L'artefact d'efficacité de la recherche scientifique OpenScholar est publié, changeant complètement l'expérience de revue de la littérature des chercheurs scientifiques ! L'éditeur de Downcodes vous propose cet outil de recherche scientifique basé sur l'IA. Il contient 450 millions d'articles en libre accès et 237 millions d'intégrations de paragraphes d'articles. Il peut filtrer rapidement et avec précision les documents liés à vos questions de recherche scientifique et générer des réponses complètes aux références. OpenScholar n'est pas seulement puissant, il peut également apprendre et s'améliorer, améliorer continuellement la qualité des réponses et, finalement, présenter les résultats de recherche scientifique les plus parfaits. Il peut également être utilisé pour entraîner des modèles plus petits et plus efficaces, apportant des changements révolutionnaires dans le domaine de la recherche scientifique !
Vous veillez tard pour examiner la littérature ? Vous grattez la tête et rédigez un article ? Ne paniquez pas ! Les experts en recherche scientifique d'AI2 sont là pour vous sauver avec leur dernier chef-d'œuvre OpenScholar. Cet artefact d'efficacité de la recherche scientifique peut rendre la révision de la littérature aussi simple et agréable ! comme se promener dans le parc !
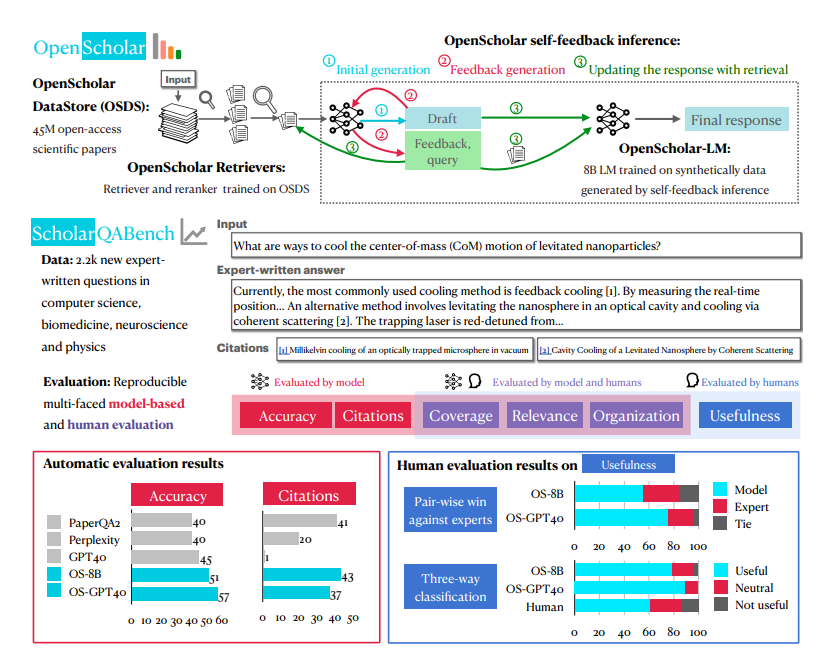
La plus grande arme secrète d'OpenScholar est un système appelé OpenScholar-Datastore (OSDS) avec 450 millions d'articles en libre accès et 237 millions de paragraphes d'articles intégrés. Avec une base de connaissances aussi solide, OpenScholar peut facilement résoudre divers problèmes de recherche scientifique.
Lorsque vous rencontrez un problème de recherche scientifique, OpenScholar enverra d'abord ses outils puissants - le chercheur et le réorganisateur, pour filtrer rapidement les paragraphes d'article liés à votre problème depuis OSDS. Ensuite, un modèle de langage (LM) contient la réponse complète pour la référence. Ce qui est encore plus puissant, c'est qu'OpenScholar continuera d'améliorer les réponses en fonction de vos commentaires en langage naturel et de compléter les informations manquantes jusqu'à ce que vous soyez satisfait.
OpenScholar est non seulement puissant en soi, mais peut également aider à former des modèles plus petits et plus efficaces. Les chercheurs ont utilisé le processus d'OpenScholar pour générer des quantités massives de données de formation de haute qualité, et ont utilisé ces données pour former un modèle de langage de 8 milliards de paramètres appelé OpenScholar-8B, ainsi que d'autres modèles de récupération.
Afin de tester de manière exhaustive l'efficacité au combat d'OpenScholar, les chercheurs ont également spécialement créé une nouvelle arène de test appelée SCHOLARQABENCH. Une variété de tâches d'analyse de la littérature scientifique sont mises en place dans ce domaine, notamment la classification fermée, les choix multiples et la génération de formulaires longs, couvrant plusieurs domaines tels que l'informatique, la biomédecine, la physique et les neurosciences. Afin de garantir l'équité et la justice de la concurrence, SCHOLARQABENCH utilise également des méthodes d'évaluation à multiples facettes, notamment l'examen par des experts, des indicateurs automatiques et des tests d'expérience utilisateur.
Après de nombreuses séries de compétitions acharnées, OpenScholar s'est finalement démarqué ! Les résultats expérimentaux ont montré qu'il fonctionnait bien dans diverses tâches, surpassant même les experts humains. Ce résultat révolutionnaire déclenchera sûrement une révolution dans le domaine de la recherche scientifique et permettra aux scientifiques de dire au revoir au dur ! un travail de revue de la littérature, axé sur l'exploration des mystères de la science !
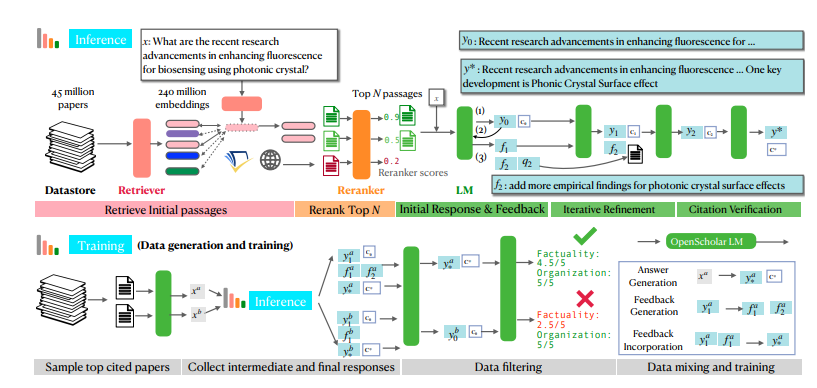
Les fonctions puissantes d’OpenScholar bénéficient principalement de son mécanisme de raisonnement amélioré unique de récupération d’auto-rétroaction. Pour faire simple, il se posera d'abord des questions, puis améliorera continuellement les réponses en fonction de ses propres réponses, et enfin vous présentera la réponse la plus parfaite. N'est-ce pas incroyable ?
Plus précisément, le processus de raisonnement par auto-évaluation d'OpenScholar est divisé en trois étapes : la génération de réponses initiales, la génération de commentaires et l'intégration des commentaires. Tout d’abord, le modèle linguistique génère une réponse initiale basée sur les passages d’articles récupérés. Ensuite, comme un examinateur sévère, il autocritiquera ses réponses, identifiera les lacunes et générera des commentaires en langage naturel, tels que « La réponse ne contient que des résultats expérimentaux sur les tâches de questions et réponses, veuillez compléter d'autres types de résultats de tâches ». . Enfin, le modèle linguistique effectuera une recherche dans la littérature pertinente sur la base de ces commentaires et intégrera toutes les informations pour générer une réponse plus complète.
Afin de former des modèles plus petits mais tout aussi puissants, les chercheurs ont également utilisé le processus d'inférence d'auto-rétroaction d'OpenScholar pour générer de grandes quantités de données de formation de haute qualité. Ils ont d'abord sélectionné les articles les plus cités dans la base de données, puis généré des questions de requête d'informations basées sur les résumés de ces articles, et enfin utilisé le processus d'inférence d'OpenScholar pour générer des réponses de haute qualité. Ces réponses et les informations de retour générées au cours du processus constituent des données de formation précieuses. Les chercheurs ont mélangé ces données avec les données de réglage fin des instructions générales existantes et les données de réglage fin des instructions scientifiques pour former un modèle de langage de 8 milliards de paramètres appelé OpenScholar-8B.
Pour évaluer plus complètement les performances d'OpenScholar et d'autres modèles similaires, les chercheurs ont également créé une nouvelle référence appelée SCHOLARQABENCH. Ce benchmark contient 2 967 questions de revue de la littérature rédigées par des experts couvrant quatre domaines : l'informatique, la physique, la biomédecine et les neurosciences. Chaque question a une longue réponse rédigée par un expert, et en moyenne, chaque réponse prend environ une heure à un expert. SCHOLARQABENCH utilise également une approche d'évaluation à multiples facettes qui combine des mesures automatisées et une évaluation manuelle pour fournir une mesure plus complète de la qualité des réponses générées par le modèle.
Les résultats expérimentaux montrent que les performances d'OpenScholar sur SCHOLARQABENCH dépassent de loin les autres modèles et dépassent même les experts humains dans certains aspects. Par exemple, dans le domaine de l'informatique, le taux de correction d'OpenScholar-8B est 5 % plus élevé que celui de GPT-4o, qui est 5 % plus élevé ! que celui de GPT-4o est 7 % plus élevé. De plus, la précision des citations des réponses générées par OpenScholar est comparable à celle des experts humains, tandis que GPT-4o atteint 78 à 90 % de toutes pièces.
L’émergence d’OpenScholar est sans aucun doute une grande aubaine pour le domaine de la recherche scientifique. Elle peut non seulement aider les chercheurs scientifiques à économiser beaucoup de temps et d’énergie, mais également à améliorer la qualité et l’efficacité des revues de littérature ! Je crois que dans un avenir proche, OpenScholar deviendra un assistant indispensable pour les chercheurs scientifiques !
Adresse papier : https://arxiv.org/pdf/2411.14199
Adresse du projet : https://github.com/AkariAsai/OpenScholar
Dans l’ensemble, grâce à ses fonctions puissantes et à ses performances efficaces, OpenScholar a apporté une commodité sans précédent aux chercheurs scientifiques et a considérablement amélioré l’efficacité de la recherche scientifique. Il ne s’agit pas seulement d’un outil, mais aussi d’une révolution dans le domaine de la recherche scientifique. Il vaut la peine d’attendre avec impatience son développement et ses applications futures.