Le dernier modèle de langage multimodal BLIP-3-Video publié par l'équipe de recherche Salesforce AI fournit une solution pour traiter efficacement les données vidéo croissantes. Ce modèle vise à améliorer l'efficacité et l'effet de la compréhension vidéo et est largement utilisé dans des domaines tels que la conduite autonome et le divertissement, apportant l'innovation à tous les horizons. L'éditeur de Downcodes expliquera en détail la technologie de base et les excellentes performances de BLIP-3-Video.
Récemment, l'équipe de recherche Salesforce AI a lancé un nouveau modèle de langage multimodal, BLIP-3-Video. Avec l’augmentation rapide du contenu vidéo, le traitement efficace des données vidéo est devenu un problème urgent à résoudre. L'émergence de ce modèle vise à améliorer l'efficience et l'efficacité de la compréhension vidéo et convient à diverses industries, de la conduite autonome au divertissement.
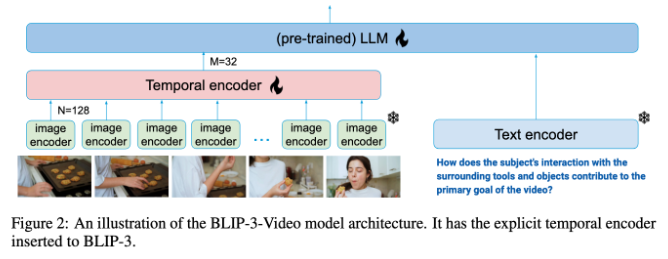
Les modèles traditionnels de compréhension vidéo traitent souvent les vidéos image par image et génèrent une grande quantité d’informations visuelles. Ce processus consomme non seulement beaucoup de ressources informatiques, mais limite également considérablement la capacité de traiter de longues vidéos. À mesure que la quantité de données vidéo continue de croître, cette approche devient de plus en plus inefficace. Il est donc essentiel de trouver une solution capable de capturer les informations clés de la vidéo tout en réduisant la charge de calcul.
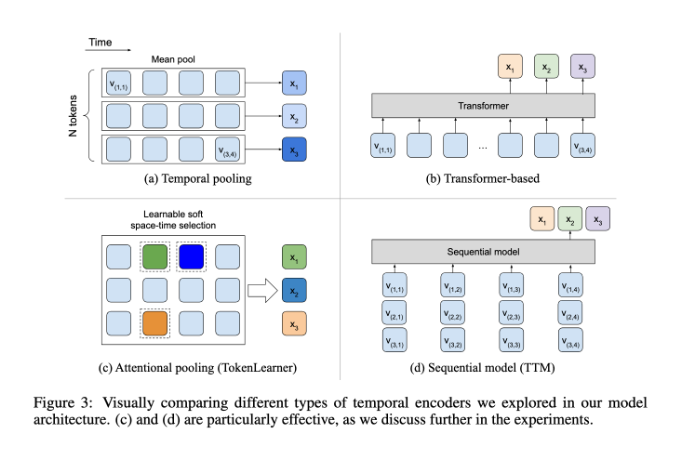
À cet égard, BLIP-3-Video fonctionne plutôt bien. Ce modèle réduit avec succès la quantité d'informations visuelles requises dans la vidéo à 16 à 32 marqueurs visuels en introduisant un « encodeur temporel ». Cette conception innovante améliore considérablement l’efficacité informatique, permettant au modèle d’effectuer des tâches vidéo complexes à moindre coût. Cet encodeur temporel utilise un mécanisme de regroupement d'attention spatio-temporelle apprenable qui extrait les informations les plus importantes de chaque image et les intègre dans un ensemble compact de marqueurs visuels.
BLIP-3-Video fonctionne également très bien. En comparant avec d'autres modèles à grande échelle, l'étude a révélé que la précision de ce modèle dans les tâches de réponse vidéo aux questions est comparable à celle des meilleurs modèles. Par exemple, le modèle Tarsier-34B nécessite 4 608 marqueurs pour traiter 8 images vidéo, tandis que BLIP-3-Video n'a besoin que de 32 marqueurs pour atteindre un score de référence MSVD-QA de 77,7 %. Cela montre que BLIP-3-Video réduit considérablement la consommation de ressources tout en conservant des performances élevées.
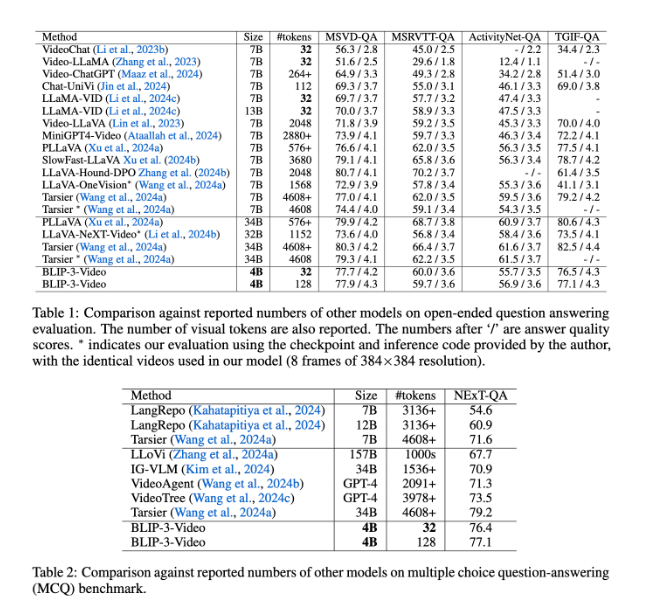
De plus, les performances de BLIP-3-Video dans les tâches de questions et réponses à choix multiples ne peuvent être sous-estimées. Dans l'ensemble de données NExT-QA, le modèle a atteint un score élevé de 77,1 %, et dans l'ensemble de données TGIF-QA, il a également atteint une précision de 77,1 %. Ces données démontrent l'efficacité de BLIP-3-Video dans la gestion de problèmes vidéo complexes.

BLIP-3-Video ouvre de nouvelles possibilités dans le traitement vidéo grâce à son encodeur de synchronisation innovant. Le lancement de ce modèle améliore non seulement l'efficacité de la compréhension vidéo, mais offre également davantage de possibilités pour les futures applications vidéo.
Entrée du projet : https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
BLIP-3-Video offre une nouvelle direction pour le développement futur de la technologie vidéo grâce à ses capacités de traitement vidéo efficaces. Ses excellentes performances dans les tâches de questions et réponses vidéo et de questions et réponses à choix multiples démontrent son énorme potentiel en matière d’économie de ressources et d’amélioration des performances. Nous sommes impatients de voir BLIP-3-Video jouer un rôle dans davantage de domaines et promouvoir l'avancement de la technologie vidéo.