Nous avons exploré toutes les informations de la page Web dans la section précédente. Nous devons maintenant trouver le contenu dont nous avons besoin dans le code HTML. Par conséquent, nous devons entrer dans le site Web en fonction du problème et analyser les informations dans la page Web.
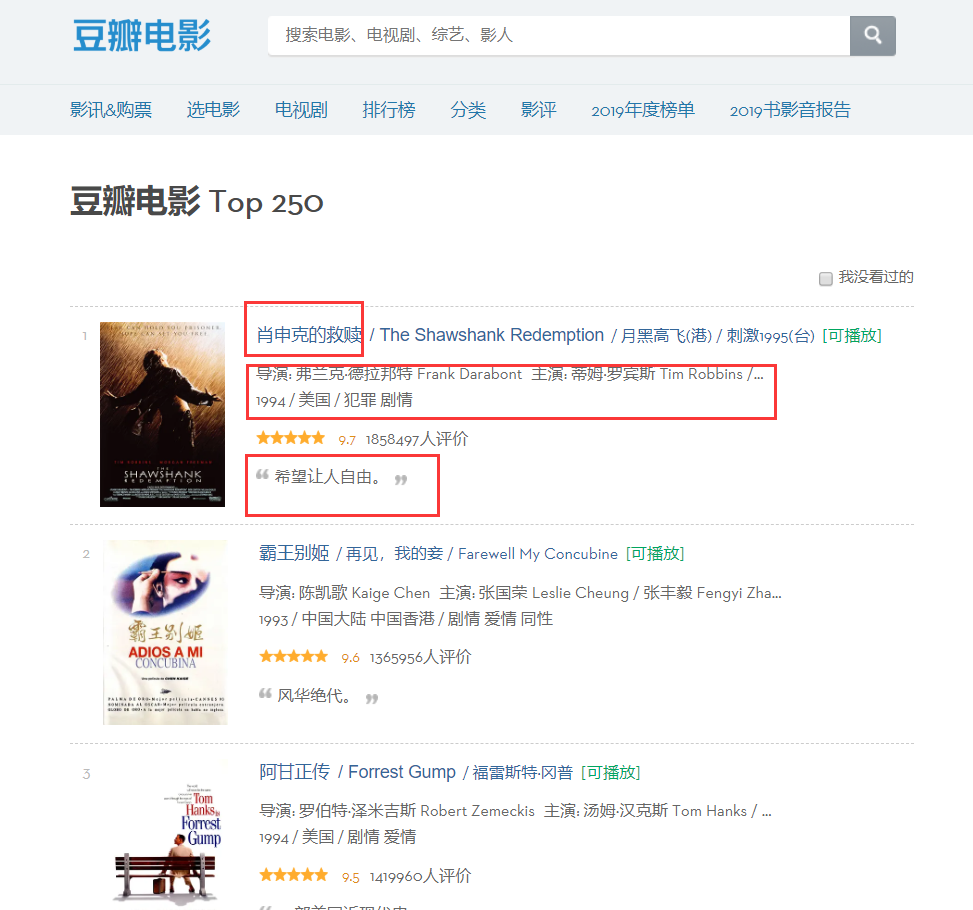
On peut constater sur la page que les informations que nous devons explorer existent dans différentes partitions, vérifions donc les éléments de la page, cliquez avec le bouton droit sur la page pour vérifier le code source de la page Web ou F12.

Avant d'analyser la page Web, nous spécifions d'abord la méthode de stockage après analyse. Ici, nous utilisons une liste pour stocker toutes les informations, puis chaque élément de la liste correspond à un dictionnaire, et chaque dictionnaire correspond à plusieurs types d'informations.
movies=[]#Définissez d’abord une liste pour stocker toutes les informations
Grâce à l'analyse, nous pouvons déterminer que la position du titre est le premier « span » dans le premier « a » sous le « div » nommé « hd », nous pouvons donc verrouiller le nom de chaque film via le code suivant, puis dans un dictionnaire.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#Un élément dans le dictionnaireDe la même manière, le code source du nom du réalisateur peut être trouvé en fonction du positionnement, mais ce code source contient beaucoup d'informations, nous devons donc le filtrer via des expressions régulières.
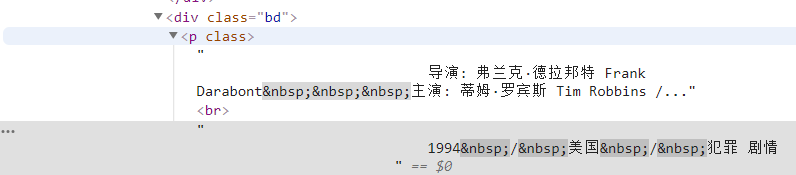
info=each.find('div',class_='bd').p.text.strip()Tout d’abord, nous trouvons tout le contenu sous cette balise, puis filtrons les informations non pertinentes via des expressions régulières.
info=info.replace('n',)#Filtre les retours du chariot info=info.replace(,)#Filtre les espaces info=info.replace(xa0,)#Filtre les caractères d'espacement insécables Director=re.findall( r '[Réalisateur :].+[En vedette :]',info)[0]director=director[3:len(director)-6]Définissez-le ensuite comme élément du dictionnaire.
movie['director']=director#Un élément du dictionnaire
Nous pouvons constater que le type de film se trouve également dans cette balise « p », et nous obtenons également cette information directement via des expressions régulières.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Ajouter comme élément dans le dictionnaireEnfin, verrouillez les informations de notation.
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()Continuez ensuite à le sauvegarder sous forme de dictionnaire.
film['star']=étoile
Enfin, ajoutez ce dictionnaire à la liste et parcourez la sortie.
movies.append(movie)#Ajouter le dictionnaire à la liste des films :#Parcourir la sortie print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simuler le navigateur pour accéder à 'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537.36' , 'Hôte':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 fois r=requests.get(res,headers = headers,timeout=10)#Définissez le délai d'attente soup=BeautifulSoup(r.text,html.parser)#Définissez la méthode d'analyse, d'autres méthodes peuvent également être utilisées. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[Réalisateur :].+[En vedette :]',info)[0]director=director[3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]movie['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0] plot=plot[1:]plot=plot[plot.index('/')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each. find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (je)Console:

Dans cet exemple, nous apprenons principalement comment trouver les informations correspondantes dans le code source de la page Web. BeautifulSoup peut nous aider à les localiser rapidement, puis à les combiner avec des expressions régulières pour compléter la correspondance des informations. enregistrera ces données dans la base de données.