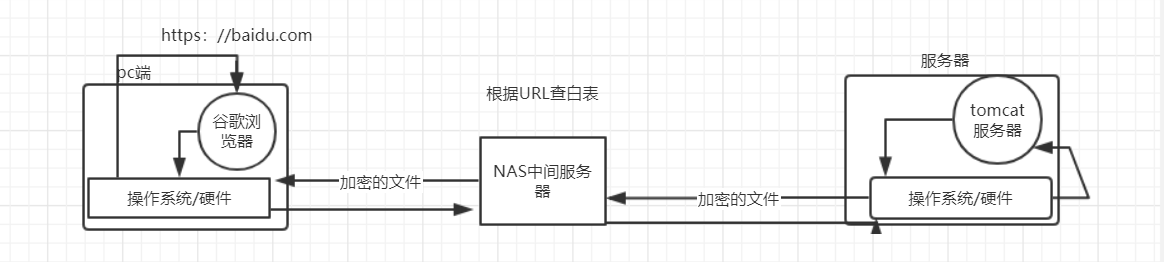
2. Fichiers : Nous savons tous que les fichiers existent dans les ordinateurs. L'image ci-dessous peut vous montrer où se trouvent ces fichiers. Bien sûr, ce n'est qu'un exemple.

● Côté serveur
Il s'agit d'un serveur Tomcat sous Windows et les pages Web que vous parcourez sont enregistrées dans le dossier webapps.
●Du côté du navigateur
Le navigateur est en fait un analyseur, qui analyse principalement les fichiers HTTP, les fichiers CSS et les fichiers JS envoyés depuis le serveur.
C'est en fait très simple. Les pages Web ne sont que des fichiers.
3. Ordinateur : Comme son nom l’indique, un ordinateur est un serveur côté serveur. À quoi ressemble un serveur ? L'image ci-dessous est le serveur, vous pouvez y jeter un œil.

4. Adresse du site Web (URL) :

5. Programmes complexes et rapides : Lorsque le fichier de la page Web est envoyé, il sera traité par ces programmes.
6. Navigateur : le navigateur interprète les trois fichiers reçus via le noyau du navigateur, les restitue dans les pages Web que nous voyons, puis les affiche à l'utilisateur.
7. Résumé en image :
Si vous souhaitez comprendre la structure d'une page Web, vous devez d'abord comprendre l'organisation du W3C.
Consortium World Wide Web (W3C), également connu sous le nom de Conseil du W3C. Fondée en octobre 1994 au laboratoire d'informatique du MIT. Fondé par Tim Berners-Lee, l'inventeur d'Internet.
Presque toutes les normes relatives aux pages Web sont élaborées par cette alliance. Selon ses normes standard de page Web, HTML est la base, les fichiers CSS sont responsables de l'embellissement et JS est responsable des interactions et des actions.
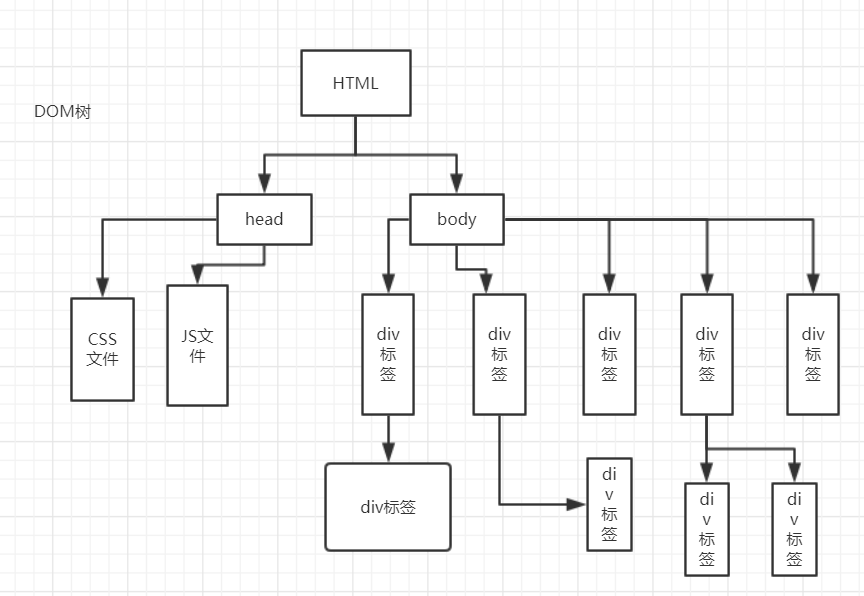
Il s'agit d'une simple arborescence DOM. Nos ressources réseau peuvent être considérées comme chaque pomme de l'arborescence. Organiser les ressources de cette manière améliorera considérablement la vitesse d'analyse du navigateur. Nos relations familiales dans la vie quotidienne peuvent être clairement illustrées par une telle image.