L'éditeur de Downcodes vous expliquera les derniers résultats de recherche de l'Université de Princeton et de l'Université de Yale ! Cette recherche explore en profondeur les capacités de raisonnement « Chaîne de pensée (CoT) » des grands modèles de langage (LLM), révélant que le raisonnement CoT n'est pas une simple application de règles logiques, mais une fusion complexe de multiples facteurs tels que la mémoire, la probabilité et raisonnement sur le bruit. Les chercheurs ont sélectionné la tâche de craquage du chiffrement par décalage et ont mené une analyse approfondie de trois LLM : GPT-4, Claude3 et Llama3.1. Enfin, ils ont découvert trois facteurs clés qui affectent l'effet d'inférence CoT et ont proposé le mécanisme d'inférence du LLM. de nouvelles perspectives.
Des chercheurs de l'Université de Princeton et de l'Université de Yale ont récemment publié un rapport sur les capacités de raisonnement « Chaîne de pensée (CoT) » des grands modèles de langage (LLM), révélant le secret du raisonnement CoT : il ne s'agit pas d'un raisonnement purement symbolique basé sur des règles logiques, mais Il combine plusieurs facteurs tels que la mémoire, les probabilités et le raisonnement sur le bruit.
Les chercheurs ont utilisé le déchiffrement du chiffrement par décalage comme tâche de test et ont analysé les performances de trois LLM : GPT-4, Claude3 et Llama3.1. Un chiffre par décalage est un codage simple dans lequel chaque lettre est remplacée par une lettre décalée d'un nombre fixe de places dans l'alphabet. Par exemple, avancez l’alphabet de 3 places et CAT devient FDW.
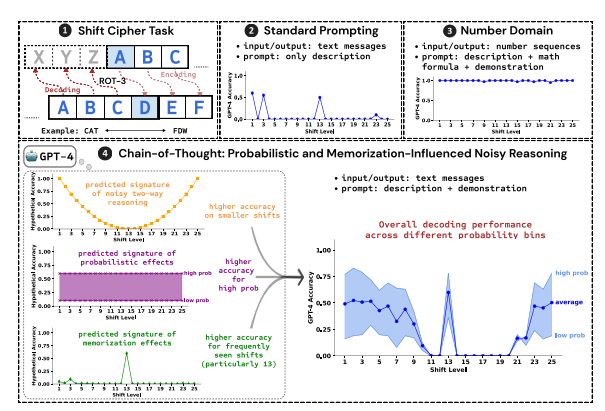
Les résultats de la recherche montrent que les trois facteurs clés affectant l’effet de raisonnement CoT sont :
Probabiliste : LLM préfère générer des résultats à probabilité plus élevée, même si les étapes d'inférence conduisent à des réponses à probabilité plus faible. Par exemple, si l'étape d'inférence pointe vers STAZ, mais que STAY est un mot plus courant, LLM peut « s'auto-corriger » et afficher STAY.
Mémoire : LLM mémorise une grande quantité de données textuelles pendant la pré-entraînement, ce qui affecte la précision de son inférence CoT. Par exemple, rot-13 est le chiffrement par décalage le plus courant, et la précision du LLM sur rot-13 est nettement supérieure à celle des autres types de chiffrements par décalage.
Inférence de bruit : le processus d'inférence de LLM n'est pas complètement précis, mais il existe un certain degré de bruit. À mesure que la quantité de décalage du chiffrement par décalage augmente, les étapes intermédiaires requises pour le décodage augmentent également et l'impact de l'inférence du bruit devient plus évident, entraînant une diminution de la précision du LLM.
Les chercheurs ont également découvert que le raisonnement CoT de LLM repose sur l’autoconditionnement, c’est-à-dire que LLM doit générer explicitement du texte comme contexte pour les étapes de raisonnement ultérieures. Si le LLM doit « penser en silence » sans produire de texte, sa capacité de raisonnement est considérablement réduite. De plus, l'efficacité des étapes de démonstration a peu d'impact sur le raisonnement CoT. Même s'il y a des erreurs dans les étapes de démonstration, l'effet de raisonnement CoT du LLM peut rester stable.
Cette étude montre que le raisonnement CoT de LLM n'est pas un raisonnement symbolique parfait, mais intègre plusieurs facteurs tels que le raisonnement de mémoire, de probabilité et de bruit. LLM montre les caractéristiques d'un maître de mémoire et d'un maître de probabilité pendant le processus de raisonnement CoT. Cette recherche nous aide à mieux comprendre les capacités de raisonnement de LLM et fournit des informations précieuses pour développer des systèmes d’IA plus puissants à l’avenir.
Adresse papier : https://arxiv.org/pdf/2407.01687
Ce rapport de recherche nous fournit une référence précieuse pour comprendre le mécanisme de raisonnement de la « chaîne de pensée » des grands modèles de langage, et fournit également une nouvelle orientation pour la conception et l'optimisation des futurs systèmes d'IA. L'éditeur de Downcodes continuera à prêter attention aux développements de pointe dans le domaine de l'intelligence artificielle et à vous proposer des contenus plus passionnants !